我们介绍了一个基于统计分类的对话系统,该系统用于在协作导航领域实现人机对话自动化。分类器是在一个小型的多层 Wizard-of-Oz 对话语料库中训练的,其中包括两个向导:一个代表对话能力,另一个代表导航能力。下面,我们将介绍分类器的实现细节,并展示如何将其用于自动对话向导。我们在语料库中的几组源数据上评估了我们的系统,发现即使使用非常有限的训练数据,响应准确率也普遍很高。这项工作的另一个贡献是新颖地展示了对话管理器,它使用分类器与两个不同的人类角色进行多楼层对话。总之,这种方法有助于口语对话系统对自然语言输入做出稳健而准确的回应,也有助于需要在团队环境中与人类互动的机器人。
动机与当前工作
我们目前正在开发一个端到端口语对话系统,用于人机协作导航领域。该系统在涉及双 WoZ 设置的小型语料库上进行训练,其中一个向导负责对话管理(DM),另一个向导负责机器人导航(RN)。使用这种语料库的理由是,我们希望系统能以适当的、类似人类的方式解释语音并做出反应。这种方法提供了数据驱动的见解,让我们了解在协作导航任务的背景下,这样的回应会是什么,以及我们应该期待什么样的回应。我们的最终目标是创造一个完全自主的机器人。在本文中,我们介绍了利用基于跨语言信息检索的统计分类器实现自然语言对话功能自动化的初步尝试。该系统跨多个楼层(即不同的通信渠道)运行,"翻译 "人类用户与 RN 组件或向导之间的信息,并向人类用户提供积极和消极的反馈。
鉴于我们的语料库规模较小,我们有兴趣探索一下,利用如此有限的训练数据和注释,我们能在多大程度上采用数据驱动方法。大多数端到端系统需要大量的训练集才能获得合理的性能,但之前对类似分类器的评估显示,与其他系统(如 [20])所需的数十万条训练数据相比,我们只用了几百条语料就获得了相当高的准确率 [9]。请注意,我们并不是说我们的方法可以避免其他数据驱动系统的局限性,我们将在第 5 节中讨论其中的一些局限性。然而,我们的目标是通过我们的分类和 DM 方法来减轻其中的一些局限性。
下面,我们将介绍我们的任务领域,并提供所用语料的详细信息。接下来,我们将介绍我们的分类方法以及实施的 DM 策略。最后,我们将在语料库中不同规模的数据集上对我们的系统进行评估,以比较响应的准确性。在评估中,我们将关注以下几点:(1) 分类器的准确性(尤其是与训练数据的大小和组成有关的方面),(2) DM 响应的充分性,以及 (3) 系统在机器人架构中的集成。
人机协作导航任务-任务域
我们的任务领域涉及类似 USAR 场景的协作导航。在任务中,人类担任指挥官,监督远程定位的机器人在一个陌生的物理环境中执行导航任务。该环境以房屋为模型,包括各种房间和与该环境类型一致的物体(房间、走廊等)。任务的目标是团队合作完成两项子任务--一项与搜索有关(如寻找鞋子),另一项与分析有关(如评估该区域是否可用作总部)。
在整个任务过程中,指挥官都坐在电脑前,电脑界面显示与任务相关的信息。界面包括显示机器人位置的二维占位网格、机器人拍摄的最后一张图像快照,以及显示机器人对话回复的文本框(见图 1 右上方)。为了指挥机器人,指挥官可以使用不受约束的自然语言自由发言。常见的指令包括 "向前移动 10 英尺"、"拍照 "和 "右转 45◦"。人们也会使用基于地标的指令,如 "移动到黄色圆锥体前 "和 "到你右边的门口去",不过这些指令不如基于度量的指令那么常见[15]。
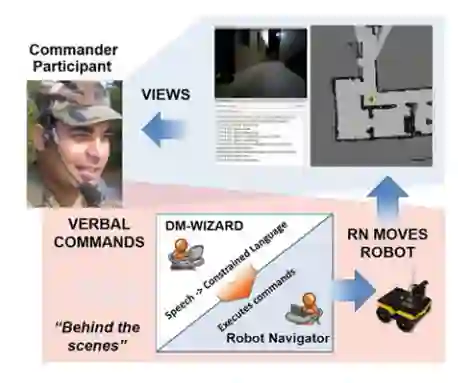
图 1 具有双向导设置的实验任务域(摘自 [13] )。
任务使用双 WoZ 设置运行,其中一个向导控制 DM,另一个向导控制 RN。重要的是,向导之间必须相互通信,以确保正确及时地执行操作和做出响应[14]。该任务已进行了多次实验,其他实验目前正在进行中。在实验(Exp.)1 中,DM 向导根据预先制定的指南(见 [13]),向指挥官和 RN 向导自由输入回复。在此基础上,我们开发了一个图形用户界面,供 DM 向导在实验 2 中使用,以提供更快、更统一的回复[2, 16]。在实验 3 中,我们使用了相同的图形用户界面,但这里我们使用的是模拟机器人和环境,而不是物理环境。实验 1 和实验 2 各有 10 名参与者,而实验 3 则有 62 名参与者。