丹麦奥胡斯大学等最新《高效高分辨率深度学习》综述,全面阐述高效高分辨率深度学习方法,非常值得关注!

智能手机、卫星和医疗设备等现代设备中的相机能够捕捉非常高分辨率的图像和视频。此类高分辨率数据通常需要通过深度学习模型进行处理,用于癌症检测、自动道路导航、天气预测、监测、优化农业过程和许多其他应用。由于高参数、计算成本、推理延迟和GPU内存消耗大,将高分辨率图像和视频作为深度学习模型的直接输入会带来许多挑战。像将图像调整到较低分辨率这样的简单方法在文献中很常见,但它们通常会显著降低精度。文献中的一些工作提出了更好的替代方案,以应对高分辨率数据的挑战,提高精度和速度,同时遵守硬件限制和时间限制。本综述介绍了这些高效的高分辨率深度学习方法,总结了高分辨率深度学习在现实世界中的应用,并提供了现有高分辨率数据集的全面信息。
https://www.zhuanzhi.ai/paper/f70e86bd36f853e9e2f1b8e3d3257954
概述
许多现代设备,如智能手机、无人机、增强现实头盔、车辆和其他物联网(IoT)设备都配备了高质量的相机,可以捕捉高分辨率的图像和视频。在图像拼接技术、相机阵列[1]、[2]、十亿像素采集机器人[3]和全切片扫描仪[4]的帮助下,捕获分辨率可以提高到数十亿像素(通常称为十亿像素),如图1所示的图像。人们可以尝试根据人类视觉系统的能力来定义高分辨率。然而,许多深度学习任务依赖于设备捕获的数据,这些设备的行为与人眼非常不同,如显微镜、卫星图像和红外相机。此外,利用眼睛无法感知的更多细节在许多深度学习任务中是有益的,例如在第二节中讨论的应用。可以捕获并在处理时有用的细节量因任务而异。因此,高分辨率的定义与进程有关。例如,在图像分类和计算机断层扫描(CT)扫描处理中,512×512像素的分辨率被认为是高[5],[6]。在视觉人群计数中,高分辨率(HD)或更高分辨率的数据集常见[7],而在组织病理学中研究组织疾病的全切片图像(WSIs),或由飞机或卫星捕获的遥感数据,很容易达到十亿像素分辨率[8]、[9]。
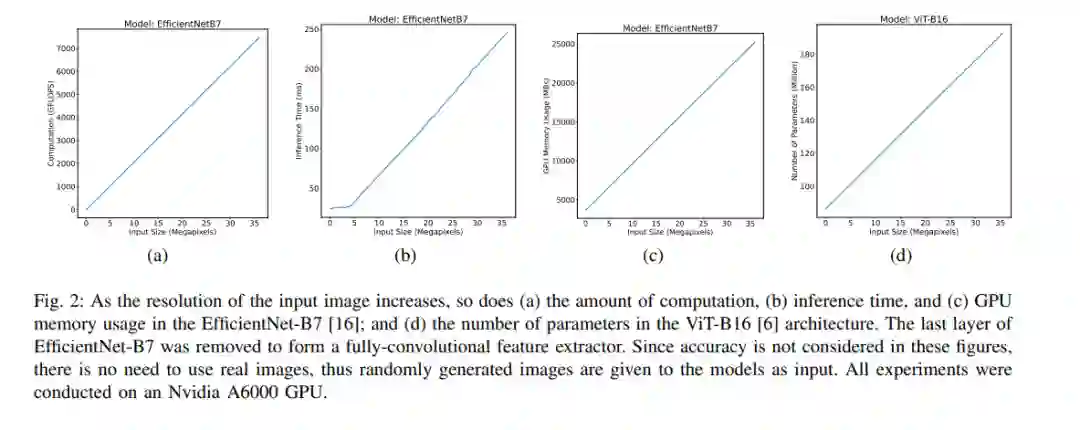
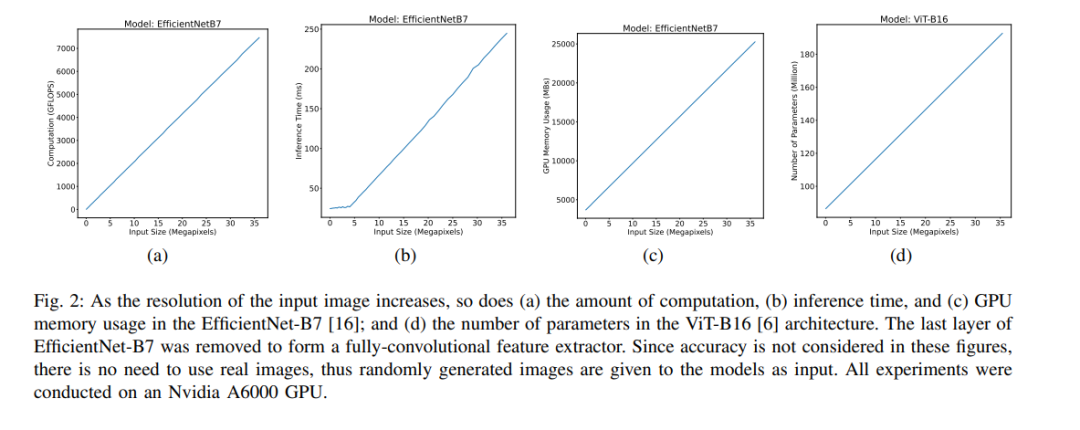
此外,随着硬件和方法的不断进步,深度学习文献认为的高分辨率已经随着时间发生了变化。例如,在20世纪90年代末,用神经网络处理32×32-pixel MNIST图像是一项成就,而在2010年代初,ImageNet中的256×256-pixel图像被认为是高分辨率[11]。在流行的深度学习数据集如人群计数[7]和异常检测[12]数据集上,图像平均分辨率的持续提升也可以看出这一趋势。因此,高分辨率的定义也与周期有关。根据任务和周期依赖特性,“高分辨率”一词显然是技术性的,而不是基本的或普遍的。因此,在撰写本文时,我们将重点转移到对深度学习造成技术挑战的解决方案上,而不是试图得出这样的定义。将高分辨率图像和视频直接作为深度学习模型的输入,在训练和推理阶段都存在挑战。除了全卷积网络(FCNs),深度学习模型中的参数数量通常随着输入规模的增加而增加。此外,通常以浮点操作(FLOPs)来衡量的计算量,以及推理/训练时间,以及GPU内存消耗,都随着更高分辨率的输入而增加,如图2所示。这个问题在视觉Transformer (ViT)架构中尤其严重,这些架构使用自注意力机制,其中推理速度和参数数量与输入大小[6],[15]呈二次增长。当需要在资源受限的设备(如智能手机)上进行训练或推理时,这些问题会加剧,与工作站或服务器等高端计算设备相比,智能手机的计算能力有限。

尽管在训练[17]、[18]和推理[19]阶段,可以使用模型并行等方法在多个GPU之间分割模型,从而避免内存和延迟问题,但这些方法需要大量的资源,如大量的GPU和服务器,这可能会导致很高的成本,特别是在处理十亿像素图像等极端分辨率时。此外,在许多应用中,如自动驾驶汽车和无人机图像处理,可以安装的硬件是有限的,并且将计算卸载到外部服务器并不总是可能的,因为移动和应用程序的时间关键性导致网络连接不可靠。因此,深度学习训练和推理最常见的方法是在每个GPU实例上加载完整的模型。相反,多GPU设置通常用于通过增加总体批大小来加速训练,以并行测试多组超参数或分配推理负载。因此,在许多情况下,深度学习模型可以处理有效的最大分辨率。例如,使用SASNet[14]进行推理的最大分辨率(在撰写本文时,它是上海科技数据集[20]上最先进的人群计数模型)在具有11 GBs显存的Nvidia 2080 Ti GPU上约为1024×768(低于高清)。
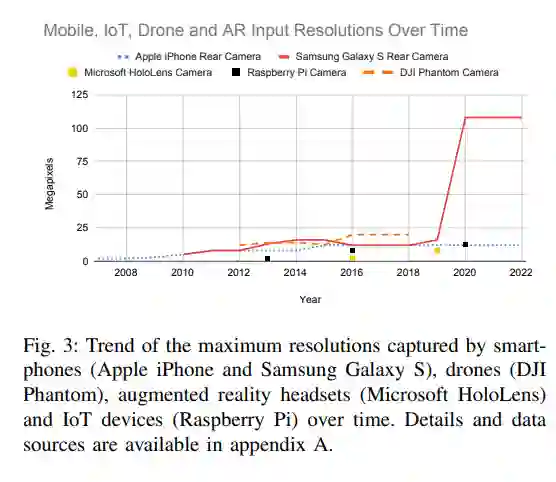
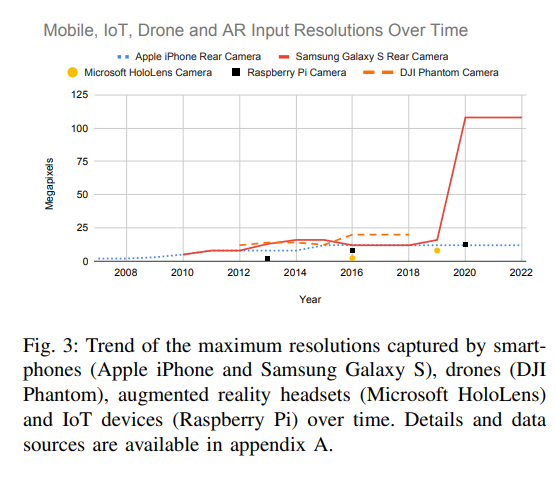
虽然新一代的GPU越来越快,内存也越来越多,但设备捕获的图像和视频的分辨率也在提高。图3显示了近年来多种类型设备的这种趋势。因此,即使在计算硬件技术进步的情况下,上述问题也可能会持续存在。此外,目前的成像技术还远没有达到图像分辨率的物理极限,估计在petapixels[21]。捕获和处理更高的分辨率是否会带来改进取决于手头的特定问题。例如,在图像分类中,将物体或动物图像的分辨率提高到十亿像素不太可能揭示更多有益的细节并提高准确性。另一方面,如果目标是计算场景中的总人数,如图1所示,使用高清分辨率而不是十亿像素意味着可以用一个像素表示多个人,这将大大增加误差。同样,在组织病理学中使用更高的分辨率可以导致更好的结果[22]。
假设由于硬件限制或延迟要求,对于特定问题存在有效的最大分辨率,有两种简单的基线方法用于处理原始捕获的输入,这在深度学习文献[23]-[25]中常用。这些基线的流行可以归因于它们实现的简单性。第一种方法是调整原始输入的大小(下采样)到所需的分辨率,然而,如果丢失了手头问题的任何重要细节,这将导致较低的精度。这种方法被称为统一下采样(UD),因为整个图像的质量是统一降低的。第二种方法是将原始输入分割成每个具有最大分辨率的小块,独立处理这些小块,并聚合结果,例如,通过对回归问题进行汇总,对分类问题进行多数投票。我们称这种方法为切块(CIP)。这种方法有两个问题。首先,许多深度学习模型依赖于全局特征,这些特征将丢失,因为从每个补丁中提取的特征不会与其他补丁共享,导致准确性下降。例如,人群计数方法通常严重依赖透视或照明[7]等全局信息,在物体检测中,边界附近的物体可能被分割到多个补丁中。其次,由于执行了多次推理,即每个补丁一次,推理将花费更长的时间。当补丁重叠时,这个问题会更严重。
为了强调这些问题,在Shanghai Tech Part B数据集[20]上测试了两种基线方法(UD和CIP),用于人群计数,其中包含大小为1024×768像素的图像。将原始图像大小减小4和16倍,并测量两个基线的平均绝对误差(MAE)。为了测试UD,我们采用了在Shanghai Tech Part B数据集[20]上预训练的SASNet模型[14],输入大小为1024×768,并使用AdamW优化器[26]针对目标输入大小进行微调,学习率为10−5,权重衰减为10−4。请注意,原始的SASNet论文使用Adam优化器[27],学习率为10−5。我们使用3×Nvidia A6000 GPU对模型进行了100个epoch的训练,每个GPU实例的批大小为12。我们根据经验发现,微调并不能提高切割成块的准确性,因此,我们将原始图像切割成4和16个块,并使用上述预训练的SASNet获得每个块的计数,然后通过对每个块的预测计数求和来聚合结果。
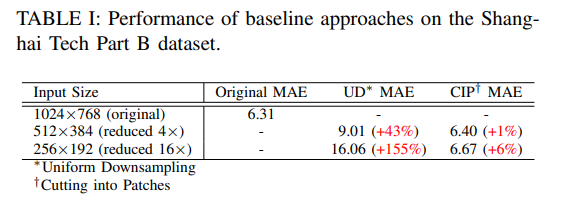
这些实验的结果如表一所示。可以观察到,与处理原始输入大小相比,均匀下采样显著增加了误差。请记住,即使在分割补丁时误差的增加没有那么剧烈,但这种方法的推理时间也增加了相同的因子(即4和16),因为我们假设我们正在使用硬件可能的有效最大分辨率,因此补丁无法并行处理,因为整个硬件需要处理单个补丁。
由于这些基准方法远不是理想的,近年来,文献中提出了几种替代方法,以提高精度和速度,同时遵守由内存限制或速度要求引起的最大分辨率限制。本综述的目的是总结和分类这些贡献。据我们所知,目前还没有关于高分辨率深度学习主题的其他综述。然而,有一些调查包括与此主题相关的方面。在[15]中对降低Transformer架构计算复杂度的方法进行了综述,讨论了自注意力的二次时间和内存复杂度相关问题,并分析了内存占用和计算成本等效率的各个方面。虽然降低Transformer模型的计算复杂度有助于高效处理高分辨率输入,但在本综述中,只包括明确关注高分辨率图像的视觉Transformer方法。一些特定于应用程序的调查包括高分辨率的数据集和操作此类数据的方法。例如,[28]中提供了对组织病理学的深度学习的调查,其中提到了处理WSIs的超大分辨率的挑战;[29]综述了计算机断层扫描(computed tomography, CT)获得更高空间分辨率的方法,重点介绍了超高分辨率CT提高诊断精度的方法,并简要讨论了用于降噪和重建的深度学习方法;对人群计数的研究进行了综述,其中[7]提供了许多可用的高分辨率数据集;在[30]中对面向高分辨率遥感影像的土地覆盖分类和目标检测的深度学习方法进行了综述;在[31]中对基于深度学习的高分辨率遥感图像变化检测方法进行了综述。
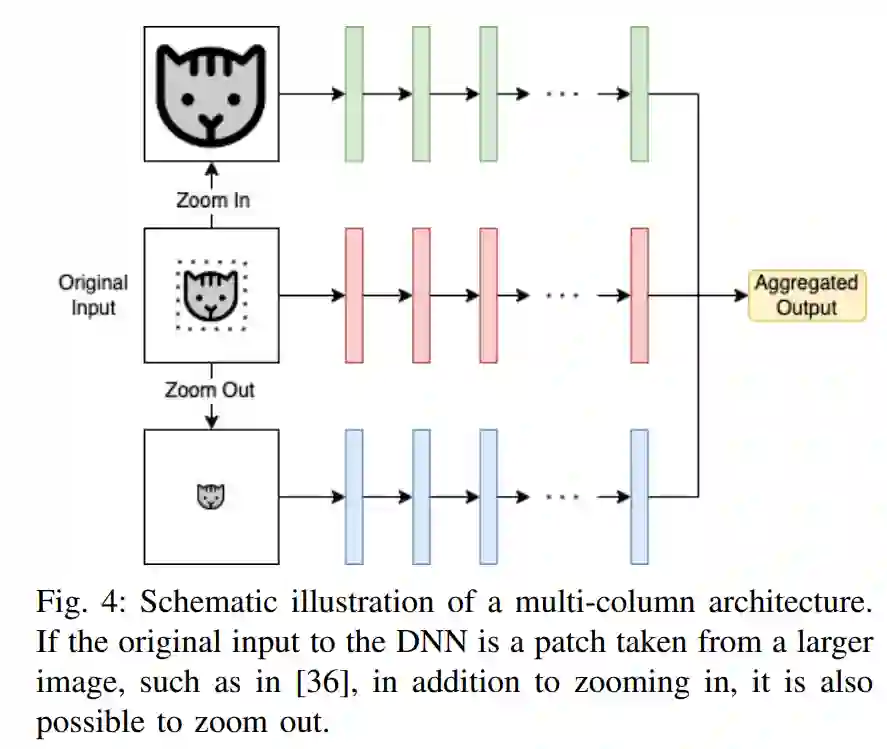
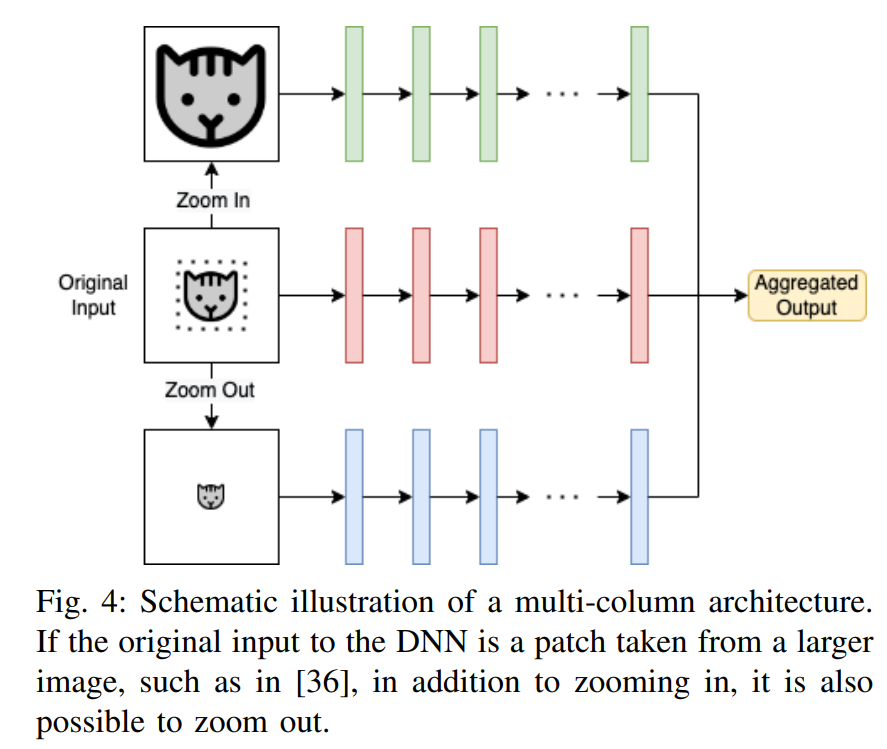
值得一提的是,有些方法在高分辨率输入上运行,但没有努力解决上述挑战。例如,多列(也称为多尺度)网络[7]在其体系结构中合并了多个层列,其中每一列负责处理特定的尺度,如图4所示。然而,由于列处理的分辨率与原始输入相同,与只处理原始尺度的情况相比,这些方法中的大多数实际上需要更多的内存和计算。这些方法的主要目标是通过考虑高分辨率图像中出现的尺度差异来提高精度,尽管也有一些多尺度方法可以同时提高精度和效率[32]-[34]。因此,这些方法不属于本综述的范围,除非它们明确解决高分辨率输入的效率问题。ZoomCount [35], Locality-Aware Crowd Counting [36], RAZ-Net[37]和Learn to Scale[38]都是人群计数中的多尺度方法,以及医学图像处理中的DMMN[39]和KGZNet[40]。
本综述的主要目的是收集和描述深度学习文献中存在的方法,这些方法可以用于输入图像和视频的高分辨率造成上述关于内存、计算和时间的技术挑战的情况。本文的其余部分组织如下:第二节列出了使用深度学习处理高分辨率图像和视频的应用程序。第三节将高分辨率深度学习的有效方法分为五大类,并为每一类提供了一些示例。本节还简要讨论解决高分辨率输入带来的内存和处理时间问题的替代方法。第四节列出了用于各种深度学习问题的现有高分辨率数据集,并提供了每个问题的详细信息。第五节讨论了使用属于不同类别的高效高分辨率方法的优缺点,并就在不同情况下使用哪种方法提供了建议。最后,第六部分总结了高分辨率深度学习的研究现状和趋势,并对未来的研究提出了建议。本综述中进行的实验代码可以在https://gitlab.au.dk/ maleci/high-resolution-deep-learning找到。