

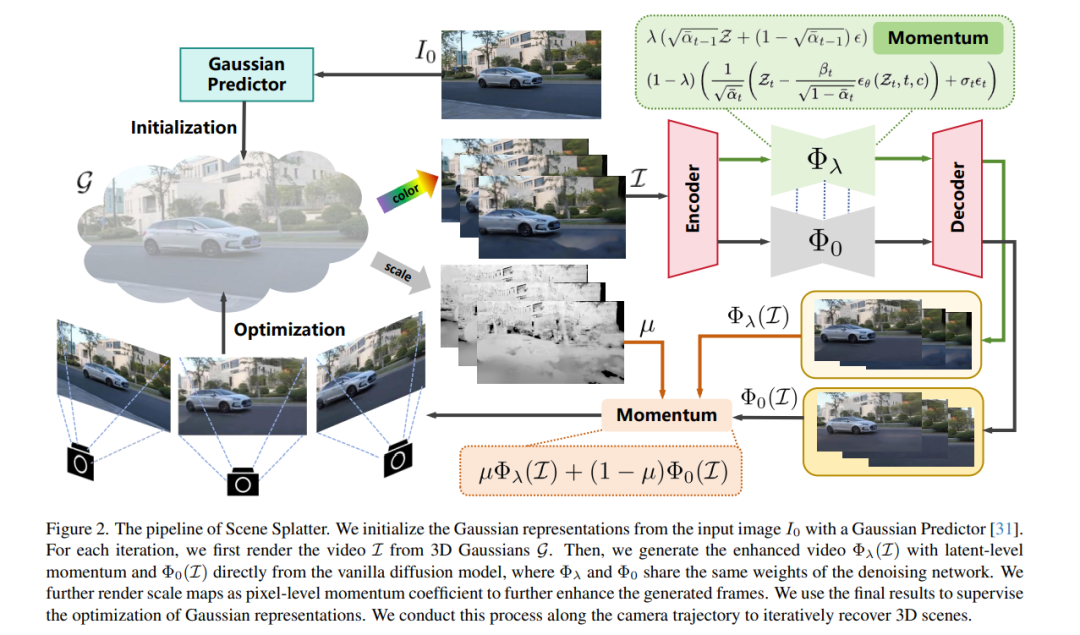
在本文中,我们提出了一种名为 Scene Splatter 的新范式,该方法基于动量机制的视频扩散模型,旨在从单张图像生成通用三维场景。现有方法通常利用视频生成模型合成新视角,但普遍存在视频长度受限与场景一致性差的问题,进而在后续重建过程中容易出现伪影与失真。 为了解决这一问题,我们从原始特征中构造噪声样本,作为“动量”以增强视频细节并保持场景一致性。然而,在感知范围覆盖已知与未知区域的潜在特征(latent features)中,这种基于潜在层的动量会限制扩散模型在未知区域的生成能力。 因此,我们进一步引入上述一致性较强的视频作为像素级动量,将其与不含动量直接生成的视频融合,以更好地恢复未知区域的信息。通过这种级联式动量机制,我们的方法能够引导视频扩散模型生成具有高保真度与一致性的多视角新视频。 此外,我们对全局高斯表示进行微调,结合增强后的帧进行新帧渲染,并用于下一步的动量更新。借助这种方式,我们可实现对三维场景的逐步恢复,突破传统方法在视频长度上的限制。 大量实验结果表明,我们的方法在生成高质量且一致的场景方面表现出良好的泛化能力与领先性能。
成为VIP会员查看完整内容
相关内容
Arxiv
37+阅读 · 2023年4月19日
Arxiv
204+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
140+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
37+阅读 · 2023年4月19日
Arxiv
204+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
140+阅读 · 2023年3月29日