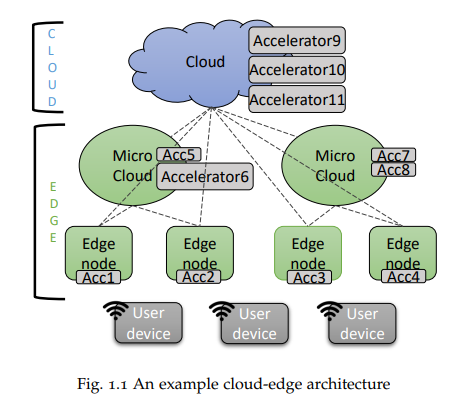
边缘计算的优势在于利用网络边缘的远程计算资源运行相对弱小的终端设备工作负载,而云计算则依托地理位置更远但性能更强大的远程设备提供计算能力。这两大范式的融合可实现优势互补——即某一范式的短板恰为另一范式的强项。以深度学习为例,其工作负载需要大量算力支持,而物联网(IoT)设备等低功耗终端往往无法满足此类需求。通过将任务卸载至云边连续体,算力薄弱的终端可访问强大远程节点的计算资源,其中远程加速器虚拟化技术正是关键实现手段。本论文重点研究基于深度学习推理的GPU加速器虚拟化在云边连续体(涵盖终端设备、边缘节点与云端)中的应用潜力。尽管存在专用机器学习加速器(如张量处理单元TPU),但GPU凭借其普及度、可用性与技术支持成为首选方案。云边计算的异构性(硬件与软件多样性)、延迟约束及节点动态可用性等问题构成了加速器虚拟化的主要挑战,本研究通过三大核心领域贡献实现突破。
首先,论文提出名为AVEC的透明化远程加速器虚拟化框架。通过应用编程接口(API)拦截技术,终端设备运行的应用程序可将原定本地GPU处理的工作负载片段,经网络重定向至配备GPU的远程节点执行。该技术仅卸载GPU内核计算,使得本地CPU持续运行,从而降低终端计算资源压力。本文深入探讨了该框架的架构设计、功能特性与性能表现。
其次,研究探索卸载工作负载在网络节点中的部署方式。相较于虚拟机,容器技术凭借轻量化虚拟化优势更适用于异构云边环境。针对节点动态失效问题,本文提出无状态容器迁移方案,特别适用于深度学习推理任务的连续性保障。
第三,论文建立工作负载调度与部署策略体系。通过制定最优节点选择机制,结合设备性能指标与网络状态参数,实现任务在云边连续体中的智能调度。研究量化分析了设备配置、网络带宽等指标对系统性能的影响,并据此设计启发式调度算法。
AVEC框架的优势体现于轻量化透明虚拟化、特定负载执行时间缩减及多CPU架构兼容性。通过基于Caffe深度学习库的多场景测试,验证其在实验室环境中最高可达7.48倍加速比(相比终端本地执行),同时保持低部署延迟与无缝迁移能力。尽管存在远程虚拟化开销,但性能提升效果显著。
论文结构如下: 第一章 概述研究主题,明确待解决的核心问题与研究目标。
第二章 系统梳理领域前沿文献,揭示当前研究空白及本论文的创新定位。
第三章 阐述相关理论基础,定量化界定研究目标。
第四章 详述基于API拦截的加速器虚拟化框架设计,论证其应对异构性挑战的技术优势。
第五章 通过容器化方案,实现工作负载快速部署与透明实时迁移,阐明功能需求的必要性。
第六章 构建云边环境下的工作负载调度模型,建立基于多维度指标的启发式调度机制。
第七章 通过三组测试案例,验证虚拟化效能、部署迁移性能与调度策略有效性。
第八章 总结研究成果,展望待解决问题与未来研究方向。