
编译 | 曾全晨
审稿 | 王建民
今天为大家介绍的是来自Yejin Kim团队 的一篇关于大型预训练模型应用的论文。大型预训练语言模型(LLMs)已被证明在各个领域的少样本学习中具有重要的潜力,即使是在极少量的训练数据的情况下。然而,它们在更复杂的领域(如生物学)中推广到未见过的任务的能力尚未得到充分评估。LLMs可以通过从文本语料库中提取先前的知识,为生物推理提供有前途的替代方法,特别是在结构化数据和样本量有限的情况下。作者提出的少样本学习方法利用LLMs预测药物组合在缺乏结构化数据和特征的罕见组织中的协同作用。

大型预训练语言模型 (LLM),如GPT-3和GPT-4,已成为基础AI模型的改变者。LLM可以将其技能应用于其从未接受过培训的陌生任务。这部分归功于多任务学习,它使LLM可以无意中从其训练语料库中的隐式任务中获得知识。虽然LLM已经在各个领域,包括自然语言处理、机器人和计算机视觉,展示了它在few-shot learning方面的熟练程度,但LLM对更复杂的生物领域中看不见的任务的普适性尚未得到充分测试。为了推断生物反应,需要参与实体 (例如基因、细胞) 和基础生物机制 (例如通路、遗传背景、细胞环境) 的知识。结构化数据库仅编码了这些知识的一小部分,绝大多数相关知识都存储在自由文献中,这些文献可以用于训练LLM。因此,作者认为在有限的结构化数据和样本大小时,LLM可以通过从非结构化文献中提取先验知识,作为生物预测任务的创新方法。
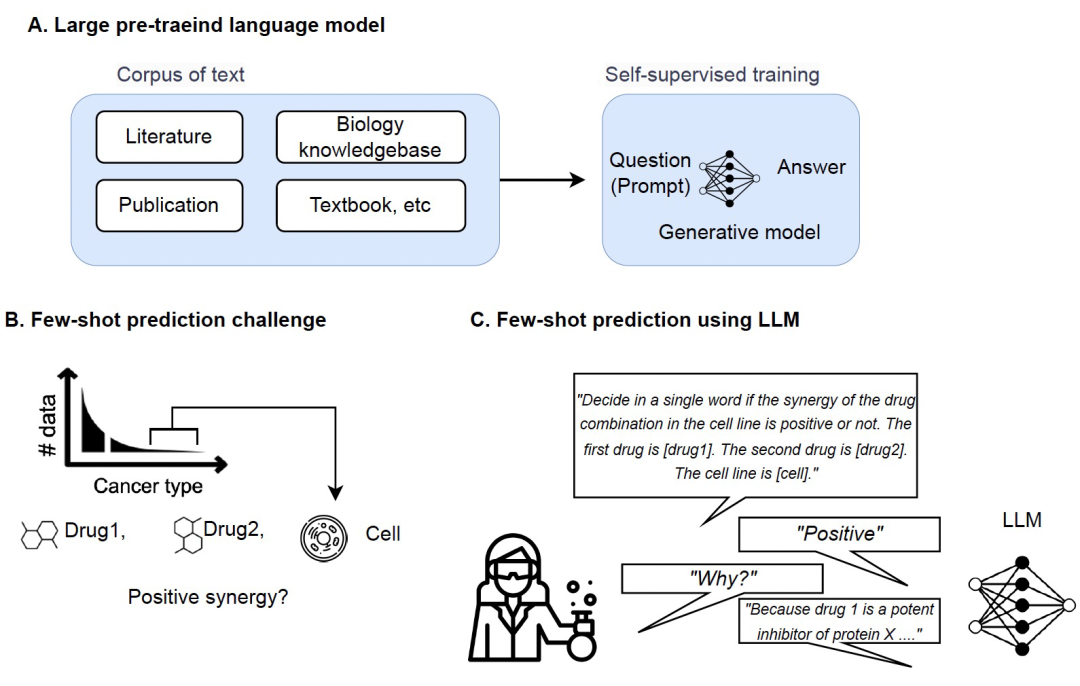
药物组合疗法已成为治疗复杂疾病,如癌症、传染病和神经系统疾病的广泛接受策略。在许多情况下,组合治疗可以比单药治疗提供更好的治疗结果。预测药物配对协同作用已成为药物发现和开发领域的重要研究方向。药物配对协同作用是指在两种(或更多)药物联合使用时,与单独使用每种药物相比,其治疗效果有所增强。药物配对协同作用的预测可能具有挑战性,因为存在大量可能的组合以及复杂的基础生物机制。机器学习算法可以在药物配对的体外实验结果的大型数据集上进行训练,以识别模式并预测新药物配对协同作用的可能性。然而,大部分可用数据来自某些组织中常见的癌症类型,如乳腺癌和肺癌;在某些类型的组织中,如骨骼和软组织中,可用的实验数据非常有限。获得这些组织的细胞系可能在物理上非常困难和昂贵,这限制了用于药物配对协同作用预测的训练数据的数量。这可能会使依赖于大型数据集的机器学习模型的训练具有挑战性。在本文中,作者旨在通过使用LLMs克服上述挑战。作者假设即使在具有有限结构化数据和不一致特征的癌症类型中,科学文献中仍有良好的信息。作者构建了一个Few-shot药物配对协同性预测模型,将预测任务转化为自然语言推理任务,并基于LLMs中编码的先验知识生成答案。实验结果表明,作者的LLM-based Few-shot预测模型即使在零样本情况下(即没有训练数据)也能取得良好的准确率,并在大多数情况下优于强大的表格预测模型。
实验结果
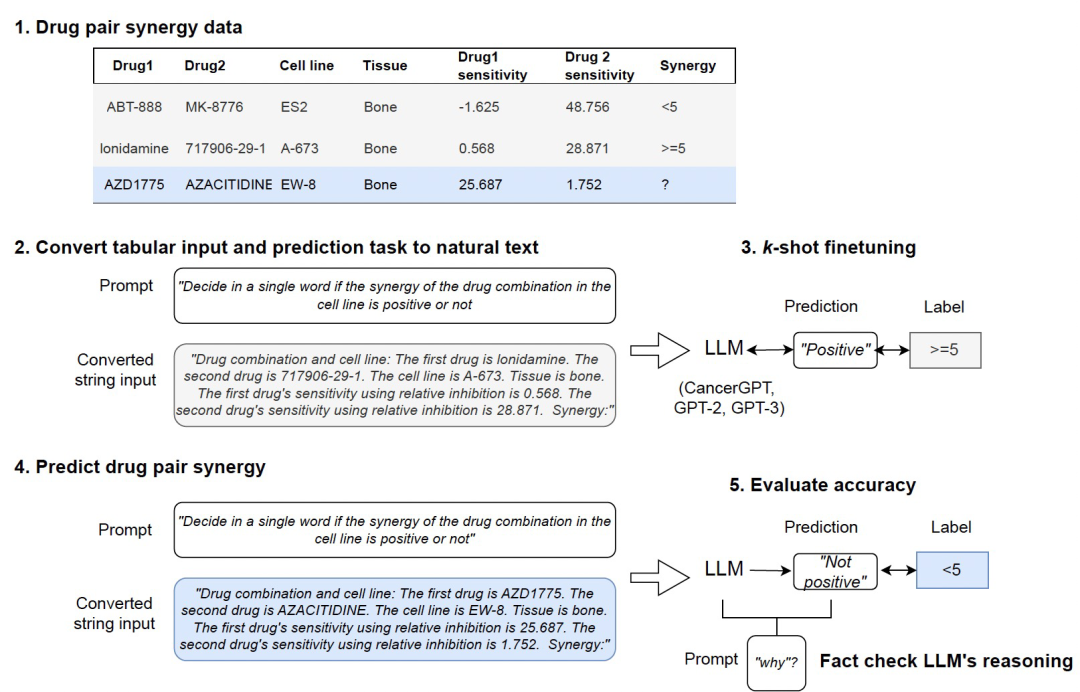
作者开发了CancerGPT,这是一个为罕见组织预测药物对协同作用的few-shot模型(非LLM,仅在常见的组织上预训练过)。作者利用基于LLM的表格数据预测模型将预测任务转化为自然语言推理任务,并利用LLM预训练权重矩阵中编码的科学文献中的先验知识生成答案(上图所示)。为了评估作者提出的CancerGPT模型和其他基于LLM的模型的性能,作者在不同的设置下进行了一系列实验,与各种其他表格模型进行比较。作者考虑了不同的few-shot学习情景,其中模型提供了有限的k个训练数据进行学习(k=0到128)。通过改变样本数量,可以考察模型在最少的训练数据下的适应能力和泛化能力。接下来,作者调查了CancerGPT和其他基于LLM的模型在不同组织类型中的性能。
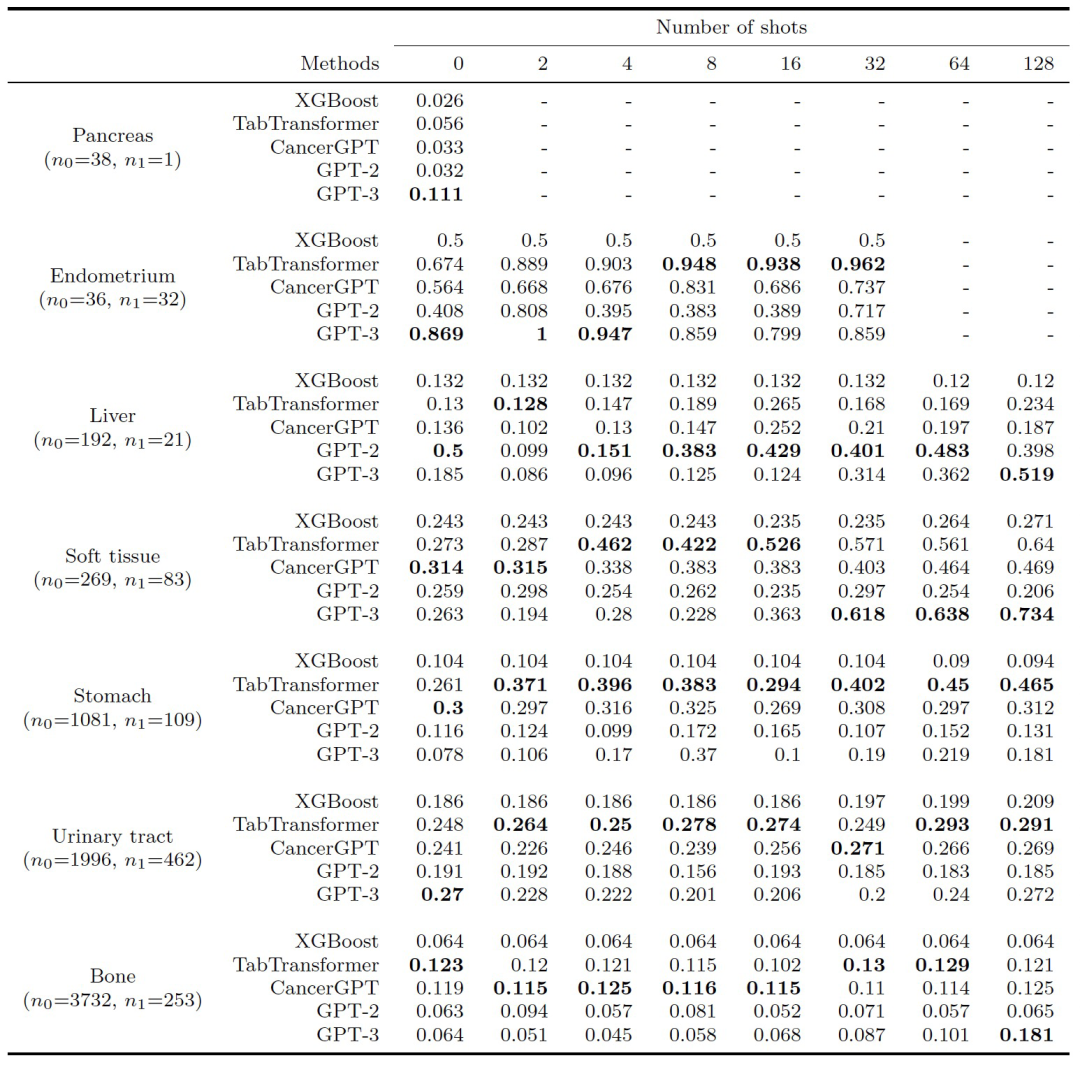
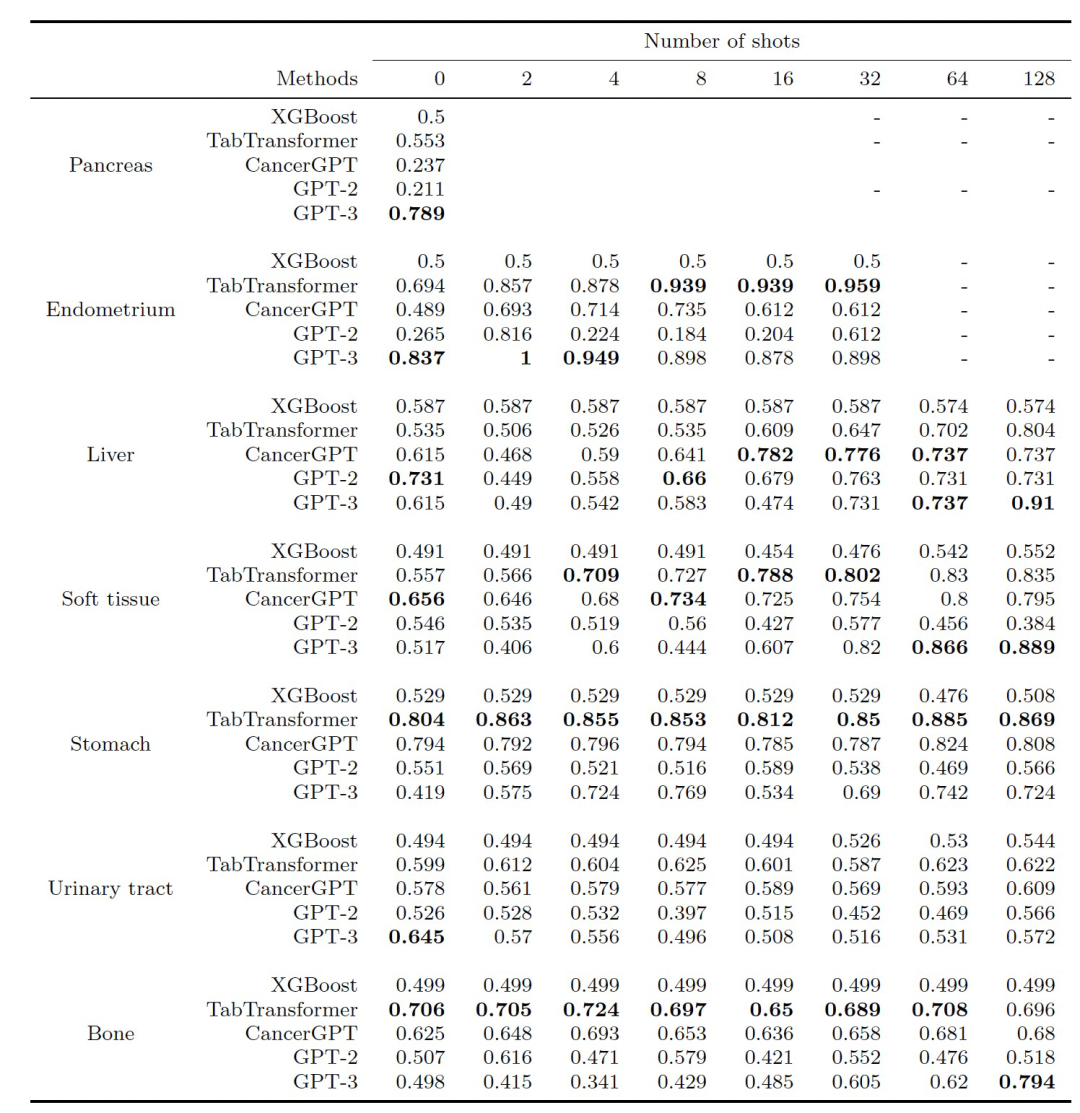
作者评估了协同预测模型的准确性,计算了基于LLM的模型(CancerGPT,GPT-2,GPT-3)和基准模型(XGBoost,TabTransformer)的AUPRC和AUROC(上述两表)。
训练数据数量与准确性:总体而言,在大多数情况下,基于LLM的模型(CancerGPT,GPT-2,GPT-3)在大多数情况下与基线模型相比具有可比或更好的准确性。在零样本的情况下,基于LLM的模型通常比基线模型具有更高的准确性,除了胃和骨骼。随着训练数据量的增加,可以观察到在各种组织和模型中出现了混合的模式。TabTransformer在所有情况下都表现出随着训练数据量增加而增加的准确性。CancerGPT在子宫内膜和软组织中随着训练数据量的增加显示出更高的准确性,而GPT-3在肝脏、软组织和骨骼中随着训练数据量的增加显示出更高的准确性,表明从少量数据中获得的信息补充了编码在CancerGPT和GPT-3中的先验知识。然而,在某些组织中,如胃和泌尿道中,基于LLM的模型有时没有显示出显着的准确性改进,这表明额外的训练数据并不总是提高基于LLM的模型的性能。使用最大数量的样本(k = 128),基于LLM的模型,尤其是GPT-3,在胰腺、肝脏、软组织和骨骼方面的准确性与TabTransformer相当,而TabTransformer在子宫内膜、胃和泌尿道方面的准确性最高。
组织类型和准确性: 模型的准确性因组织类型而异,因为每种组织都具有独特的特征并具有不同的数据大小。在胰腺和子宫内膜组织中,GPT-3只需少量训练数据(k=0或2)即可显示出高准确性。一般来说,这两种组织的细胞系很难获取,并且已建立的细胞系数量有限,这使它们的研究相对较少。例如,胰腺位于腹部深处,很难在不损坏细胞的情况下接触和分离细胞。子宫内膜是一个复杂的组织,在月经周期中经历周期性变化,这一动态过程会使细胞培养变得复杂。由于训练数据有限,这些组织中的少样本药物组合协同预测需要更高的普适性。在肝脏、软组织和骨骼中,GPT-3再次实现了比其他模型更高的准确性,包括使用常见组织训练的模型(TabTransformer,CancerGPT)。这可能是因为这些组织具有特定于其来源组织的独特细胞特征,使用常见组织进行训练可能无法准确预测。另一方面,使用常见组织(TabTransformer,CancerGPT)训练的模型在胃和泌尿道组织的所有k中都实现了最佳准确性,表明从常见组织中学习的预测结果可以推广到这些组织中。特别地,CancerGPT在胃中没有训练样本(k=0)的情况下实现了最高的准确性。
与LLM对比: 在比较基于LLM的模型时,CancerGPT和GPT-3在大多数组织中表现出比GPT-2更高的准确性。在数据有限或具有独特特征的组织中,GPT-3显示出比CancerGPT更高的准确性,而在具有较少独特特征的组织中(例如胃和泌尿道),CancerGPT比GPT-3表现更好。与GPT-2相比,CancerGPT的更高准确性突出了平衡调整对特定任务的影响可以增加准确性同时保持泛化性。然而,在需要更强泛化性的情况下,更大的LLM模型(如GPT-3,175B参数)中进行这种调整的好处可能会减少。CancerGPT使用较小的参数(124M参数)达到与使用较大参数(175B参数)的GPT-3相当的准确性表明,对GPT-3进行进一步微调可以实现更高的准确性。
LLM的推理能力:作者评估了LLM是否能够提供其预测的生物学推理过程。在这个实验中,作者使用了零样本的GPT-3,因为其他微调过的LLM模型在微调期间会影响其语言生成性能。为了做到这一点,作者随机选择了一个真正的阳性预测,并检查其生物学理由是否基于实际证据或仅仅是随机猜想。作者用 “您能详细说明为什么给定癌症类型的细胞系中药物1和药物2具有协同作用吗?”这个问题来提示LLMs。通过与现有的科学文献进行比较来评估生成的答案,作者发现,LLM提供的大多数论据都是准确的。
结论
作者的研究探究了LLMs在生物学领域中作为广泛适用的少样本预测模型的潜力。具体而言,作者提出了一个新的少样本模型,用于预测药物组合协同作用,可用于具有少量或没有训练样本的罕见组织。作者将表格数据预测转换为自然语言推理任务,并使用每种组织中非常少的样本微调LLMs(GPT-2、GPT-3)。CancerGPT模型使用大量常见组织数据进行了预训练,其准确性与少样本微调的GPT-3模型相当,表明将GPT-3定制到特定任务可以进一步提高预测准确性。LLM的推理方式揭示了它通过结合几个已知的科学事实来隐含推断未见过的协同效应。
参考资料 Li, Tianhao, Sandesh Shetty, Advaith Kamath, Ajay Jaiswal, Xian-Wei Jiang, Ying Ding and Yejin Kim. “CancerGPT: Few-shot Drug Pair Synergy Prediction using Large Pre-trained Language Models.” (2023). https://arxiv.org/abs/2304.10946


