
最近在看Yann Lecun 的新作“A Path Towards Autonomous Machine Intelligence”。感觉很受启发,最近深度学习各个大家都相继提出未来人工智能的新框架,可能是现实的确遇到了瓶颈,但也正说明了新的思路正在蕴酿之中。从不同的逻辑出发可以得到不同的结论,关键是你选择哪一个。从Transformer起,我对深度学习的推断能力有了越来越具体的认识,而且我也选择相信它会继续深入下去,直达智能的本质。哪怕它有许多错误,但也是探索中不可跳过的一环。
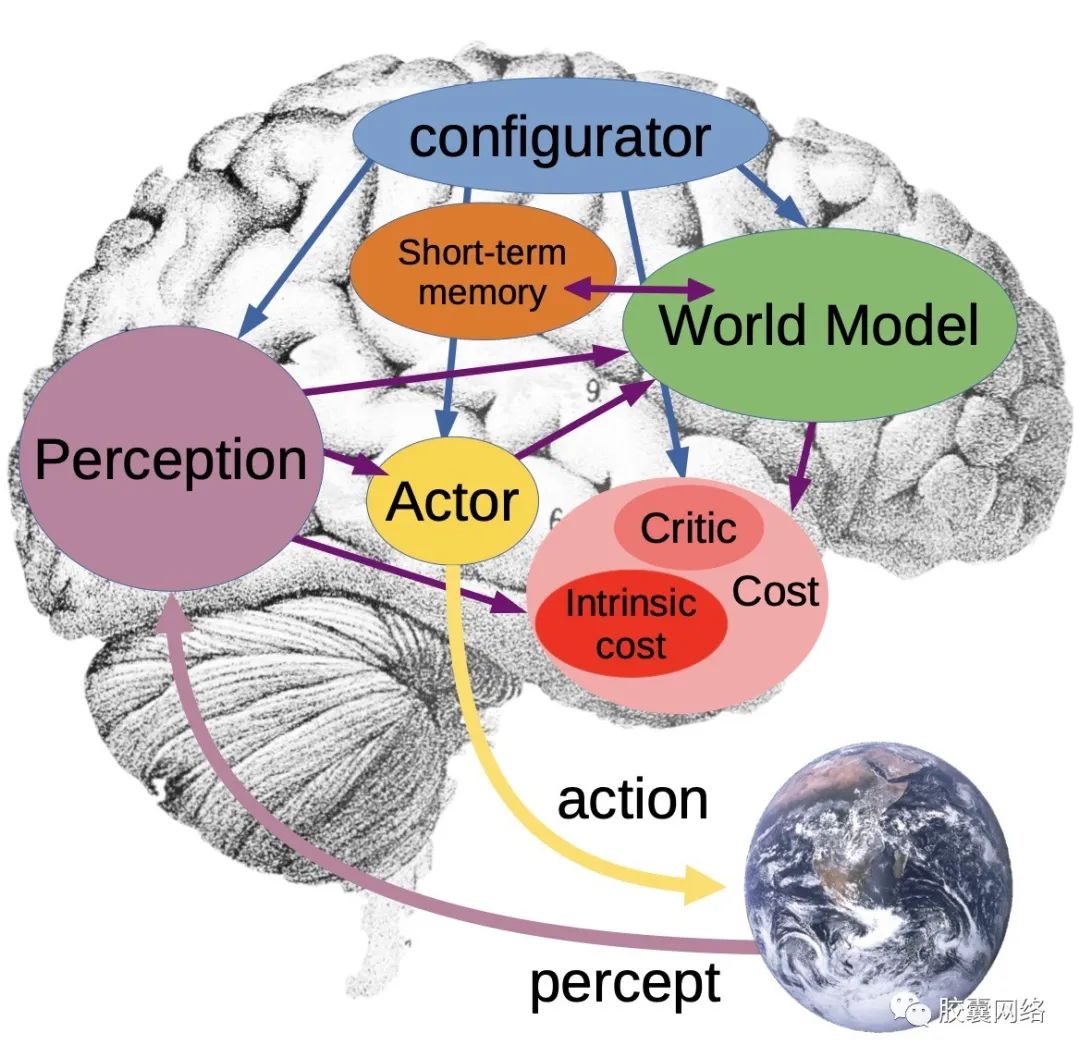
这篇文章的体系很庞大,有30多页,但仍不能覆盖每个细节,只是从整体思路上做了描述。但是里面的内容对今后探索和完善人工智能系统很有指导意义,比如我们在顶会看到的一个新任务,可以跟这个对比一下,看看这个任务所处位置的意义。这个系统的最重要部分是世界模型,它相当于大脑的虚拟引擎,模拟即将要发生的事情,因此我们可以在此基础上训练网络。为了预测即将发生的事情,作者认为可以从视频的预测任务上入手。提出了一个问题:如果给定两张图片,一张图是在分叉路口前的一辆车,一张图是路上的一辆车,我们怎么能推断哪张图先发生,哪张图后发生?对于人来说,这很容易,我们可以猜测第二张图是第一张图选择路口后的照片。但这对机器来说很困难,这是一个Pattern completion问题。
因为这个问题我以前思考过,也是不得其解,今天再思考一遍,居然有了新的感悟和思路,下面说说我设想的解决办法。
首先,这是一个物体间相互关系问题,车和路还有背景的相互关系。原来我设想过,把它们变成语义信息再更高的语义层进行分析,比如用image caption生成一段话来描述它,还想过把它们生成一张图,用车,路还有背景都用一个图的节点表征,再用边表示他们的关系。还想过硬编码来解决,直接分割,物体识别得到bounding box,然后再输入一个网络来判别相互关系。但是这些方法都会遇到泛化问题。物体相互关系的模式非常多,导致学习的模式不能覆盖所有模式,效果上就不会很好,一旦迁移到其他场景可能就出错了。比如一个人拿着棒球棍和一个人拿着棒球形的牙刷刷牙,显然是不同的动作,但是如果通过已经生成的标签来判断动作将丢失很多信息,因为标签信息本来就是有限的,但实际上一张图像上的信息近乎是无限的,一个物体和一个物体的联系,以及它们的发展,这是仅靠有限的标签是不能推断的。但是不用标签,如何来表示图像中的层次化信息呢?这个问题一直困扰着我。用图吗?用一个双图,它既能有标签又能对应回原图信息。但这个的技术难度很大,我尝试过后放弃了。图的构成就很难,图的稀疏化难上加难。
但是,我今天从反向思维却得到一条思路:会不会无论是Transformer还是CNN都不具备这个相互关系的信息提取能力?因此才限制了我们的思路?物体相互关系中,从前面车在路上的例子,虽然能识别出车和路的bounding box,但从token上看,来自于不同的token,如果要抽取车和路的关系,需要以这两个token为特征,进一步抽取出车在路上,还是车在路边,或者是车身上印着路的关系。关系从集合的角度有包含,相交,分离三种情况。考虑一种极端情况,如果路特别的大,而车比较小,那么路和车对应的token是包含路和车的形状、大小信息的,但如果直接在所有token上直接提取路和车的关系,将是比较困难的,因为识别车和路需要不同尺度的注意力图,因此没法同时注意到较小的车和较大的路。因此现有的模型无论是采用有监督方法还是无监督方法都难以得到相互关系。同时关注大尺寸物体和小尺寸物体,只要该区域存在物体就应该去获取它们的包含关系,这个机制是得到物体相互关系的基础结构。比如两个人靠得比较近,如果没关注到他们细节上在握手就没法判断他们之间的关系。如果只用握手这个动作标签来训练实际上是没用的,因为握手的前提是两个人的存在,如果只是根据握手的形状来判断握手是不准确的。因此这里有一个层次关系,先识别出物体,再根据他们的位置识别他们的相关关系。除了两个物体这种简单的包含关系,还有更复杂的分离关系,两个人在吃饭,他们的位置上是分离的,他们是在聊天还是在碰杯,这需要在检测出两个人的基础上,进一步分析他们细粒度的动作,也就是关注同一个物体不同尺寸的局部,既要关注到物体的整体轮廓,也要关注手部的细节。这就要求注意力图产生层次。一个注意力图即要关注整张图片上的轮廓,形状,又要关注局部的特征。这样用一个Query是实现不了的,形状和局部的组合是无限的,无法用一个Query表征,因此我们需要多个Query,这个在Transformer中是具备的,但是截至目前为止还没有文章探索Query之间的相互关系,每个Query是单独进行计算的。这个对应于CNN就是没有人会去比较两个卷积核的关系。但这个Query代表是物体,两个Query同时被激活,意味着这两个Query发生了联系,结合它们激活后的token之间的包含,分离,相交关系,包含了需要的所有信息,应该能得出物体之间的相互关系。
因此提出以下思路:在Transformer中获得不同尺寸的Query,当Query对应的token被激活时,把它们分离出来,单独计算他们之间的相互关系。这个关系目前没有标签可以训练,但是可以把它抽取的关系特征用于任务中,比如目标检测任务中,使用这个抽取的关系来预测两个物体的bounding box,如果是一个人拿着一个物体,那么使用这两个token来共同预测物体的bounding box应该会更准确。这样我们可以用物体的标签来使注意力图分别关注不同的局部。为得出他们的关系打下基础。 那么当实现了可以同时关注物体的整体的局部有什么用处呢?比如在本文刚开始的世界模型预测任务中,我们要预测即将发生的事情就需要既关注物体的整体,又关注物体的局部。离开这个基础,任何生成模型效果都不会太好,因为你无法预测物体的哪个部分开始发生变化。目前的模型虽然有不同的尺度Query,但它们对应的是物体一个识别过程,正如前所述,没有一个模型根据多个Query来共同识别一个物体,而且还知道Query之间的相互关系。举例说,如果我们要预测一个站立的人,他下一步是要跑还是要出拳的话,我们首先识别到他的人,同时还要对他的手部,腿部进行单独的关注,这种分离的注意力机制目前还没在公开的文章看到过。如果不进行注意力分离,那么作为一个整体的人,直接预测他的行为,我认为是不可能而且效果不好的,因为他有太多的可能性。没法和下一个动作的图像直接相关,但是当局部注意力分离以后,相当于已经给出了部分的条件概率,因此推断下一步的概率就容易多了。 总结一下,本文主要是围绕“A Path Towards Autonomous Machine Intelligence”中的世界模型的实现细节展开讨论,实现的方法可能很多,但本文主要从尺寸分离这个角度进行阐述,这是实现预测的一个基础,而且也解决了我一直以来的图像层次化语义问题,为了提取越来越高层的语义,我们并不能不断丢弃细节,反而应该把细节、局部分离出来,这样才能实现高层语义从细节提取的要求。对一个侦探而言不应错过现场的任何蛛丝马迹!具体的实现细节欢迎各位留言讨论。
