LLNL国家实验室《计算高效深度学习:算法趋势和机遇》,52页pdf

来源:专知
本文为约2384字,建议阅读4分钟
本文介绍了LLNL国家实验室发布的《计算高效深度学习:算法趋势和机遇》。

原文链接:https://arxiv.org/abs/2210.06640
-
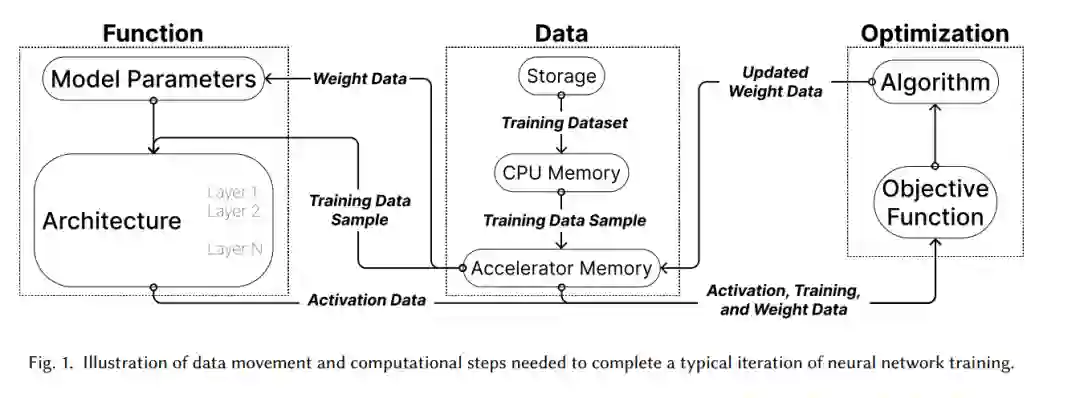
形式化加速 :我们回顾DNN效率指标,然后形式化算法加速问题。 -
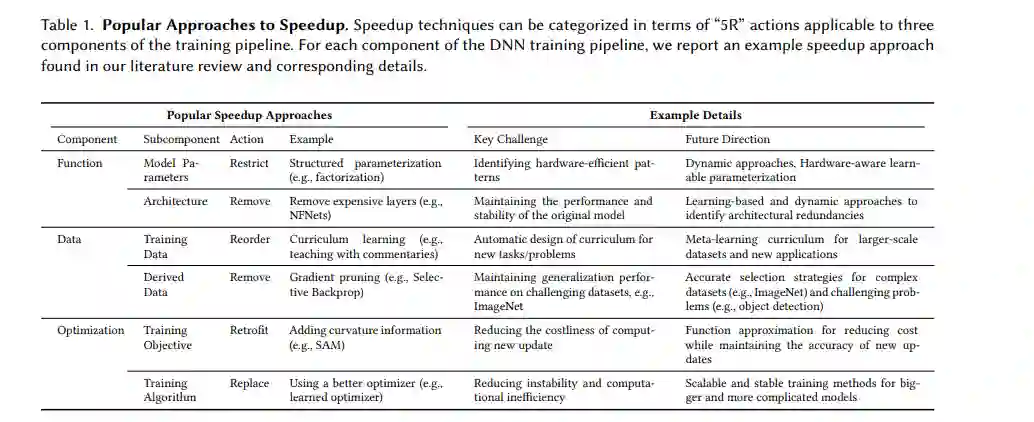
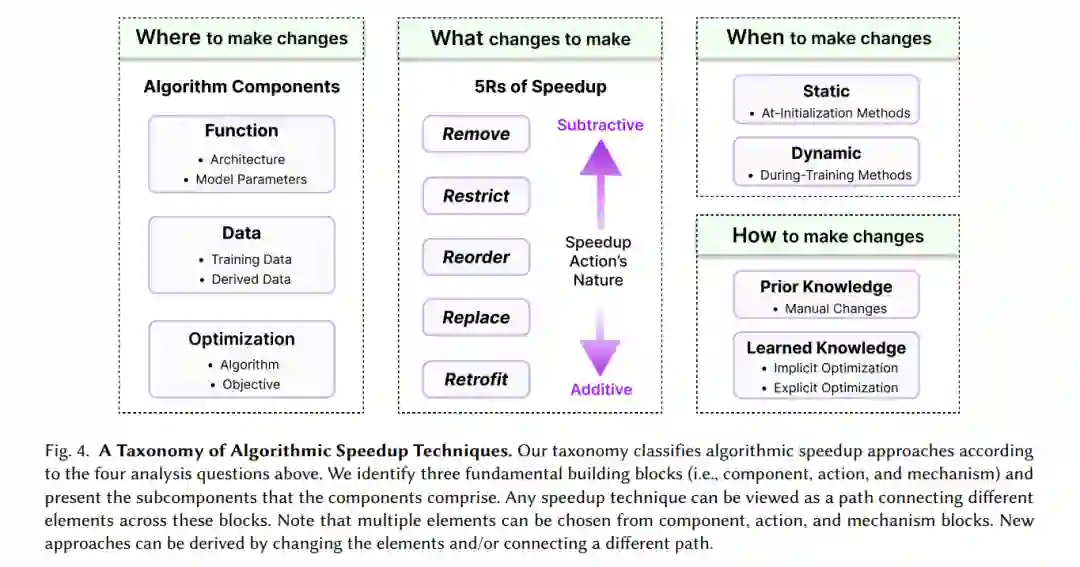
分类和调研 :我们通过适用于3个培训管道组成部分的5个加速行动(5Rs)对200多篇论文进行分类(见表1和表3)。分类有助于为从业者选择方法,为读者消化文献,并为研究人员识别机会。 -
最佳评估实践 :我们识别了文献中常见的评估陷阱,并相应地提出最佳评估实践,以实现对各种加速技术的全面、公平和可靠的比较。 -
从业者指南 :我们讨论了影响加速方法有效性的计算平台瓶颈。根据训练管道中瓶颈的位置,提出适当的方法和缓解措施。
报告链接:
https://www.zhuanzhi.ai/vip/8eeded2b8ab57cba639c26c2c58b4477


登录查看更多
相关内容
Arxiv
0+阅读 · 2022年12月14日
Arxiv
0+阅读 · 2022年12月14日
Arxiv
37+阅读 · 2021年5月28日
Arxiv
13+阅读 · 2021年4月7日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年12月14日
Arxiv
0+阅读 · 2022年12月14日
Arxiv
37+阅读 · 2021年5月28日
Arxiv
13+阅读 · 2021年4月7日