
选自arXiv机器之心编译编辑:赵阳
如果硬件跟不上需求,我们可以尽可能提高算法效率。 训练越来越大的深度学习模型已经成为过去十年的一个新兴趋势。如下图所示,模型参数量的不断增加让神经网络的性能越来越好,也产生了一些新的研究方向,但模型的问题也越来越多。
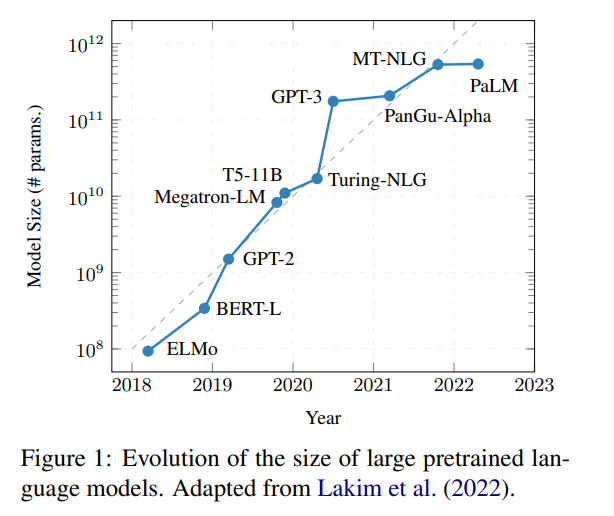
首先,这类模型往往有访问限制,没有开源,或者即使开源,仍然需要大量的计算资源来运行。第二,这些网络模型的参数是不能通用的,因此需要大量的资源来进行训练和推导。第三,模型不能无限扩大,因为参数的规模受到硬件的限制。为了解决这些问题,专注于提高效率的方法正在形成一种新的研究趋势。 近日,来自希伯来大学、华盛顿大学等多所机构的十几位研究者联合撰写了一篇综述,归纳总结了自然语言处理(NLP)领域的高效方法。

论文地址:https://arxiv.org/pdf/2209.00099.pdf 效率通常是指输入系统的资源与系统产出之间的关系,一个高效的系统能在不浪费资源的情况下产生产出。在 NLP 领域,我们认为效率是一个模型的成本与它产生的结果之间的关系。
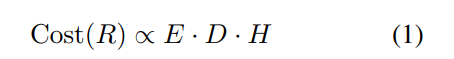
方程(1)描述了一个人工智能模型产生某种结果(R)的训练成本(Cost)与三个(不完备的)因素成正比:
(1)在单个样本上执行模型的成本(E); (2)训练数据集的大小(D); (3)模型选择或参数调整所需的训练运行次数(H)。
然后,可以从多个维度衡量成本 Cost(·) ,如计算、时间或环境成本中的每一个都可以通过多种方式进一步量化。例如,计算成本可以包括浮点运算(FLOPs)的总数或模型参数的数量。由于使用单一的成本指标可能会产生误导,该研究收集和整理了关于高效 NLP 的多个方面的工作,并讨论了哪些方面对哪些用例有益。
该研究旨在对提高 NLP 效率的广泛方法做一个基本介绍,因此该研究按照典型的 NLP 模型 pipeline(下图 2)来组织这次调查,介绍了使各个阶段更高效的现有方法。
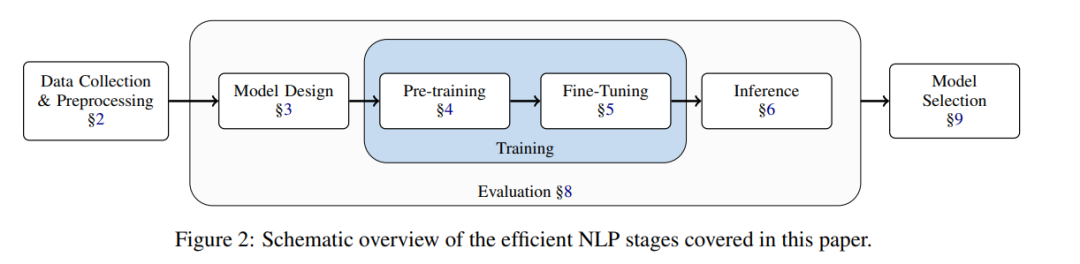
这项工作给 NLP 研究人员提供了一个实用的效率指南,主要面向两类读者:
(1)来自 NLP 各个领域的研究人员,帮助他们在资源有限的环境下工作:根据资源的瓶颈,读者可以直接跳到 NLP pipeline 所涵盖的某个方面。例如,如果主要的限制是推理时间,论文中第 6 章描述了相关的提高效率方法。 (2)对改善 NLP 方法效率现状感兴趣的研究人员。该论文可以作为一个切入点,为新的研究方向寻找机会。
下图 3 概述了该研究归纳整理的高效 NLP 方法。
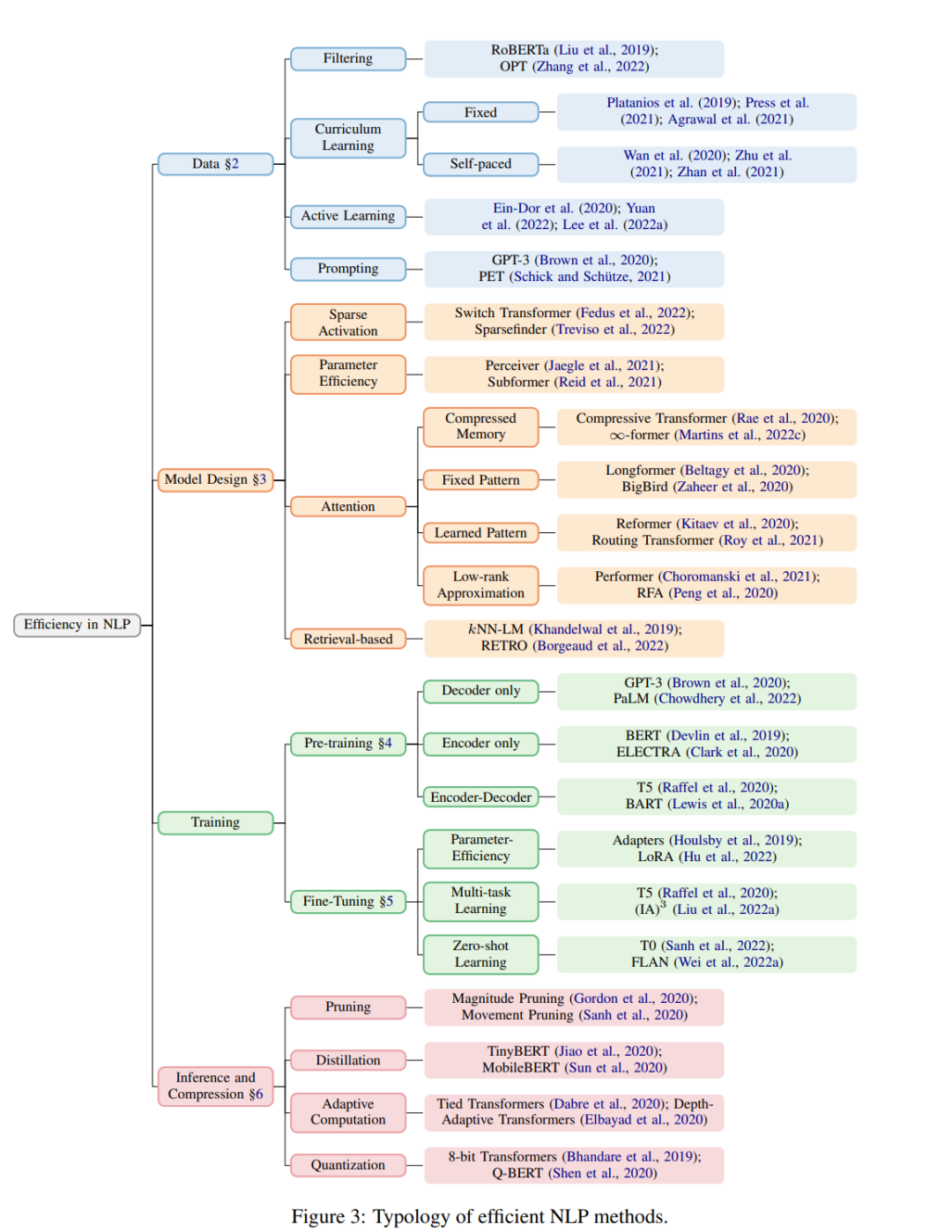
此外,虽然硬件的选择对模型的效率有很大的影响,但大多数 NLP 研究者并不能直接控制关于硬件的决定,而且大多数硬件优化对于 NLP pipeline 中的所有阶段都有用。因此,该研究将工作重点放在了算法上,但在第 7 章中提供了关于硬件优化的简单介绍。最后,该论文进一步讨论了如何量化效率,在评估过程中应该考虑哪些因素,以及如何决定最适合的模型。
