
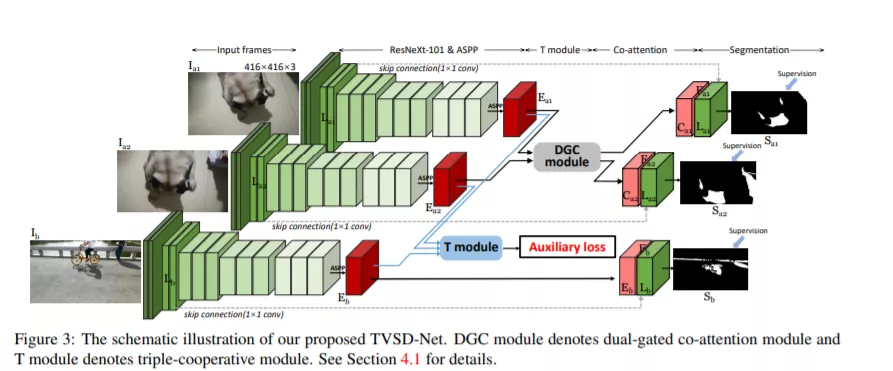
近年来,在单个图像中进行阴影检测已引起了学界广泛的研究兴趣。但是,关于动态视频场景中阴影检测的探索工作却很少,其面临的一个主要瓶颈是缺乏具有高质量像素级标注的视频阴影检测数据集。在本工作中,我们收集和标注了一个新的视频阴影检测数据集(ViSha),其中包含120个视频,总计11685帧,涵盖了60个不同的阴影对象类别,也包括了不同长度、不同运动和照明条件下的视频,并且我们为所有的11685帧都提供了精确的像素级标注。据我们所知,这是用于视频阴影检测的第一个面向深度学习的数据集。此外,我们设计了一个基础模型,即基于三元合作模式的视频阴影检测模型(TVSD-Net)。TVSD-Net以协作的方式利用三元并行网络来学习视频内和视频间级别的判别表示。在网络内部,我们提出了协同注意力模块来约束同一视频中相邻帧的特征,同时引入辅助相似度损失来挖掘不同视频之间的语义信息。最后,我们在ViSha的测试集上对12种相似任务中使用的模型进行了评估(包括单个图像阴影检测器,视频对象分割和显著性检测方法)。实验表明,我们的模型在视频阴影问题上优于上述对比方法。
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯
相关论文