多模态大语言模型(Multi-modal Large Language Models, MLLMs)作为一种整合视觉与文本信息的强大范式,已广泛应用于各类多模态任务。然而,这类模型常常存在幻觉(hallucination)问题,即生成看似合理却与输入内容或常识知识相悖的信息。本文综述了图像到文本(Image-to-Text, I2T)和文本到图像(Text-to-Image, T2I)生成任务中幻觉评估基准和检测方法的研究进展。 具体而言,我们首先基于忠实性(faithfulness)与事实性(factuality)构建了一套幻觉分类体系,并涵盖了实践中常见的幻觉类型。随后,我们系统回顾了现有用于 T2I 和 I2T 任务的幻觉评估基准,重点介绍其构建流程、评估目标与采用的指标。此外,我们还总结了近年来幻觉检测方法的研究进展,这些方法能够在实例级别识别幻觉内容,并作为基于评估基准方法的有力补充。最后,本文指出当前评估基准与检测方法存在的关键局限,并展望未来可能的研究方向。 关键词:多模态大语言模型、视觉-语言模型、扩散模型、幻觉评估、幻觉检测
1 引言
近年来,多模态大语言模型(Multi-Modal Large Language Models,MLLMs)在融合视觉与文本信息方面取得了显著进展,支持了广泛的多模态理解与生成任务。图像到文本(Image-to-Text,I2T)模型,如 GPT-4o(OpenAI, 2024)、Gemini(Team et al., 2023)和 Qwen-VL(Wang et al., 2024),在视觉问答和图像描述等任务上表现出色,具备强大的图像识别与推理能力,且无需依赖外部工具。相对地,文本到图像(Text-to-Image,T2I)模型,如 Stable Diffusion(Rombach et al., 2022)和 DALL·E(Ramesh et al., 2021),在基于文本提示生成高质量图像方面也取得了长足进展,能够准确对齐用户指定的内容或艺术风格。
尽管进展显著,I2T 与 T2I 模型仍面临诸多挑战,包括对分布变化的鲁棒性不足(Zhang et al., 2024;Guo et al., 2024;Aafaq et al., 2022;Liu et al., 2023)、易受攻击(Vice et al., 2024;Zhang et al., 2025;Fan et al., 2024),以及幻觉(hallucination)现象(Huang et al., 2023;Bai et al., 2024;Lan et al., 2024;Liu et al., 2024)。其中,幻觉问题尤为关键,指的是模型生成表面看似合理、实则与输入信息或事实知识不符的输出内容。
幻觉问题在大模型的实际应用中仍是一项重大挑战。早期研究主要关注 I2T 模型中的幻觉,强调生成文本输出与对应视觉输入之间的不一致性(Rohrbach et al., 2018;Li et al., 2023)。而近期的研究已将关注扩展至 T2I 模型(Chen et al., 2024;Hu et al., 2023),此类幻觉体现为生成图像与文本提示之间的不对齐。 本综述聚焦于 MLLMs 中 I2T 与 T2I 两类任务中的幻觉现象,并将幻觉划分为忠实性幻觉(faithfulness hallucination)与事实性幻觉(factuality hallucination)两类。忠实性幻觉指模型输出与用户输入或先前输出之间存在不一致,例如错误识别物体或生成图像与提示不符;而事实性幻觉则指模型输出与常识或世界知识相冲突,例如地标识别错误或医学图像中的不合理生成结果。
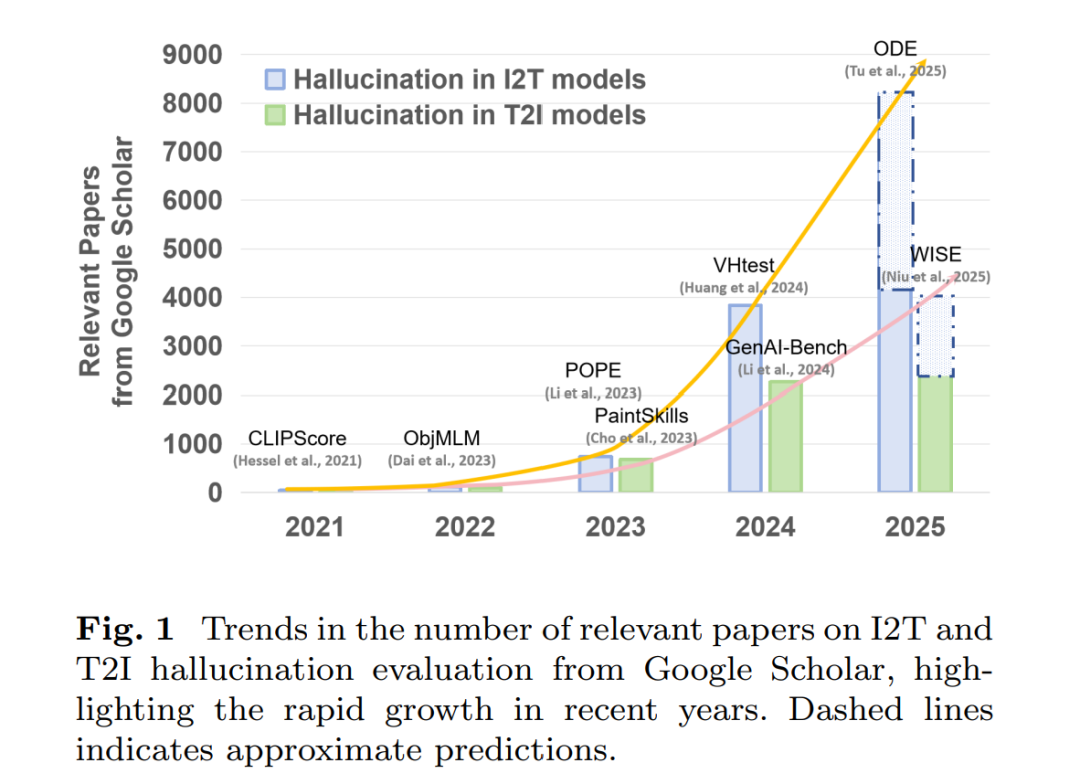
如图 1 所示,幻觉评估与基准构建近年来受到广泛关注,涌现出大量面向 I2T(Li et al., 2023;Wu et al., 2024;Fu et al., 2023;Seth et al., 2024;Zhou et al., 2023)与 T2I(Hu et al., 2023;Feng et al., 2023;Gokhale et al., 2022;Huang et al., 2024)模型幻觉的评估基准,覆盖不同研究视角。本文系统综述了 I2T 与 T2I 任务中针对忠实性与事实性幻觉的评估基准,详细比较了它们在数据来源、评估任务、图文对构建方式与幻觉类型等方面的异同,重点指出评估方法正朝着自动化构建与细粒度评估方向演进。此外,我们还提供了一个统一视角,以比较不同任务中幻觉评估的共性与差异。
MLLMs 的自由响应格式也为幻觉评估带来了额外挑战,尤其是在图像描述和图像生成等自由文本任务中。因此,幻觉检测方法在构建评估基准中发挥着关键作用,能够减少对昂贵人工标注的依赖,并实现更具扩展性的评估。反过来,评估基准提供了带标注的数据和标准化指标,有助于幻觉检测方法的开发与评估。为了更全面地展现评估与检测之间的互补关系,本文进一步总结了现有幻觉检测方法,并从统一视角探讨其在 I2T 与 T2I 模型中的可行性。
总之,本文旨在通过对 I2T 与 T2I 任务中幻觉评估基准与检测方法的全面综述,推进 MLLMs 幻觉研究的发展。相较于已有主要聚焦 I2T 任务幻觉的综述(Huang et al., 2023;Bai et al., 2024;Lan et al., 2024;Liu et al., 2024),我们拓展了视野,纳入 T2I 任务中的幻觉研究,并对忠实性与事实性幻觉进行了统一梳理。此外,我们对现有评估与检测方法进行了系统分类,并引入清晰的分类框架,例如将幻觉检测方法划分为黑盒方法与白盒方法,并按照不同粒度进行整理。同时,我们也强调了近年来在统一 I2T 与 T2I 模型幻觉评估与检测方面的努力,有助于更全面地理解幻觉现象。
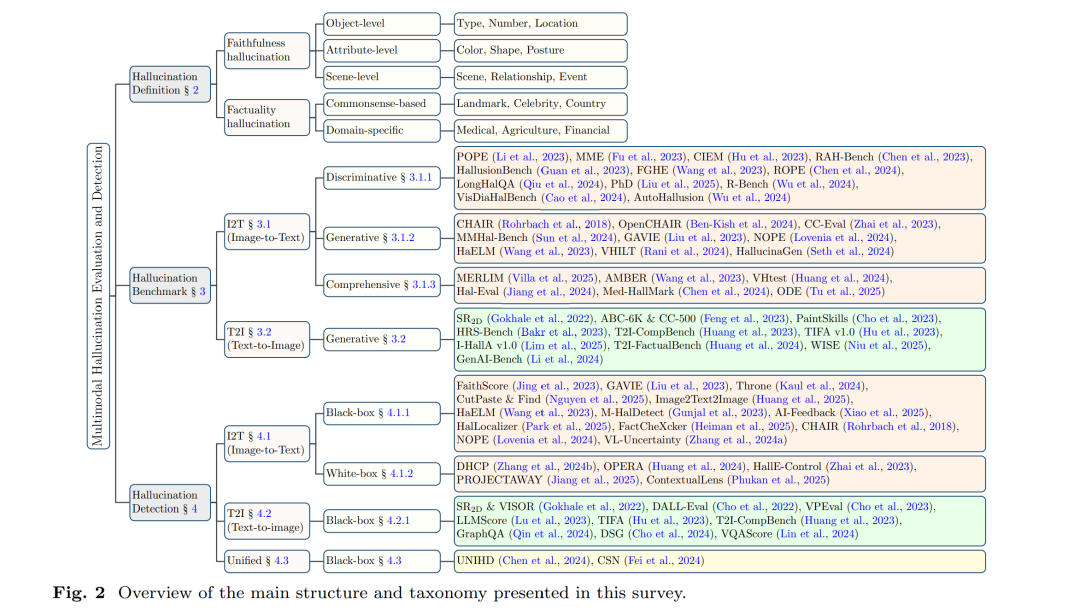
本文结构安排:为帮助读者更清晰地理解相关研究进展,如图 2 所示,本文结构安排如下:第二节我们首先定义 I2T 与 T2I 任务中的幻觉类型,并阐明不同任务间幻觉类型的联系;第三节分析与总结现有 I2T 与 T2I 幻觉评估基准,重点讨论幻觉类型、构建方法与评估指标,并强调评估基准的发展趋势;在此基础上,第四节我们对当前 MLLMs 幻觉检测方法进行分类,探讨统一检测方法的可行性;最后,第五节讨论当前幻觉评估的局限性与挑战,并提出未来研究的潜在方向。