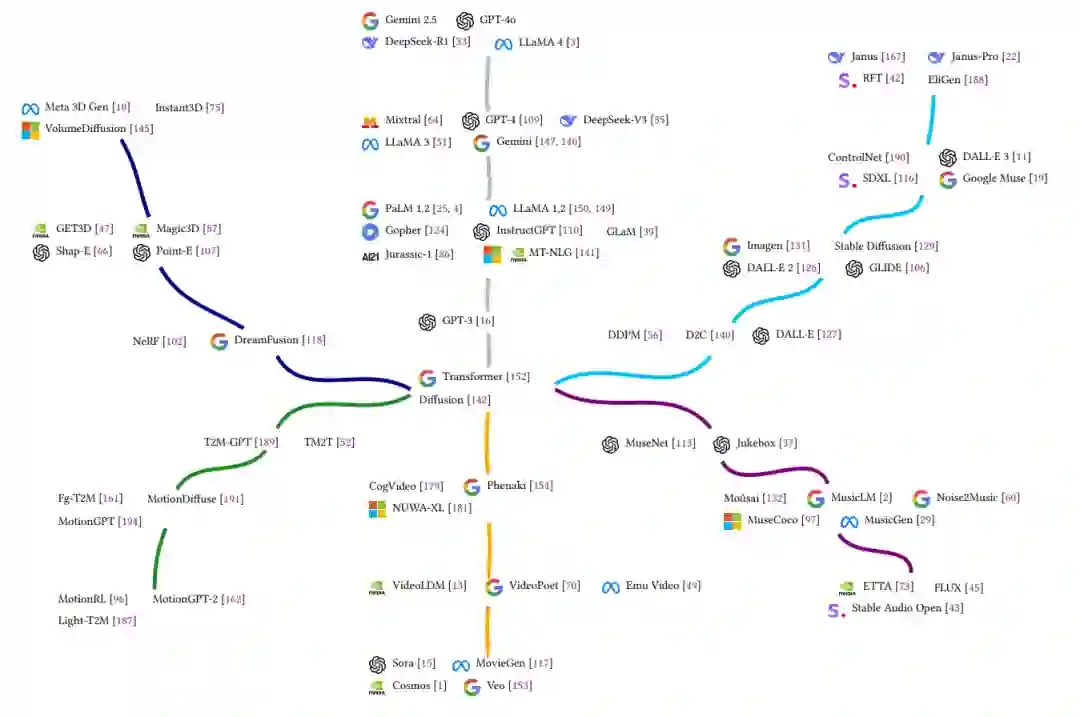
多模态大型语言模型(Multimodal Large Language Models,MLLMs)已迅速发展,超越了文本生成的范畴,如今能够覆盖图像、音乐、视频、人类动作以及三维物体等多种输出模态。它们通过在统一架构下将语言与其他感知模态整合,实现了跨模态的生成能力。本文综述将六大主要生成模态进行分类,并探讨了若干核心技术——包括自监督学习(Self-Supervised Learning, SSL)、专家混合机制(Mixture of Experts, MoE)、基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)以及思维链提示(Chain-of-Thought, CoT)——如何赋能跨模态能力。我们分析了关键模型、架构趋势及其涌现的跨模态协同效应,并重点指出了可迁移的技术路径与尚未解决的挑战。诸如 Transformer 和扩散模型等架构创新为这种融合奠定了基础,使得跨模态迁移与模块化专精成为可能。本文还总结了跨模态协同的最新发展趋势,并指出了评估方式、模块化设计及结构化推理等方面的开放性难题。该综述旨在提供一个关于 MLLM 发展的统一视角,并指明实现更通用、可适应、可解释的多模态系统的关键路径。
1 引言
自 2022 年底首次亮相以来,基于文本的大型语言模型(Large Language Models,LLMs)已成为人工智能领域的基础支柱。这些模型不仅重塑了人工智能的格局,也深刻融入了我们的日常生活。它们的演进推动了自然语言处理、人机交互以及多模态应用等方面的创新,为各个领域的无缝集成铺平了道路。随着发展,LLMs 已从最初的简单文本生成模型,演进为支持上下文学习(in-context learning)【16, 109, 149, 51】、指令跟随(instruction following)【110, 147, 146】以及多步推理(multi-step reasoning)【33】的复杂系统,正在重塑我们与计算机交互、完成任务和创造数字内容的方式。
然而,智能并不局限于语言本身。人类通过丰富的模态——文本、视觉、音频、动作等——来感知和理解世界。硬件的进步使得机器具备了处理、解释和生成这些多样化数据流的能力。这一技术趋势正推动研究社区迈向更加整体化的多模态方法,促使人工智能与人类复杂的感知方式更紧密对齐。因此,先进模型不仅擅长理解和生成文本,还能将文本与视觉结合【123】,或与音频整合【40】。这种演进也体现在输出形式上,它们正日益呈现出多模态和通用化的特征,突破了传统单一模态的响应模式。如今的模型常常以混合类型的数据作为输入【109, 147】,这一多模态集成正在推动人工智能系统逐步理解现实世界的复杂性【1】,不断逼近人类通用理解的能力。
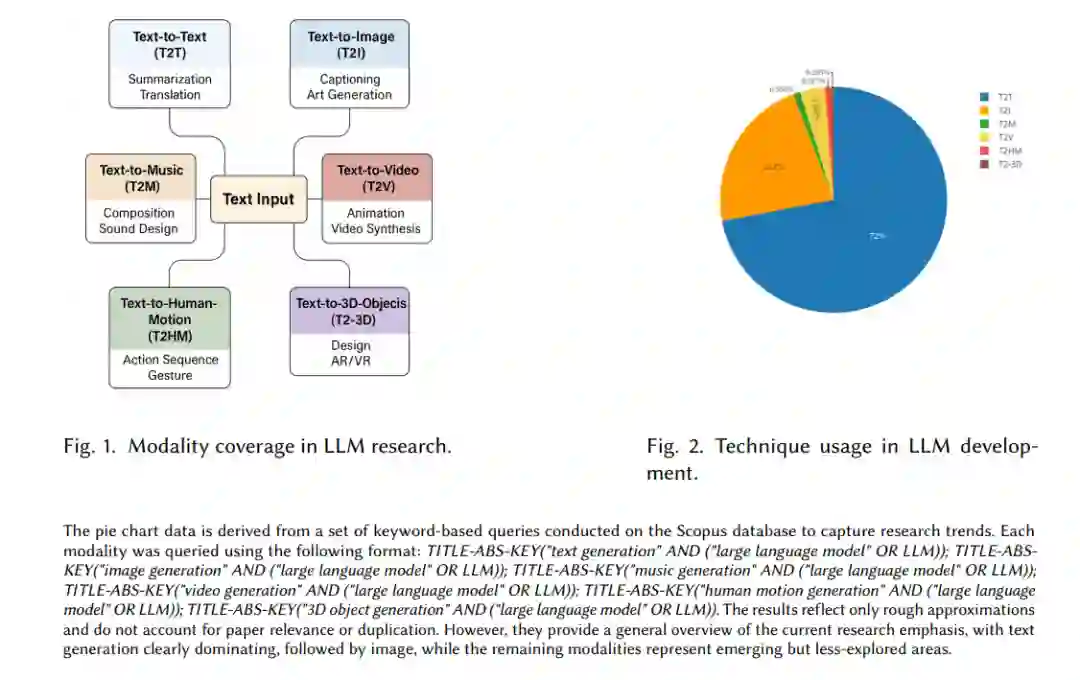
虽然文本依然是这些模型处理的核心要素,但其生成能力已扩展至多个输出模态。为更好地理解这种多样性,本文提出了一个全新的分类方式,将多模态大型语言模型(Multimodal Large Language Models,MLLMs)的主要生成输出划分为六大关键类别:
文本生成文本(Text-to-Text, T2T):为所有语言类任务及自然语言处理的基础,支撑着信息检索、摘要生成、翻译与对话系统。
文本生成图像(Text-to-Image, T2I):用于视觉内容的生成与分析,是各类视觉生成任务的核心。 * 文本生成音乐(Text-to-Music, T2M):音乐是一种复杂的听觉媒介,包含多种乐器与情感表达,其建模难度高于一般音频。 * 文本生成视频(Text-to-Video, T2V):结合时间与视觉信息以生成动态场景,涉及现实物理规律,类似一个世界模型。 * 文本生成人类动作(Text-to-Human-Motion, T2HM):广泛应用于动画、机器人与虚拟人等场景,是实现直观人机交互的重要方式。 * 文本生成三维物体(Text-to-3D-Objects, T2-3D):对虚拟现实、游戏与设计等应用至关重要,有助于在沉浸式环境中实现想象与交互。
这六大类别代表了当前生成模型所涉及的主要模态,每种模态对应一种独特的数据输出形式与应用场景。本文将音乐单独归为 Text-to-Music(T2M),而非更广义的 Text-to-Audio,这是因为语音与文本关系密切,本质上是一种可直接相互转换的形式;而音乐则拥有与语言截然不同的结构、节奏、和声与创作元素,建模复杂性更高,因此值得单独对待。通过明确划分这些能力,我们希望强调生成模型所能覆盖的广泛输出范式,每种模式既有独特的应用场景,也伴随着专属的技术挑战。
支撑这些多模态生成能力的,是一系列基础性的架构创新,主要包括 Transformer【152】及其核心的注意力机制【5】,以及在众多视觉生成任务中表现突出的扩散模型(diffusion models)【106】。随着模态复杂度的不断提升,人工智能系统所需应对的问题日益复杂,模型结构与训练方法也在不断演进。这种演进往往是解锁模型涌现能力的关键【165】。其中有四项技术在提升模型推理能力方面起到了决定性作用:三项主要用于训练阶段,分别是自监督学习(Self-Supervised Learning,SSL)【121】、专家混合机制(Mixture of Experts,MoE)【62】以及基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)【26】;第四项是用于推理阶段的思维链提示(Chain-of-Thought,CoT)【164】。
自监督学习(SSL):在训练阶段使模型从海量未标注数据中学习,通过预测输入中被遮蔽的信息,建立起对语言、模式与世界知识的基础理解,为复杂推理提供必需支持。 * 专家混合机制(MoE):通过选择性激活不同“专家”子网络,以较低的计算开销显著提升模型容量,能更高效地学习多样知识与复杂模式,是增强高级推理能力的关键手段。 * 基于人类反馈的强化学习(RLHF):一种训练阶段的微调方法,使模型更符合人类偏好与行为预期。通过人类排名数据训练,RLHF 能提升模型输出的一致性、可靠性与指令理解能力。 * 思维链提示(CoT):在推理阶段引导模型生成一系列中间步骤,以增强多步推理能力。这种显式的思维过程有助于更准确且透明地处理复杂问题。
已有的综述文献也为理解 MLLMs 的发展提供了重要参考。[8] 提出了多模态学习的核心框架,并总结了代表性挑战,包括表示学习、模态翻译、模态对齐、模态融合与协同学习,奠定了 MLLM 研究的基础。[17] 评述了以视觉为中心的 MLLMs,涵盖其架构、模态对齐策略以及视觉定位、图像生成等应用。[183] 关注多模态模型中的人类偏好对齐机制,[30] 则深入探讨了模型的可解释性与可理解性,是可信 AI 的关键因素。[182] 详尽梳理了 MLLMs 在粒度、多模态与多语言覆盖及应用场景上的演进,并进一步推进了如多模态上下文学习、思维链推理、LLM 辅助视觉理解等新方法。[95] 系统地回顾了 MLLMs 在多种模态下的应用与安全性问题,[158] 则深入探讨了多模态思维链推理(Multimodal Chain-of-Thought, MCoT)在不同任务中的潜力。
为全面理解这一不断演化的研究图景,本文结构如下:第 2 节介绍背景知识与基本概念,并定义本文的综述范围与方法论;第 3 节对前述六大生成模态(T2T, T2I, T2M, T2V, T2HM, T2-3D)的历史发展进行梳理;第 4 节讨论四项核心技术(SSL, MoE, RLHF, CoT)的发展过程与关键作用;第 5 节综合分析跨模态的趋势、面临的挑战以及架构层面的共性,探索模态与技术之间的协同效应;第 6 节展望未来研究方向,如扩展 SSL 至新模态、模块化专家机制、以及非文本模态的思维链推理等;第 7 节总结全文核心观点,并探讨通向统一多模态系统的发展路径。