多模态大规模语言模型(MLLMs)因其在视觉问答、视觉感知、理解与推理等多种应用中的出色表现,在学术界和工业界日益受到关注。近年来,研究人员从多个角度对 MLLMs 进行了深入研究。本文对180个 MLLMs 的基准和评估进行了全面综述,重点探讨了以下几个方面:(1) 感知与理解,(2) 认知与推理,(3) 特定领域,(4) 关键能力,以及 (5) 其他模态。最后,我们讨论了当前 MLLMs 评估方法的局限性,并探讨了未来的有前景的研究方向。我们的核心论点是,评估应被视为一门至关重要的学科,以更好地支持 MLLMs 的发展。更多详情请访问我们的 GitHub 仓库:https://github.com/swordlidev/Evaluation-Multimodal-LLMs-Survey。
1 引言
近年来,大规模语言模型(LLM)在学术界和工业界引起了广泛关注。诸如GPT [1] 等LLM的出色表现使人们对其代表通用人工智能(AGI)迈出的重要一步充满乐观。这些卓越的能力激发了将LLM与其他模态模型结合以增强多模态能力的研究努力。由此,多模态大规模语言模型(MLLMs) [2] 应运而生。这一概念得到了OpenAI的GPT-4V [3] 和Google的Gemini [4] 等专有模型的巨大成功的进一步支持。与早期仅限于解决特定任务的模型不同,MLLMs 在广泛的应用中表现出了卓越的性能,包括一般的视觉问答(VQA)任务和特定领域的挑战。
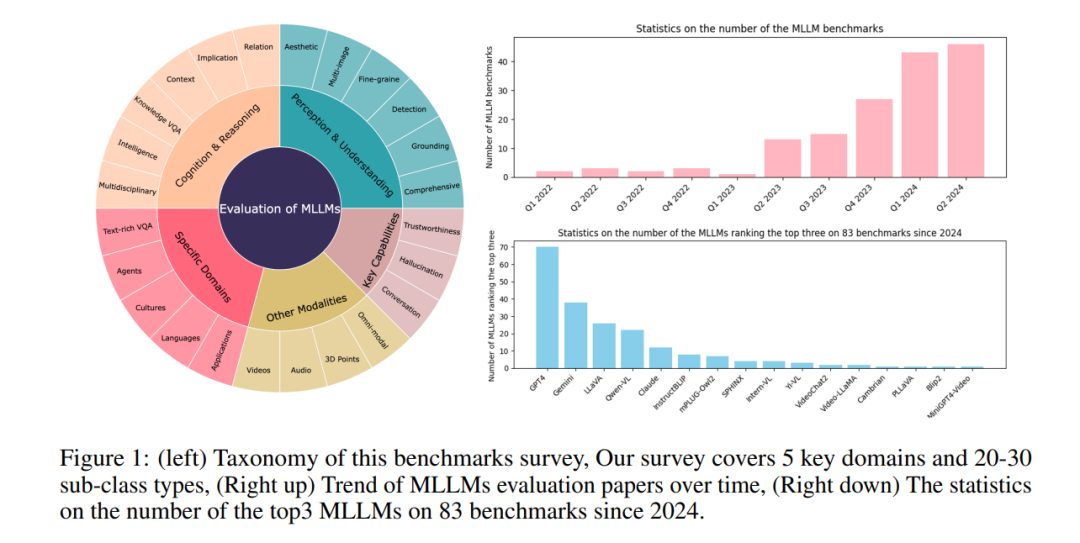
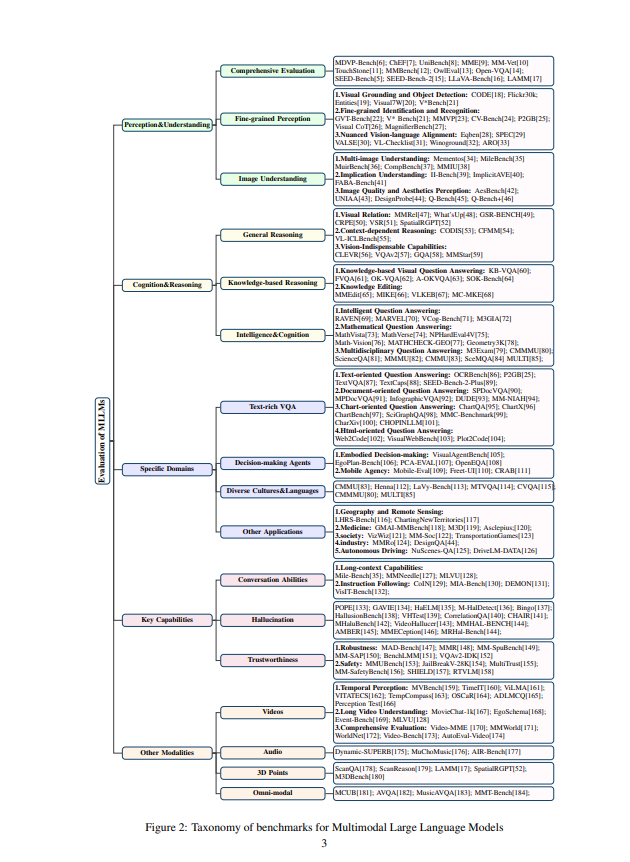
为MLLMs 提供全面且客观的基准评估对于比较和研究各种模型的性能至关重要,并且在MLLMs 的成功中发挥了关键作用。首先,评估LLM有助于我们更好地理解MLLMs 的优势和劣势。例如,SEED-Bench [5] 显示了当前MLLMs 在理解物体之间的空间关系方面能力较弱,而在全局图像理解方面则表现出较高的性能。其次,在各种场景中的评估可以为MLLM在医学、工业和自动驾驶等领域的应用提供有价值的指导,从而激发未来的设计并扩大其能力范围。第三,MLLMs 的广泛适用性强调了确保其稳健性、安全性和可靠性的重要性,特别是在安全敏感的领域。最后,评估MLLMs 的其他用户友好特性也具有重要意义,包括处理长文本上下文的能力以及准确执行指令的能力。因此,我们旨在通过回顾当前的评估协议,引起社区对MLLM评估重要性的关注。最近,众多研究工作从感知、理解、认知和推理等多个角度对MLLMs 进行了评估。此外,还测试了MLLMs 的其他能力,包括稳健性、可信性、专门应用和不同模态。尽管进行了这些努力,仍然缺乏一个全面概述,能够捕捉到这些评估的全貌。在本综述中,我们旨在提供对快速发展的MLLM评估领域的全面概述。如图1所示,我们的综述涵盖了MLLM评估的五个关键领域,涉及20-30个详细类别。该图还展示了MLLM评估论文随时间的趋势,显示了出版物数量的快速增长。这种增长表明该研究领域已广泛引起关注。此外,我们提供了自2024年以来83个基准测试中三大MLLMs 的性能统计数据,数据显示OpenAI的GPT-4和Google的Gemini表现优异,吸引了显著的学术关注。正如图2所示,我们对180个基准进行了调查,并将文献按五个主要类别组织,涵盖感知与理解、认知与推理、特定领域、关键能力和其他模态等方面。
感知与理解 指的是接收和提取多模态数据特征并进行跨模态分析的能力。评估MLLMs的感知与理解能力包括评估MLLMs是否能够感知视觉表征、识别视觉细节、理解图像传达的含义和情感,并正确回答相关问题。这些能力是MLLMs的基石,使其能够执行广泛的任务和应用。
认知与推理 包括模型在基本感知与理解之上的高级处理和复杂推理能力。认知能力涉及处理和操作信息以将其转化为知识,而推理能力则侧重于得出逻辑结论和解决问题。强大的认知与推理能力使MLLMs能够在复杂任务中进行有效的逻辑推理。
特定领域 关注MLLMs在特定任务和应用中的能力,例如处理文本丰富的视觉信息以及在现实场景中执行基于代理的决策任务。讨论还扩展到评估其在医学、自动驾驶和工业等专门领域的表现。
关键能力 对MLLMs的性能和用户体验产生重大影响,包括管理复杂对话、准确执行指令、避免幻觉并保持可信性。这些能力对于确保MLLMs在各种实际应用中有效运行并适应各种实际场景至关重要。
其他模态 包括视频、音频和3D点云,这些模态也包含反映现实世界的丰富多样的信息。这些模态提供了关键的上下文并增强了MLLMs理解复杂场景的能力。评估MLLMs处理各种模态的能力有助于理解其在不同类型数据和任务中的表现,确保它们适合处理复杂的现实世界场景和挑战性任务。
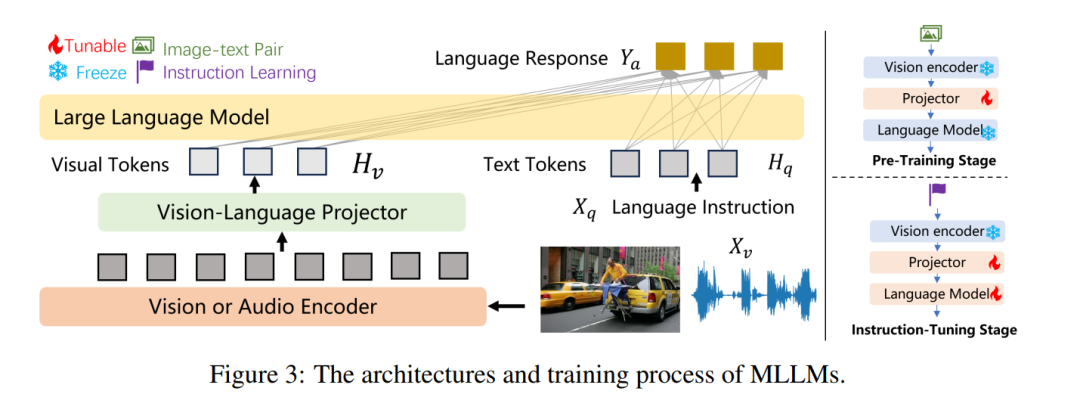
预备知识
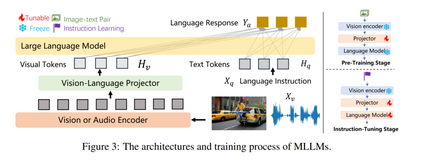
图1比较了几种常见的多模态大规模语言模型(MLLMs),包括GPT-4 [3]、Gemini [4]、LLaVA [185]、Qwen-VL [186]、Claude [187]、InstructBLIP [188]、mPLUG-Owl2 [189]、SPHINX [190]、Intern-VL [191]、Yi-VL [192]、VideoChat2 [193]、Video-LLaMA [194]、Cambrian-1 [195]、PLLaVA [196]、Blip2 [197] 和 MiniGPT4-Video [198]。标准的MLLM框架可以分为三个主要模块:一个视觉编码器 ggg,其任务是接收和处理视觉输入;一个预训练语言模型,用于管理接收的多模态信号并执行推理;以及一个视觉-语言投影器 PPP,其作为桥梁对齐这两种模态。图3展示了这种架构和训练过程的示意图。该图概述了基本语言模型、视觉编码器、投影器以及相关的预训练和指令微调过程。
感知与理解
在评估多模态大规模语言模型(MLLMs)的感知与理解能力时,我们重点关注那些评估模型在视觉信息处理方面基本能力的基准。这包括评估MLLMs在物体识别与检测的准确性、场景上下文与物体关系的理解,以及对图像内容相关问题的响应能力。感知与理解能力是MLLMs的基石,使其能够执行广泛的任务和应用。本节首先介绍MLLMs的综合评估基准,然后分别讨论粗粒度和细粒度的视觉感知评估基准。
认知与推理
多模态大规模语言模型(MLLMs)的认知与推理能力包括模型在基本感知与理解之上的高级处理和复杂推理的能力。认知能力涉及整合和操作提取的信息,以形成连贯的表征,而推理能力则侧重于得出逻辑结论和解决问题。强大的认知与推理能力使MLLMs能够在复杂任务中进行有效的逻辑推理。
本节重点探讨多模态大规模语言模型(MLLMs)在特定任务和应用中的能力,例如它们整合复杂的视觉和文本信息的能力、适应动态环境中决策角色的能力以及有效处理多样化文化和语言数据的能力。随后,本节还将扩展讨论MLLMs的实际应用,强调它们在医学、工业和自动驾驶等多个领域的影响。通过概述这些基准,本节旨在强调MLLMs性能评估的进展及其在应对不同领域现实世界挑战中的潜力。
结论
评估具有深远的意义,在推动通用人工智能(AGI)模型的发展中变得至关重要。它不仅确保模型按预期运行,还确保其达到所需的准确性、稳健性和公平性标准。通过严格的评估,我们可以识别模型的优势与劣势,指导进一步的改进,并在实际应用中建立对AI系统的信任。在本研究中,我们对多模态大规模语言模型(MLLMs)的评估与基准进行了全面概述,将其分类为感知与理解、认知与推理、特定领域、关键能力和其他模态。我们旨在增强对当前MLLMs 状态的理解,阐明其优势与局限性,并为MLLMs 的未来发展提供见解。鉴于这一领域的动态性,可能会有一些最新的进展未能完全覆盖。为此,我们计划持续更新并增强我们网站上的信息,随着新见解的出现进行补充。