

大型语言模型(LLMs)会从其训练数据集中继承显性与隐性偏见。识别并减轻这些偏见对于确保输出结果的公平性至关重要,因为这些偏见可能延续有害的刻板印象与错误信息。本研究强调了在生成式人工智能迅速发展背景下应对 LLM 偏见的必要性。我们基于偏见分析基准(如 StereoSet 和 CrowSPairs),评估了多种生成式模型(如 BERT 与 GPT-3.5)中各种偏见的存在情况。
我们提出了一种自动化偏见识别框架,用于检测 LLM 中的多类社会偏见,如性别、种族、职业与宗教偏见。我们采用双路径方法来识别文本数据中的显性偏见与隐性偏见。实验结果表明,经过微调的模型在应对性别偏见方面表现欠佳,但在识别并避免种族偏见方面表现更优。研究发现,尽管某些方面取得了一定进展,LLMs 仍然过度依赖关键词。
为了揭示所分析的 LLM 在检测隐性偏见方面的能力,我们进一步采用词袋(Bag-of-Words)分析,并发现词汇中存在隐性刻板印象的迹象。为增强模型性能,我们基于提示工程与偏见基准数据增强对模型进行微调。微调后的模型在跨数据集测试中表现出良好的适应性,并在隐性偏见基准上取得显著提升,性能提升幅度高达 20%。
自然语言处理(NLP)的发展使大型语言模型(LLMs)在各类行业应用中变得无处不在。这些模型被用于提升数据可访问性、辅助数据解释,并基于数据分析提出解决方案(Bommasani et al., 2022; Git, 2023; OpenAI, 2023a)。其应用范围覆盖多个领域,例如在医疗保健中,通过 LLMs 提升患者数据分析能力;在软件开发等商业场景中,Github Copilot 等工具用于辅助代码生成(Git, 2023)。这种广泛应用不仅出现在企业环境中,也深入渗透到教育领域(Rudolph, 2023; Tlili et al., 2023; Zhai, 2022; Bommineni et al., 2023; Baidoo-Anu and Ansah, 2023; Qadir, 2022),例如用来支持有学习障碍的儿童(Rane, 2023)。然而,随着应用影响力不断扩大,也带来了确保模型输出正确且无偏的重要责任(Tamkin et al., 2021; Bai et al., 2022; Chang et al., 2024)。
由于大多数 LLM 模型是在来自互联网的数据上训练的,包括网页、书籍、文章和论坛,因此这些数据很大一部分基于观点,且未必完全包含真实、准确的事实信息(Common Crawl Foundation, 2024; Bender et al., 2021; Kenton et al., 2021; Weidinger et al., 2021; Gehman et al., 2020; Chang et al., 2024; Cho et al., 2019)。此外,LLMs 普遍基于自监督或无监督学习技术,限制了对模型认为重要的模式、数据点和权重的有效控制能力(Huang et al., 2023)。这导致模型可能产生错误的、有偏的、误导性的或有毒的信息。在广为使用的模型中,可以从 RealToxicityPrompts 数据集以及对 ChatGPT 的越狱攻击中观察到这些有毒输出(Zhang et al., 2023; Gehman et al., 2020)。
即使经过大规模的预处理和清理操作,移除包含极端有害或偏倚内容的数据点,也无法保证模型不会学习到某些潜在的偏倚模式(Mikołajczyk-Bareła, 2023; Roselli et al., 2019; Bender et al., 2021)。残留偏见与算法偏见仍可能出现(Lee et al., 2019)。偏见之所以难以避免,是因为任何被人类影响或直接由人类创建的系统,都会不可避免地受到创作者偏见的影响,无论这些偏见是有意还是无意的。因此,大数据与 LLMs 天生就充满了各种形式的偏见(Bender et al., 2021; Roselli et al., 2019; Mikołajczyk-Bareła, 2023)。这些偏见会带来有害的负面影响,如资源分配偏见、表征偏见和脆弱性偏见(Sheng et al., 2021);它们可能传播与强化既有刻板印象,阻碍特定人群使用相关资源,并使某些群体更容易受到操纵与伤害(Prates et al., 2019; Hashimoto et al., 2018; Levy et al., 2021)。因此,刻画 LLMs 中的偏见在当前 AI 与机器学习研究中具有重要意义。
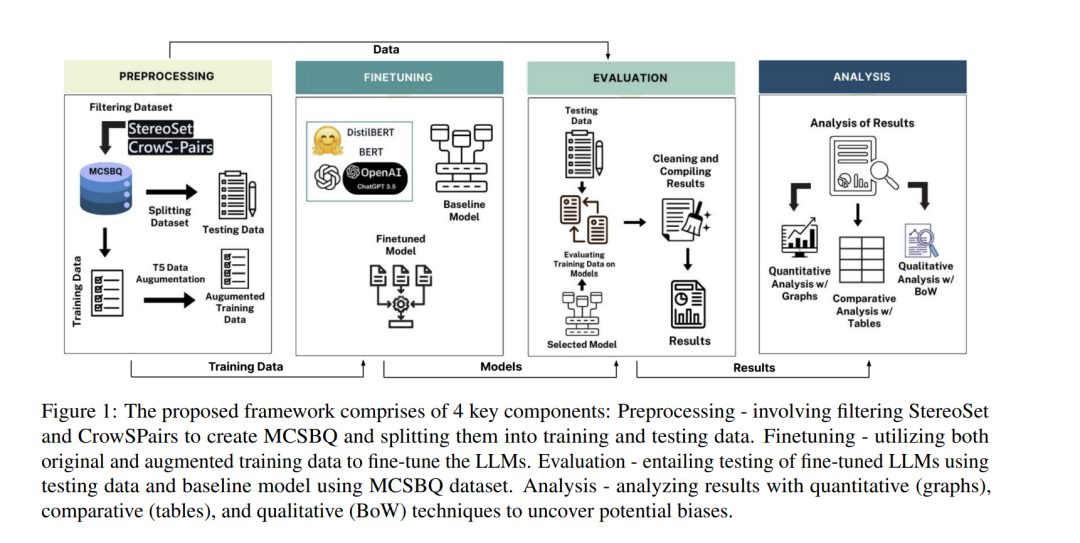
在本文中,我们基于涵盖年龄状况、残障、性别、国籍、外貌、职业、宗教以及社会经济地位等在内的大量参数,对不同模型的偏见进行了分析。研究对象包括多种模型,如 BERT、DistilBERT、GPT-3.5 等,以识别并刻画其中存在的偏见。我们使用 StereoSet 和 CrowSPairs 两个基准数据集来分析每个模型的偏见程度。作为偏见缓解策略,我们采用数据增强方法扩展用于微调 LLMs 的训练数据。图 1 给出了我们提出方法的高层概览,展示了我们的工作流程,并作为偏见刻画框架的基础。该框架聚焦于减少训练数据中的偏见,并对大型语言模型(LLMs)在微调前后的表现进行比较分析。

