

深度学习已经开启了人工智能的革命性时代。从计算机视觉(CV)的进步开始,当前的大型语言和大型多模态模型在信息处理能力上展示了显著的改进。例如,受到生成预训练变换器(GPT)的赋能,GPT-4[1]在内容创作到问题解决等多模态任务中表现卓越。深度学习也是推动自动驾驶系统发展的关键技术,这些系统利用复杂的算法(例如,物体检测、语义分割)实时处理来自传感器的数据,做出明智的决策,安全地驾驶车辆穿越各种驾驶条件和环境。
然而,尽管取得了显著的成功,AI系统对众多攻击仍然很脆弱。研究人员一直在开发新的攻击来破坏深度学习模型。特别是,对抗性攻击[2, 3, 4, 5, 6, 7, 8, 9, 10]涉及生成对抗性扰动或补丁以误导模型输出。这种对抗性扰动或补丁可以被视为一种噪声,可以与不同的干净样本融合以欺骗模型。投毒[11, 12, 13]和后门[14, 15, 16, 17]攻击也对AI系统产生了重大影响。数据投毒攻击会破坏训练数据,导致模型在预测或分类中产生错误。投毒攻击破坏了模型的整体行为,对其在广泛输入范围内的性能产生不利影响。类似地,后门攻击通过恶意训练数据将触发器嵌入模型。因此,当模型在部署过程中遇到包含此触发器的输入时,它会生成错误或未经授权的结果。
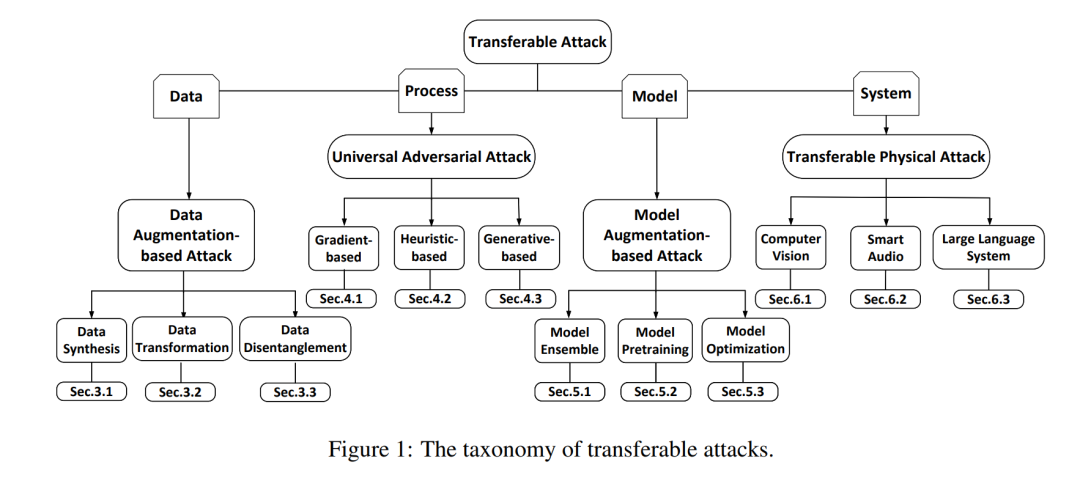
模型窃取攻击[18, 19, 20, 21, 22, 23]旨在窃取预训练的专有模型。除了窃取模型本身外,攻击者还尝试窃取底层数据,称为推理攻击。推理攻击有两种主要形式。第一种是模型反转攻击[24, 25, 26, 27],旨在重建或近似模型的原始训练或输入数据。这是通过利用模型的输出或架构来逆向工程训练过程来实现的。第二种形式是成员推断攻击[28, 29, 30, 31, 32],其目标是确定特定数据点是否被用于机器学习模型的训练集。攻击者仔细研究模型的输出,以推断给定的数据条目是否是训练数据集的一部分。 众多基于学习的攻击表现出极高的可迁移性,其中针对一个系统开发的攻击模型或方法对另一个系统有效,即使这两个系统可能具有不同的架构或配置。从本质上讲,可迁移攻击涵盖了在同一或不同领域的各种样本、不同模型甚至不同系统之间可迁移的广泛攻击。这种可迁移性使这些攻击在网络物理安全领域尤其令人关注。在这项综述中,我们提供了可迁移攻击的高层次分类,综述的结构如下。首先,我们在第2节介绍了关于迁移学习、优化方法和差异度量的背景知识,为基于学习的可迁移攻击奠定了基础。然后,我们根据攻击设计总结了现有的可迁移攻击,如图1所示。
(i) 我们在第3节从数据中心的角度研究可迁移攻击。现有研究[33, 18, 23]通过合成新数据或转换数据开发了数据增强机制。数据增强提高了训练数据的多样性,从而提高了基于学习的攻击模型的泛化能力。此外,其他研究[34, 35, 36]表明,解耦内容和风格特征可以提高攻击的可迁移性。
(ii)** 我们在第4节从学习过程的角度回顾可迁移攻击,以通用对抗性攻击为案例研究**。通用对抗性攻击旨在生成适用于各种输入的通用扰动或补丁,导致任何给定输入的错误分类。为了找到这种通用扰动,研究人员利用不同的学习方法,包括基于梯度的[37, 38, 39]和基于启发式的方法[40, 41, 42]。此外,还使用了生成对抗网络(GANs)等生成模型来生成这些通用扰动[43, 44, 45]。
(iii) 从模型角度来看,我们在第五部分回顾了基于模型增强的方法。对于黑盒攻击,攻击者不了解目标系统,包括特定的模型架构、模型参数和训练策略。黑盒攻击可以通过攻击替代模型或者通过查询目标模型使用梯度估计方法来执行。我们主要关注旨在构建一个与潜在目标模型具有类似潜在空间的替代模型的黑盒攻击[46, 40, 19]。这种方法允许攻击者针对替代模型制定攻击,然后将这些攻击转移到目标模型。为了增强攻击的可转移性,一种策略是设计针对集成的替代模型的攻击[47, 48, 21]。这种方法导致生成的对抗性扰动在不同模型中更为有效。另一种策略是利用模型窃取攻击[49, 20, 50],旨在获得黑盒系统背后的模型。然后,攻击者可以利用各种白盒方法来妥协这些系统。此外,一些研究人员针对预训练的基础模型[51],可能会影响到下游的微调模型。例如,针对预训练基础模型的数据投毒和后门攻击[52, 53, 54],在微调的下游模型上仍然有效。
(iv) 我们在第六部分从系统角度展示了可转移的攻击。我们关注计算机视觉系统、语音识别系统和大型语言模型(LLM)系统。对于每个系统,攻击设计取决于特定模态的特征和系统的威胁模型。例如,生物特征安全是计算机视觉和语音处理中的一个重要话题。不同的生物特征应用程序,如面部识别、3D面部认证和声音认证,有不同的模型设计,需要针对特定的攻击进行调整。最后,在第七部分,我们总结了当前可转移攻击的局限性,并提出了未来的设计方向。我们的最终目标是激励健壮、适应性强、安全的互联网物理系统的发展。 这份综述的独特贡献。与现有的综述相比,本综述全面评估了从转移性角度看各种攻击。表1列出了现有关于各种攻击的综述。每种基于学习的攻击都有根据不同数据模态(如图像、文本、音频、视频和图表)的不同设计原则。大多数综述[55, 64, 96, 82]只关注一种特定类型的攻击,如对抗性攻击或模型窃取攻击。相比之下,我们从转移性的角度总结了六种广泛研究的攻击。转移性的概念至关重要,因为它揭示了威胁景观比预期的更广泛,因为机器学习模型即使在攻击者无法直接访问模型的架构或参数时,也可能对不同的攻击敏感。转移性对于机器学习模型在现实世界应用中的普适性和安全性提出了问题。一些综述[56, 62, 64]只关注特定的应用领域,如自然语言处理(NLP)。我们不限于特定领域,而是在不同的模态、不同的应用和系统中回顾了可转移的攻击。我们通过从数据、过程、模型和系统的角度审视,对可转移的攻击设计进行了分类和总结。特别是,我们回顾了可转移攻击对典型的网络物理系统(包括自动驾驶、语音识别和LLM系统)的影响。总体而言,本综述提供了关于最新的可转移攻击策略的全面见解,使不同攻击类型在不同领域之间能够进行横向和纵向比较。
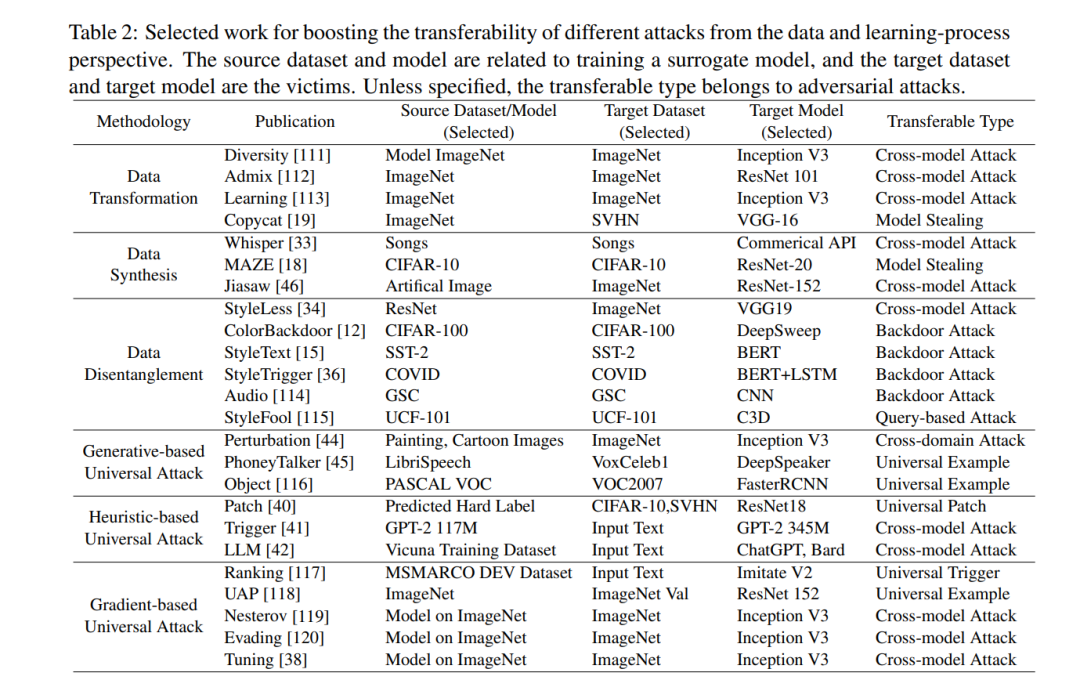
从数据角度看可转移攻击从数据角度来看,我们回顾了提高攻击可转移性的现有工作,包括数据合成、数据转换和数据解耦,如表2所示。
从过程角度看可转移攻击
从学习过程的角度来看,我们回顾了不同的学习方法,例如基于梯度和基于启发式的优化,以增强对抗性攻击的可转移性,如表2所示。优化方法的初步知识在第2.2节中介绍。在这一节中,我们提供了与可转移攻击相关的学习过程的全面概述。我们不是提供一个高层次和抽象的相关工作回顾,而是使用具体的研究实例来说明不同的基于学习的攻击方法。我们的探索涵盖了三种主要方法论:基于梯度的优化、基于启发式的优化和在设计通用对抗性攻击中的生成方法。我们希望现有的方法论可以激发更多实用的设计策略,以评估网络物理人工智能系统的安全性和安全性。
从模型角度看可转移攻击
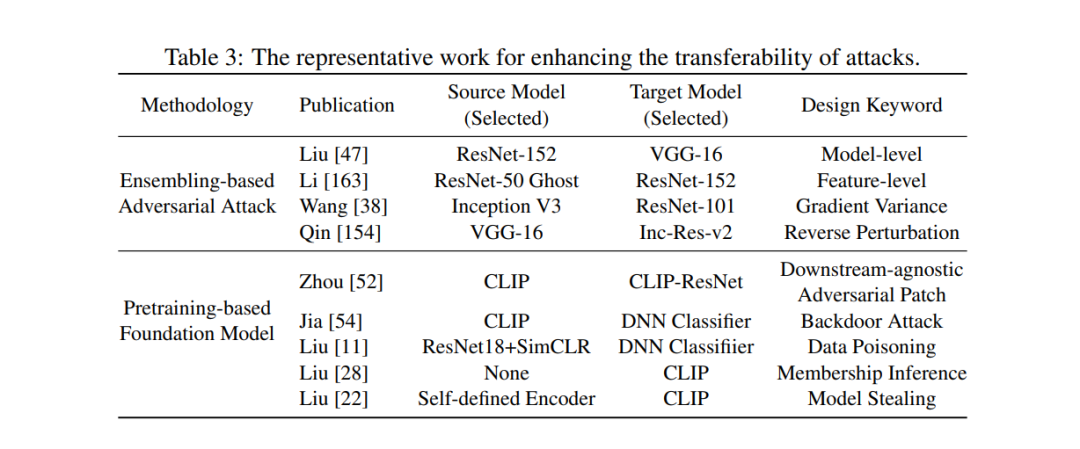
从模型的角度来看,可转移攻击需要对各种目标模型进行泛化。为了提高攻击的可转移性,已经做出了许多努力,例如集成、模型预训练和替代模型优化。在本节中,我们从模型角度回顾了与可转移性相关的研究。为了增强攻击的可转移性,最大化替代模型与目标模型之间的相似性至关重要。借鉴集成学习原则,同时使用多种不同的模型架构可以确保设计的攻击与各种潜在模型兼容。此外,攻击预训练的基础模型可以影响下游的微调模型。最后,我们审查了在模型窃取攻击背景下优化替代模型的不同策略,增强其与目标模型的相似度。通过这种方式,我们可以提高可转移攻击的成功率。
从系统角度看可转移攻击
在本节中,我们关注针对现实世界网络物理人工智能系统的实际黑盒攻击。可转移攻击操纵了为现实世界应用设计的系统,突显了需要解决超越数字领域的安全问题的迫切性。在这一节中,我们回顾了跨多个基于AI的系统的可转移攻击的概念,包括计算机视觉系统、语音识别系统和大型语言模型(LLM)系统。基于AI的系统的不同特性在设计可转移攻击时引入了显著的复杂性。每个阶段,如数据收集、数据处理、模型设计、模型训练和模型应用,都容易受到潜在的可转移攻击。例如,在数据收集阶段,可能出现漏洞,可以通过数据投毒攻击来利用。在模型训练阶段,攻击者可能注入后门来妥协模型的完整性。至于模型应用阶段,引入的对抗性扰动可能误导基于AI的系统。这些超越领域和模态的可转移攻击策略,显著增加了基于AI的系统的脆弱性。
结论
本综述聚焦于可转移性,在不同领域对各种攻击进行了回顾和分析。我们首先提供了关于基于学习的攻击设计的背景知识。然后,从数据、过程、模型和系统的角度,我们总结了增强不同攻击可转移性的最新研究。特别是,我们回顾了基于数据增强的各种增强可转移性的攻击方法。我们总结了构建跨领域通用对抗性攻击的梯度、启发式和基于生成的方法。从模型角度出发,我们探讨了增强可转移性的方法,包括基于集成的方法、优化技术,以及使用预训练的基础模型。此外,我们还回顾了在不同领域如计算机视觉系统、语音识别系统和大型语言模型系统中的可转移攻击应用。总之,我们识别了未来研究应该解决的各种挑战。研究可转移攻击可以协助开发对策,增强系统防御,并有助于更安全可靠的机器学习模型的发展。
