
导读 本次分享的主题是“打造 LLMOps 时代的 Prompt 数据驱动引擎”。其中 LLMOps 想要表达的概念是 LLM for AIOps。AIOps 概念提出至少已有四年,从去年开始,在学术界出现了 LLMOps 的趋势,大家都在想把 LLM 用于 AIOps 来做运维,但中间会遇到一些挑战。本文将重点探讨在 Prompt 数据方面,LLMOps 可能遇到的一些挑战,及其解决方案。 
- 背景:从 AIOps 到 LLMOps 面临 prompt 挑战
- 打造 LLMOps Prompt application 引擎
- LLMOps 持续成长源动力:Prompt learning 数据飞轮
- 未来畅想 分享嘉宾|刘逸伦 华为文本机器翻译实验室 工程师 编辑整理|王甲君 内容校对|李瑶 出品社区|DataFun
01
背景:从 AIOps 到 LLMOps 面临 prompt 挑战****
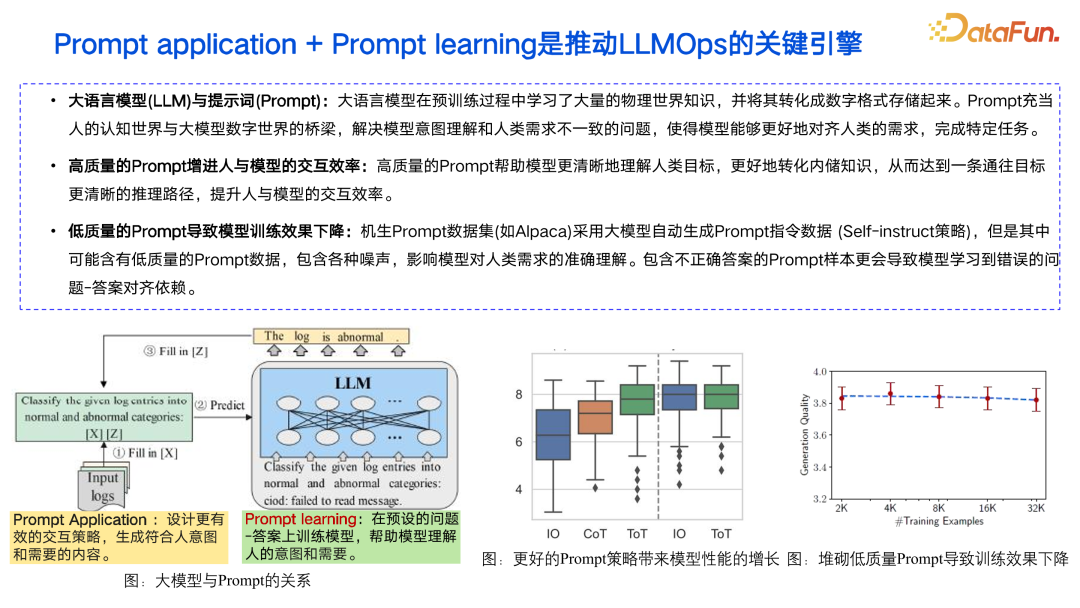

- 在 Prompt application 方面,传统智能运维算法依赖于任务数据,专家标注耗时耗力;且可解释性差,可交互性弱。
- 在 Prompt learning 方面,Prompt 训练数据质量不稳定,导致模型性能下降;训练数据全面性不足,影响了模型能力。 接下来将分别介绍我们为解决这些问题所做的工作。02****
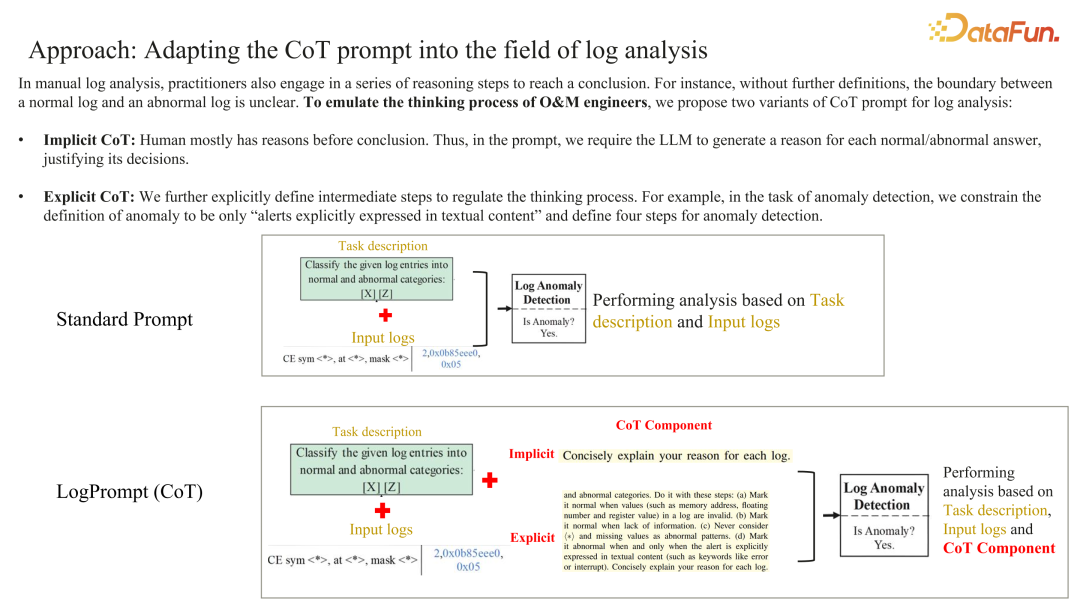
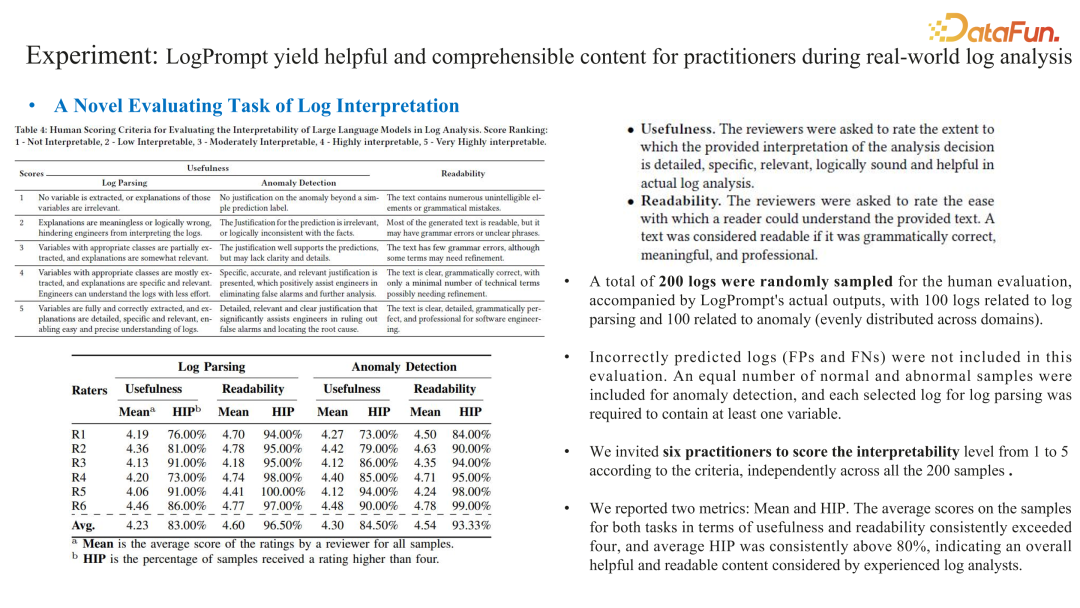
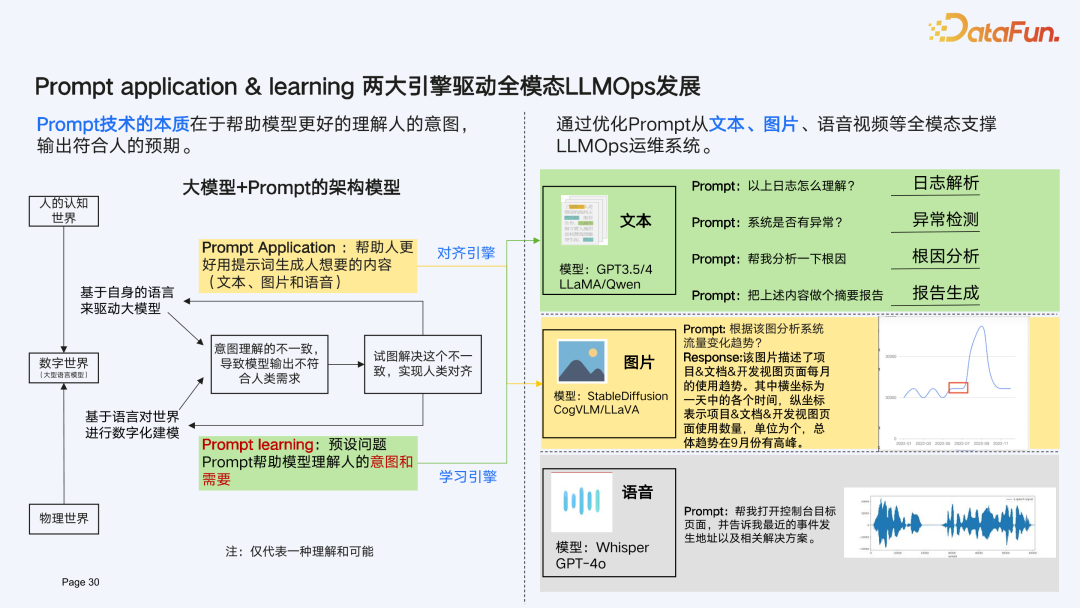
LogPrompt**:打造 LLMOps Prompt application 引擎******


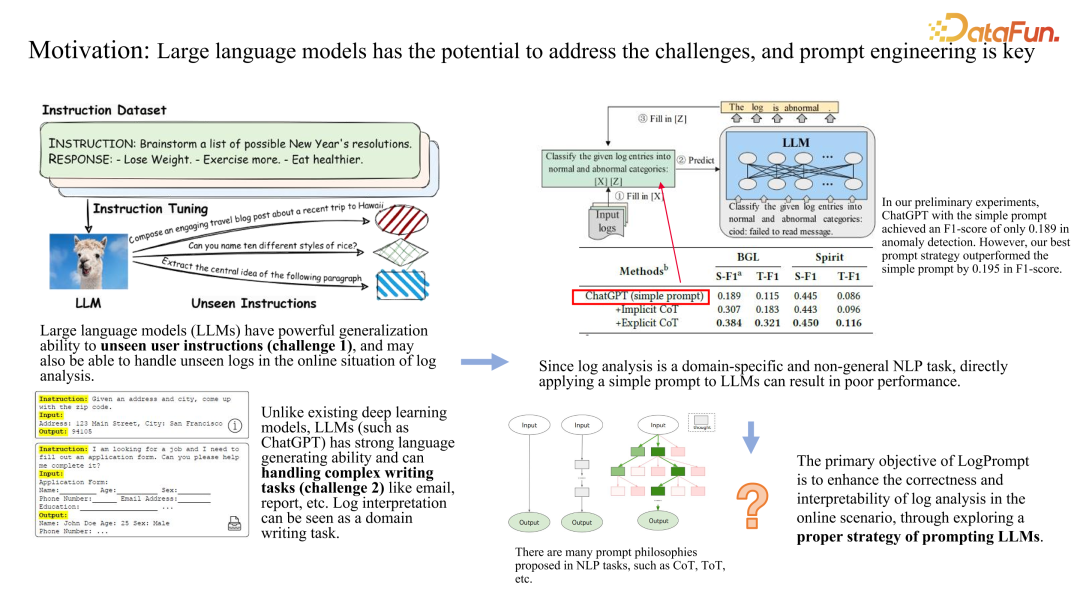







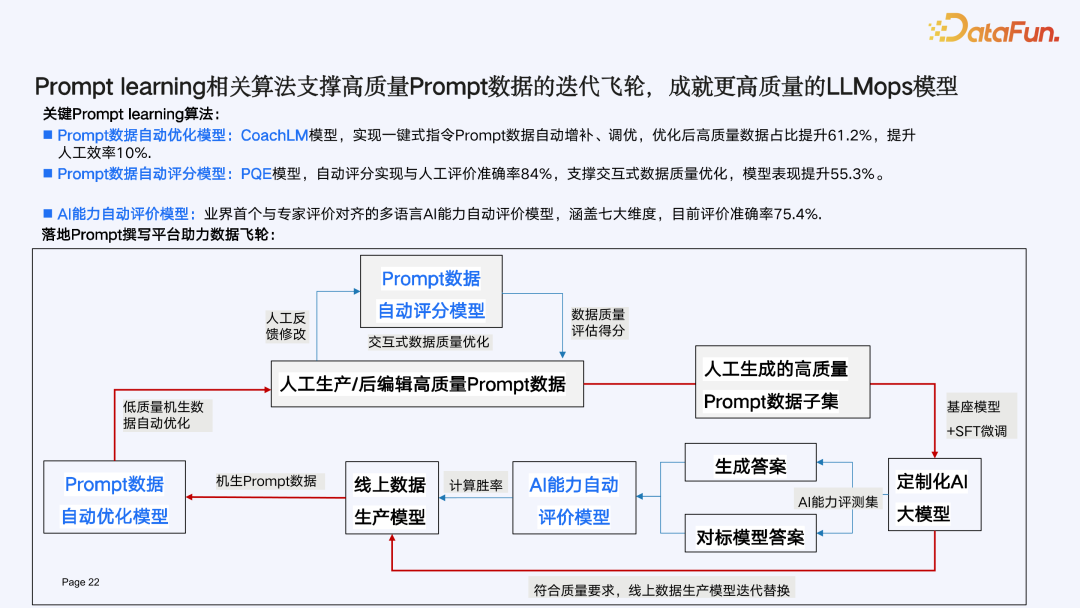
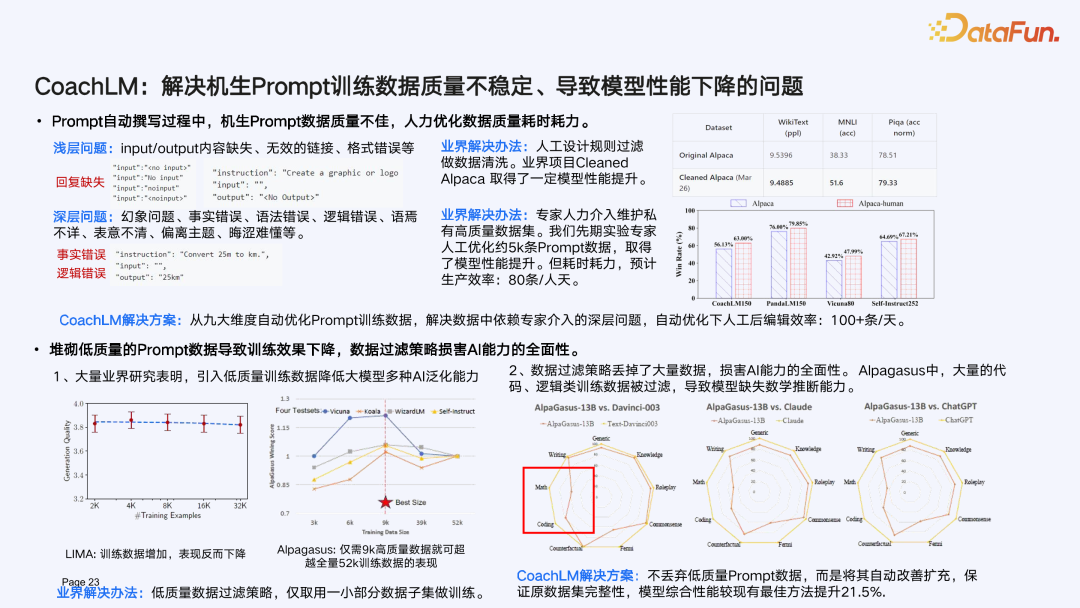
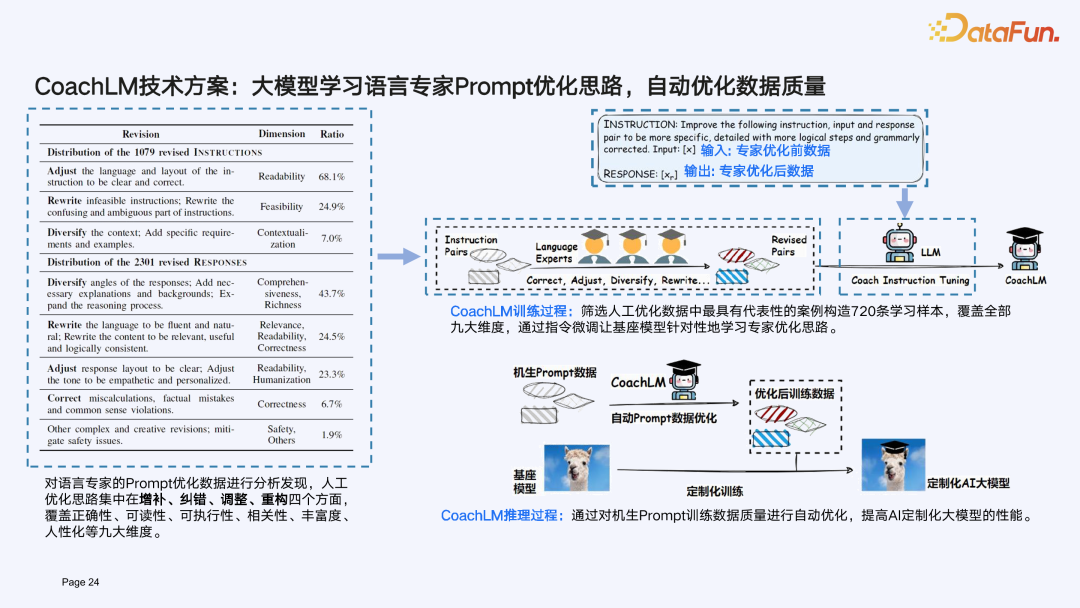
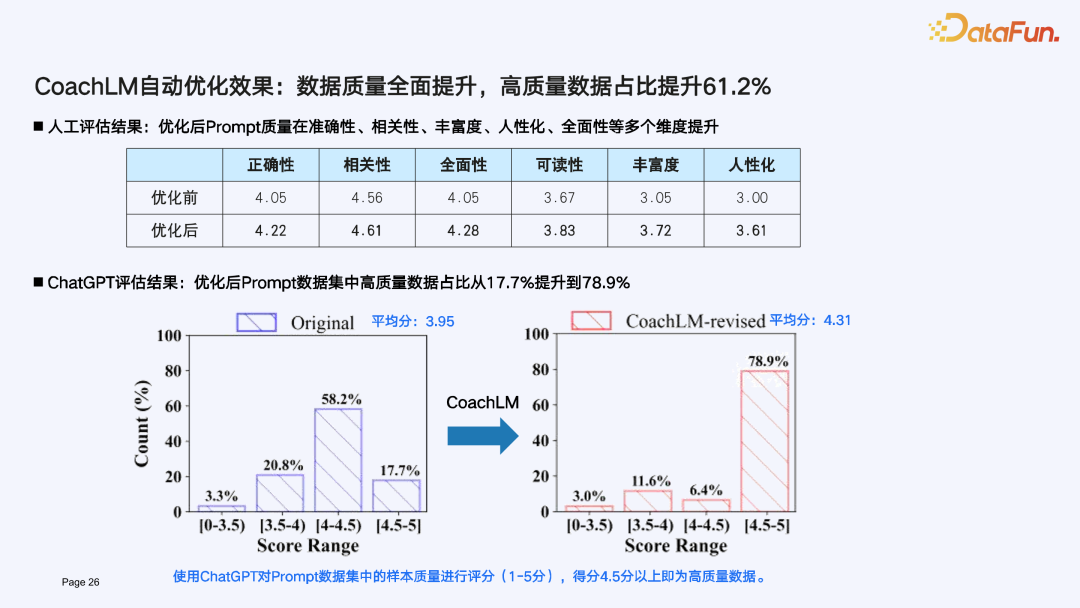
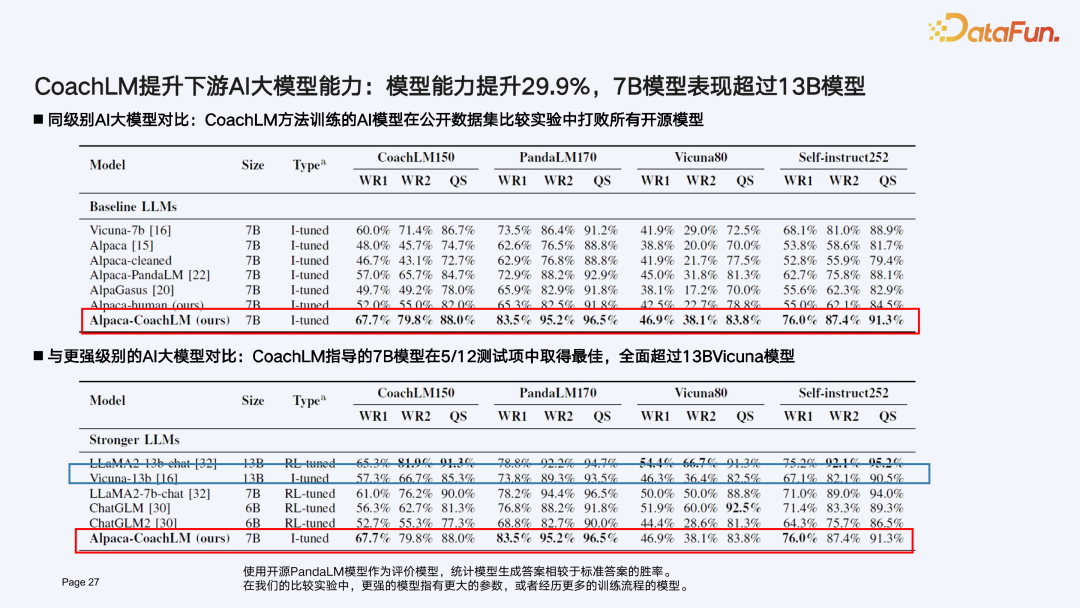
LLMOps 持续成长源动力:CoachLM 打造 Prompt learning 数据飞轮


未来畅想****

分享嘉宾
INTRODUCTION
刘逸伦
华为文本机器翻译实验室
工程师

本科毕业于南开大学,硕士毕业于美国佐治亚理工学院。研究方向包括 AI 智能运维,大模型质量评估以及大模型提示策略,在相关领域以第一作者、通讯作者身份发表十余篇顶级国际会议/期刊论文。