


导读 吾道科技(iWudao Tech)一直致力于将 AI 技术和金融领域知识相结合,面向一级市场提供金融大数据和资讯服务。站在 2024 年二季度,金融行业试水大模型应用已经一年半了,在以大模型为代表的 AI 技术驱动下,金融行业的众多技术路线、业务场景迎来升级。在这个大变革的时代下,本次分享将聚焦于文档智能在金融领域的应用。文章主要包括以下五大部分:
- 文档智能的技术范畴
- 金融领域的文档智能
- 文档分析与识别
- 文档理解
- 文档智能的未来展望 分享嘉宾|侯启予 南京吾道知信信息技术有限公司 技术预研负责人 编辑整理|方星泰 内容校对|李瑶 出品社区|DataFun
01
文档智能的技术范畴首先介绍一下文档智能技术范畴。 
- 图像处理:预处理得到高质量的文档页面图像,为后续版面分析和内容识别提供支撑。
- 版面分析:包含物理版面分析(即区域分割及分类)和逻辑版面分析(即阅读顺序判定),常见的区域类别有文本、表格、图形等,其中文本又可分为标题、段落、公式、附注等,表格分为有边框表格、无边框表格、部分边框表格等,图形分为流程图、结构图、数据图、印章、照片等。
- 内容识别:对版面分析输出的不同分割区域类型进行相对应的内容识别。其中对文本部分的识别称为光学字符识别即 OCR,OCR 一直是文档识别研究的中心和主线,通常分为文字检测和文字识别两个环节,近年来也有很多端到端的文本识别技术被提出。随着文本识别技术日趋成熟以及工业界对表格识别需求的日益增长,2019 年以来,表格识别的研究迅猛发展,主要分为自顶向下的行列分割方法、自底向上的单元格检测方法、由图片生成结构序列的端到端方法。另外还有图形识别、公式识别等,就不在这里一一列出。 文档智能的另一个领域是文档理解,是指对文档进行语义理解和信息抽取,过去通常作为文档分析与识别的重要下游任务,近年来多模态、多模态大模型以及 OCR-Free 的端到端文档理解技术开始涌现。 02****
金融领域的文档智能接下来介绍金融领域文档智能的意义和特点。



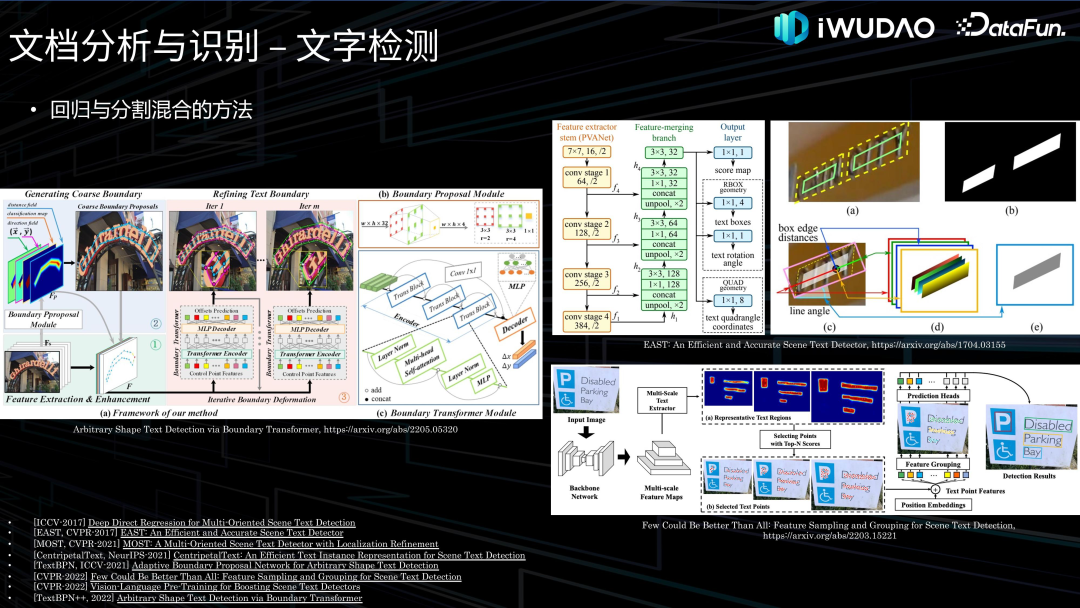
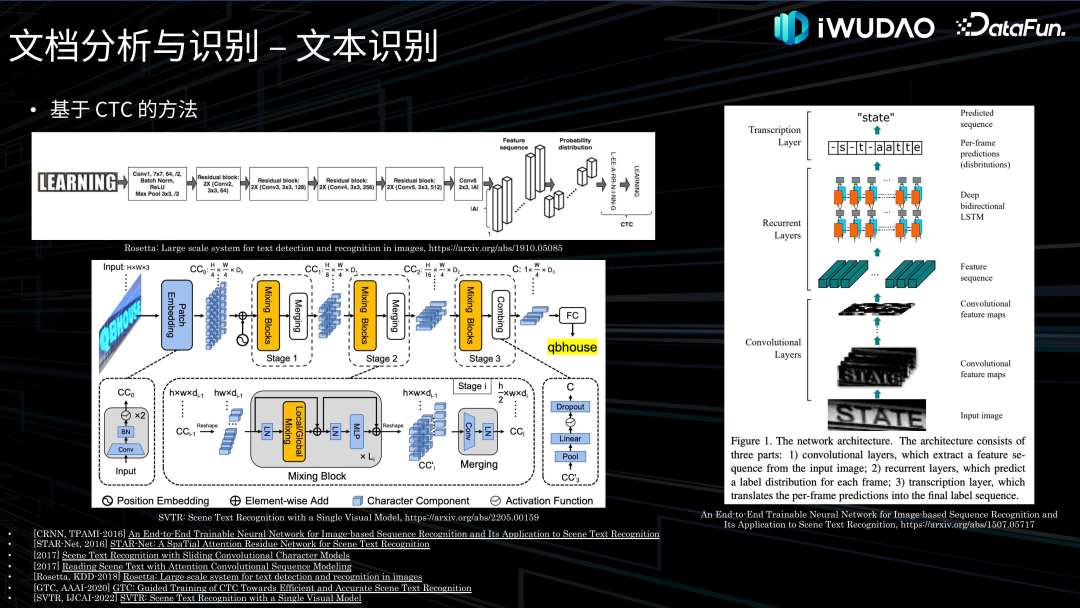
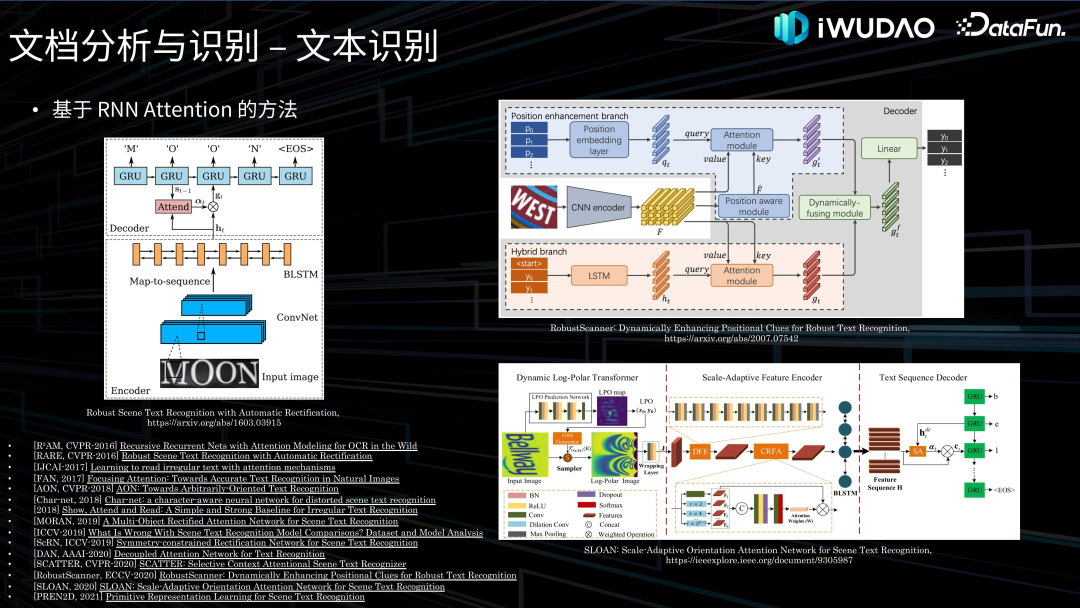
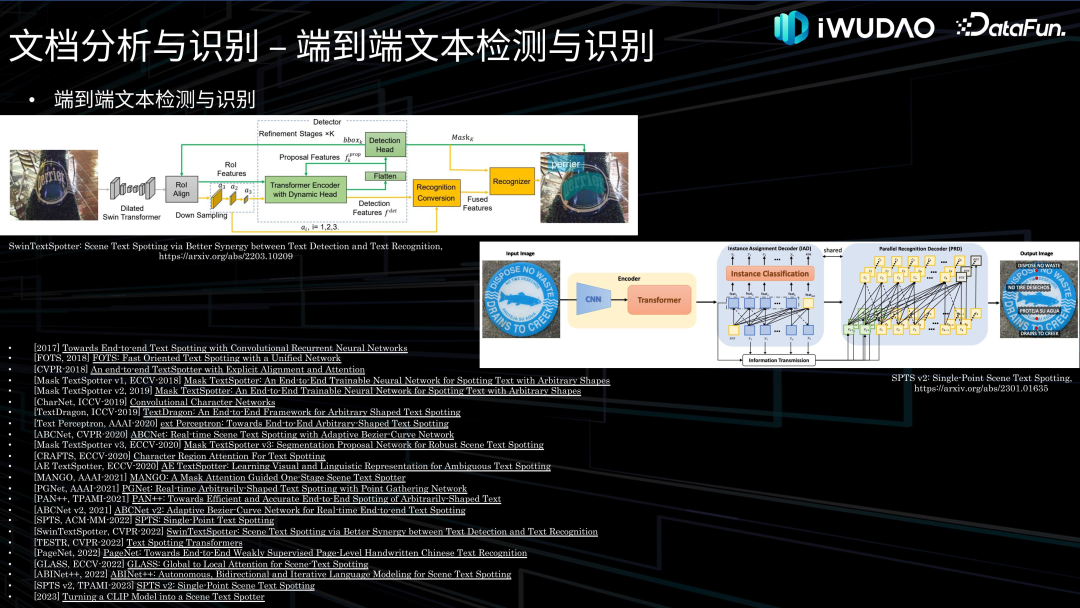
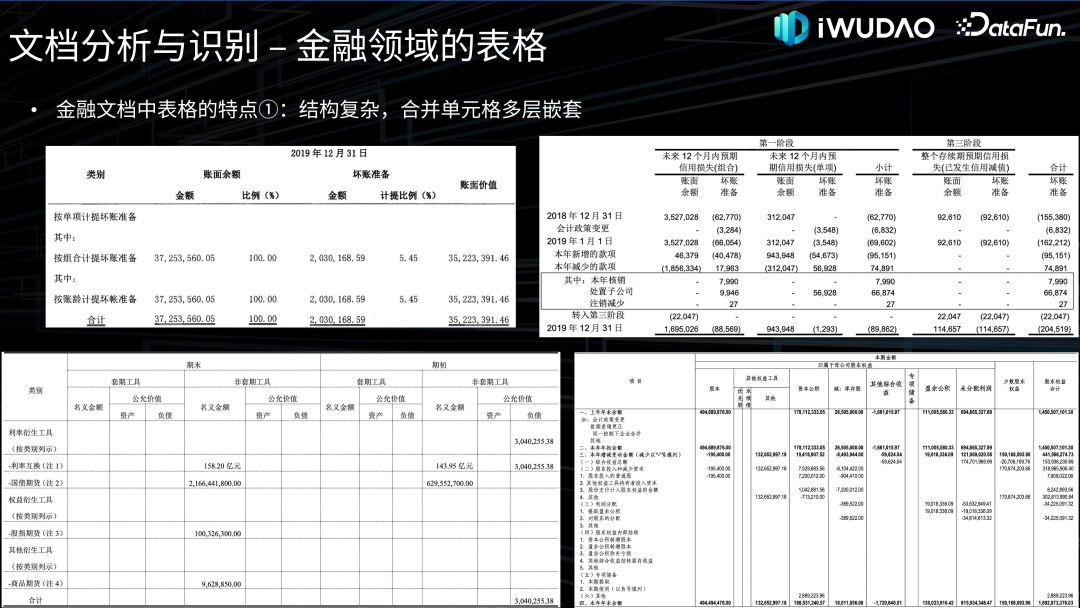
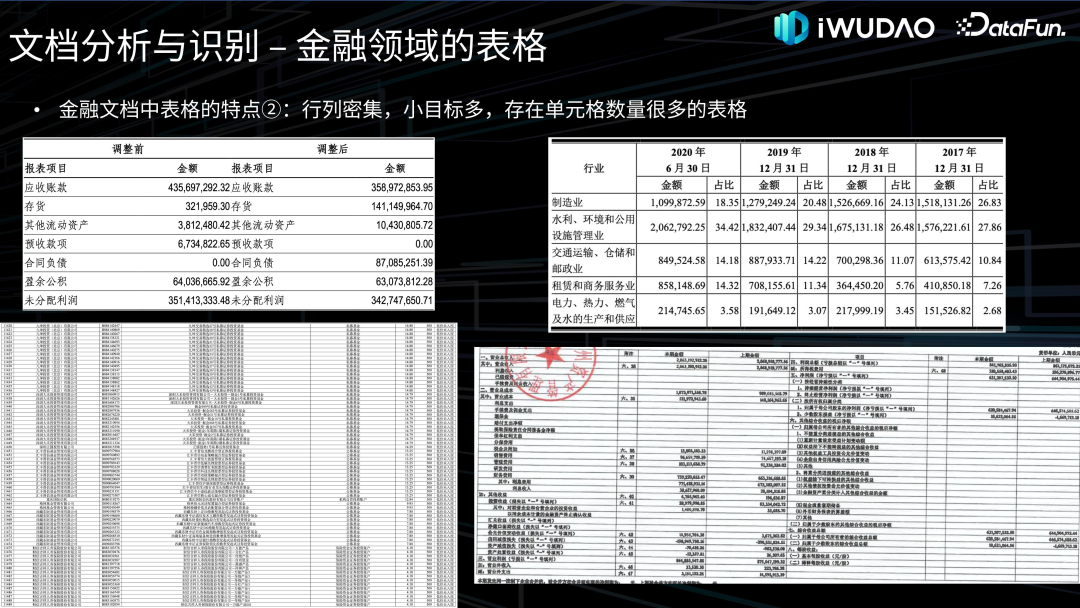
文档分析与识别**接下来对文档分析与识别的各项技术做一下归纳综述并介绍一下我们的探索。******1. 图像处理
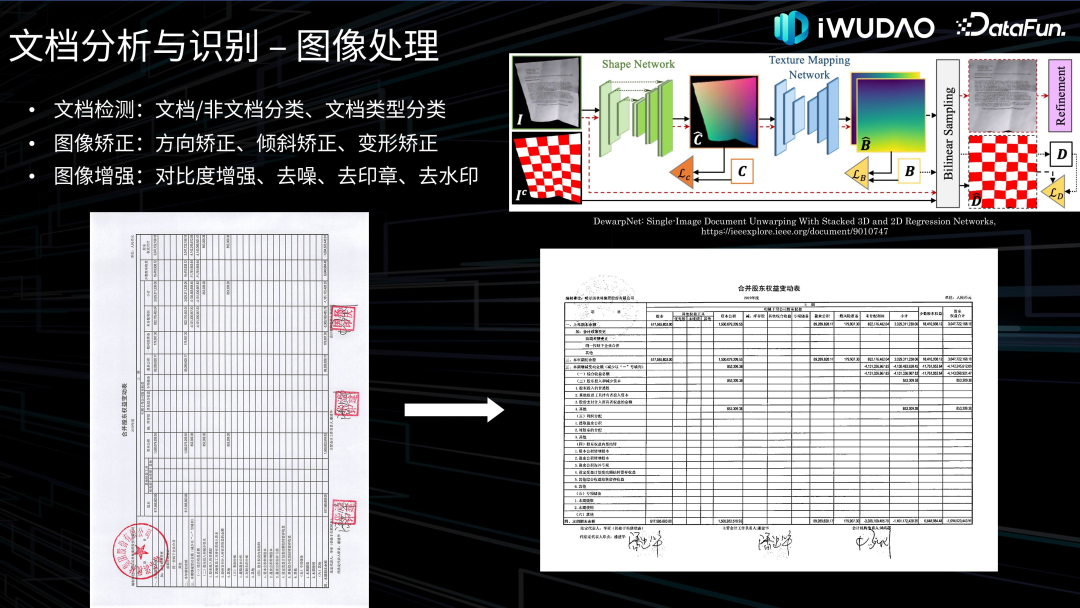
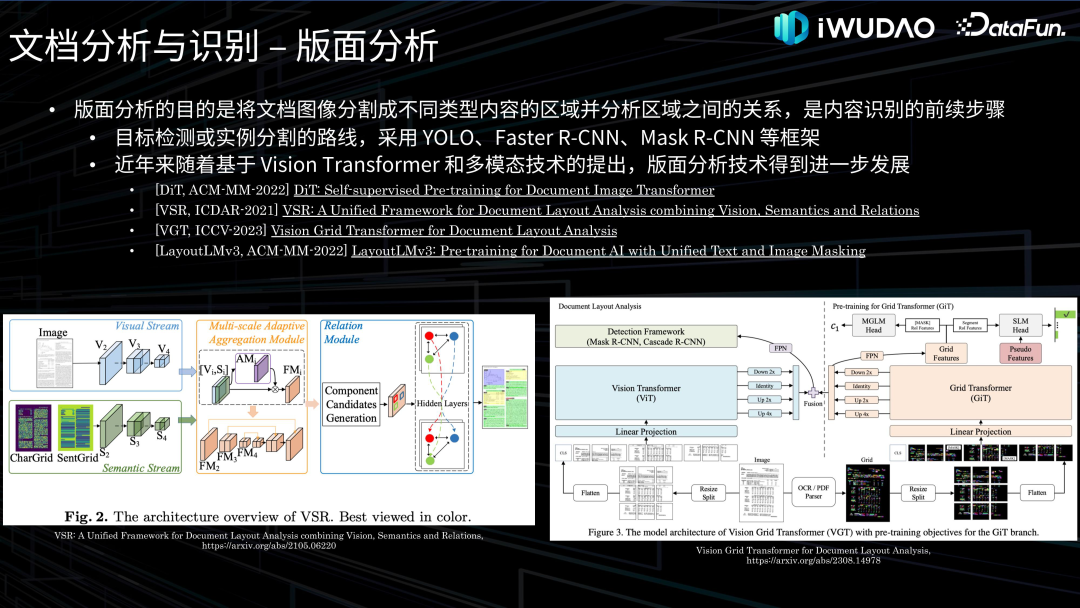


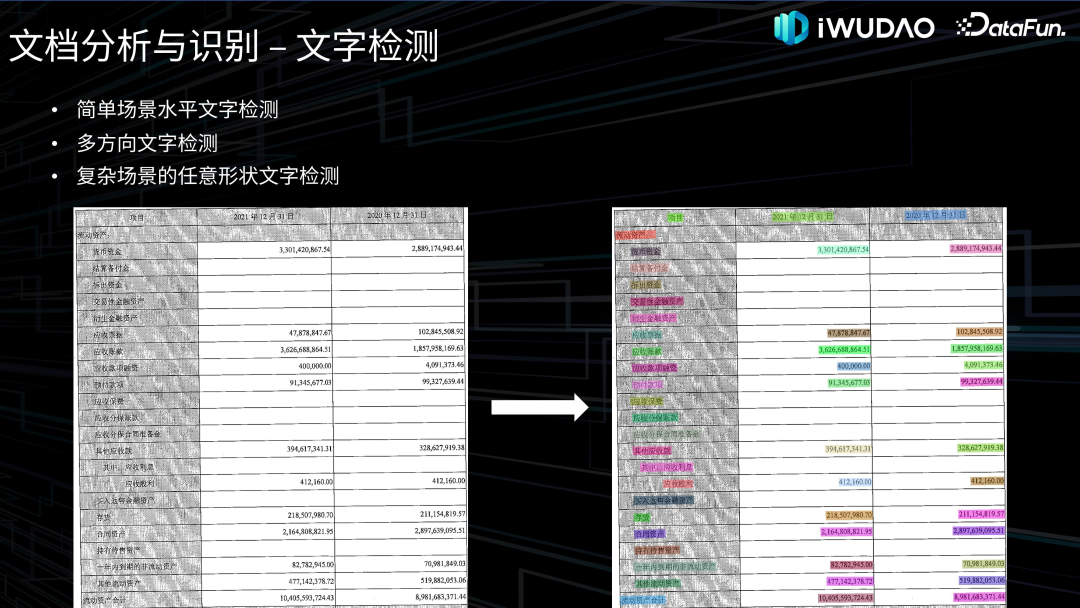
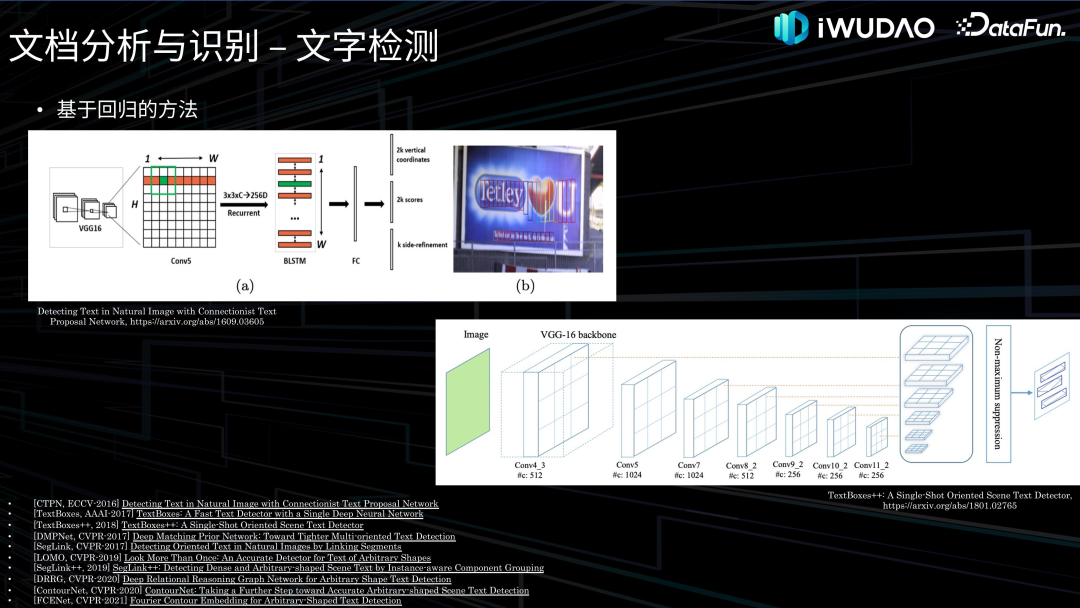



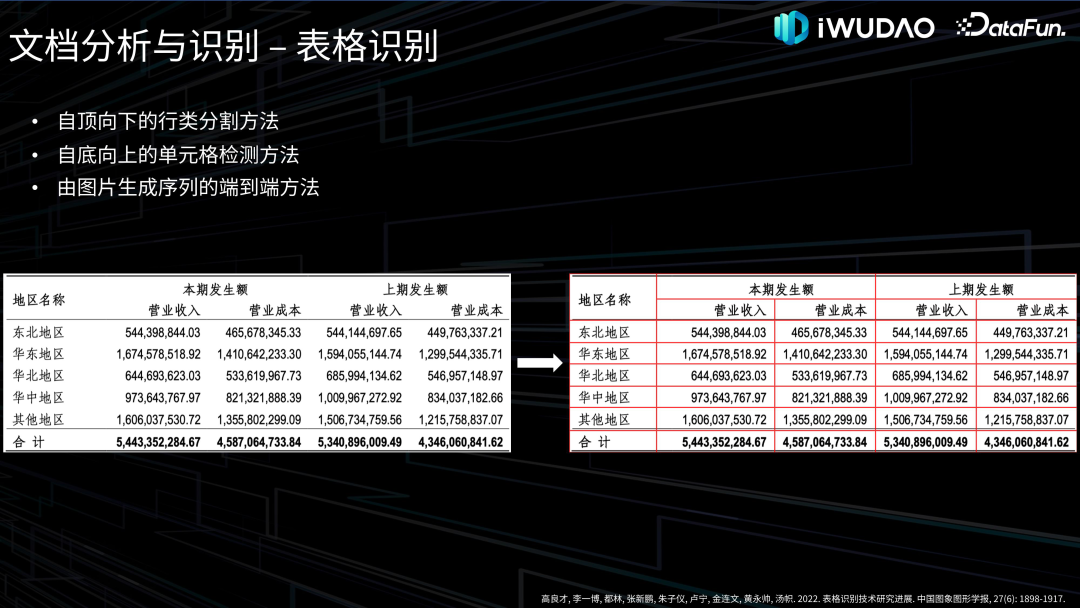
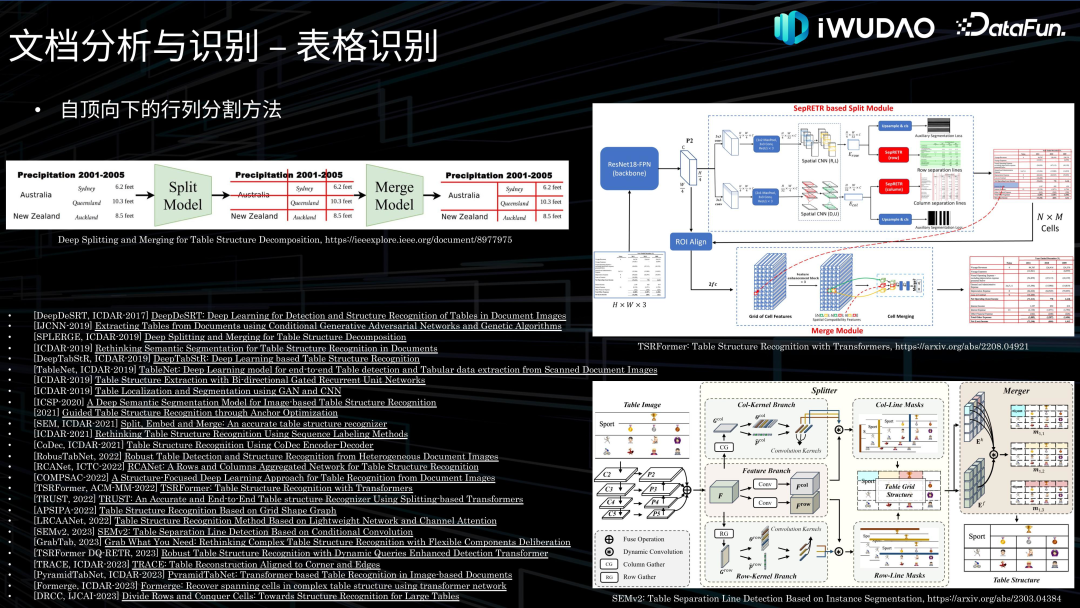
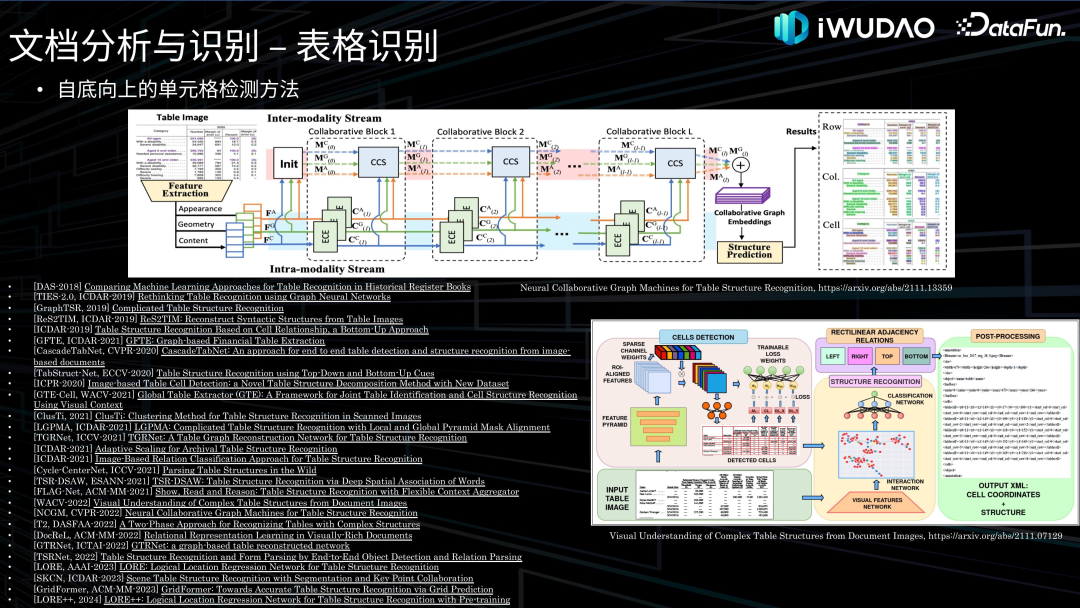
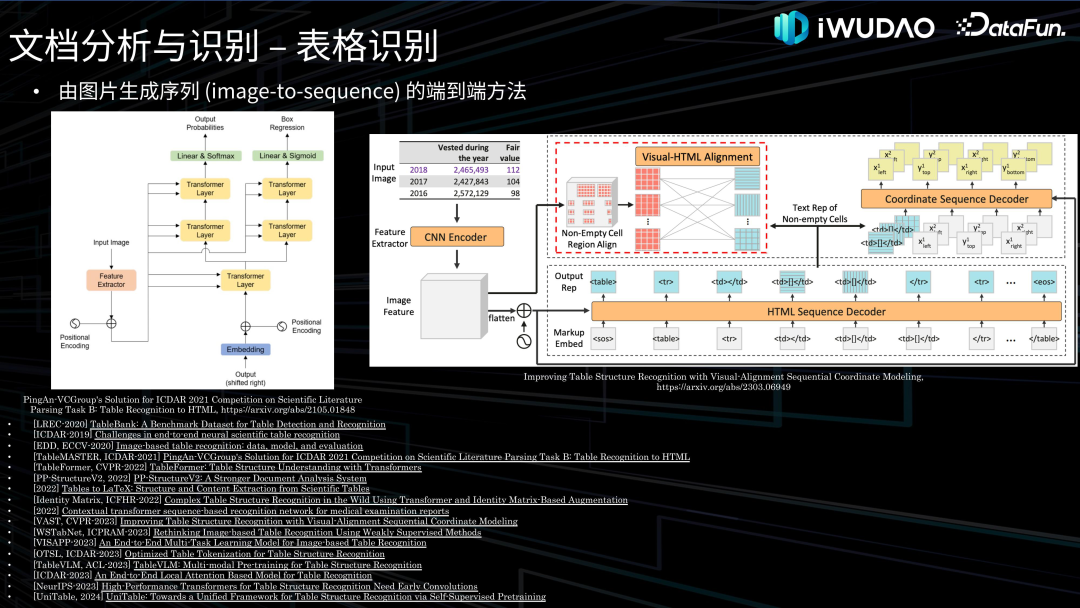


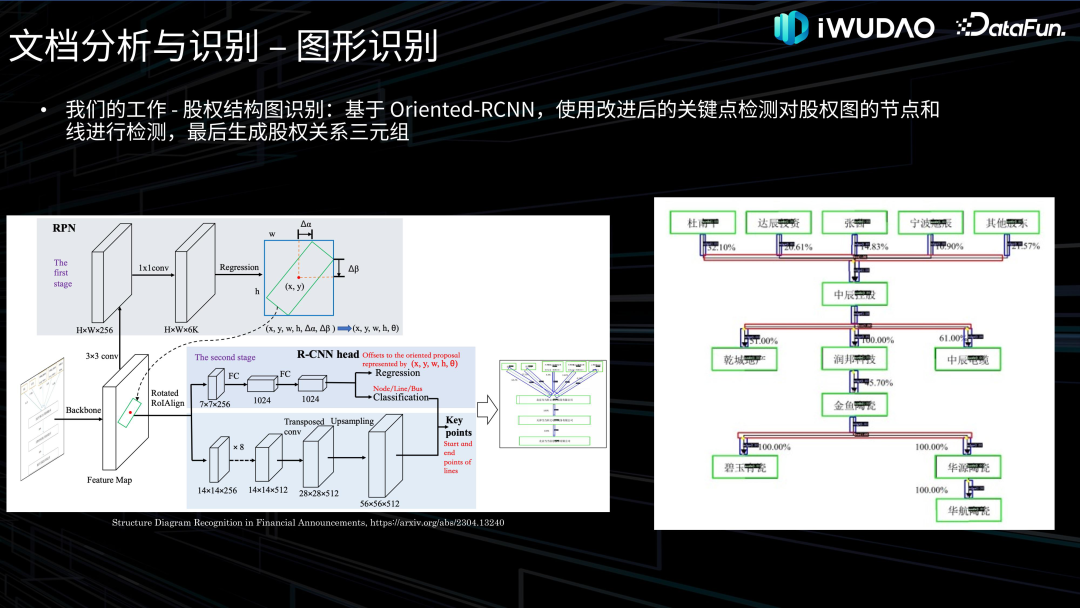
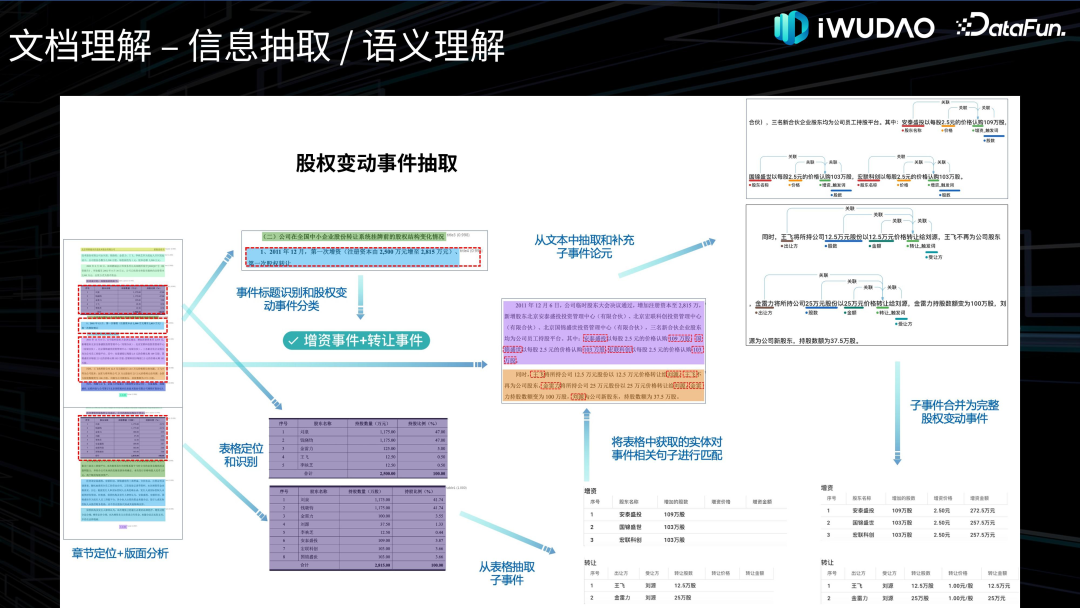
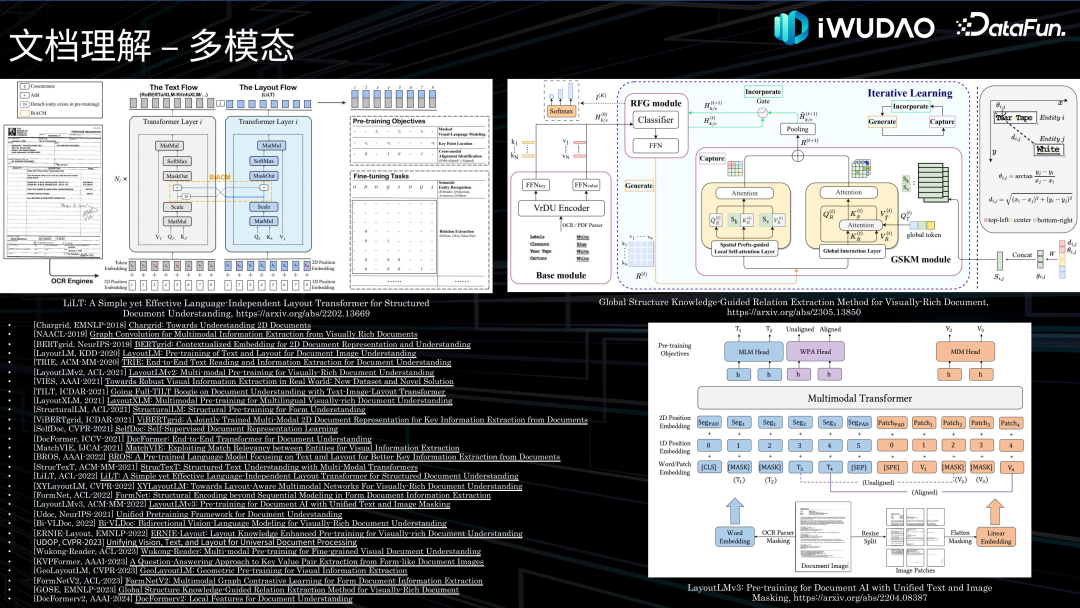
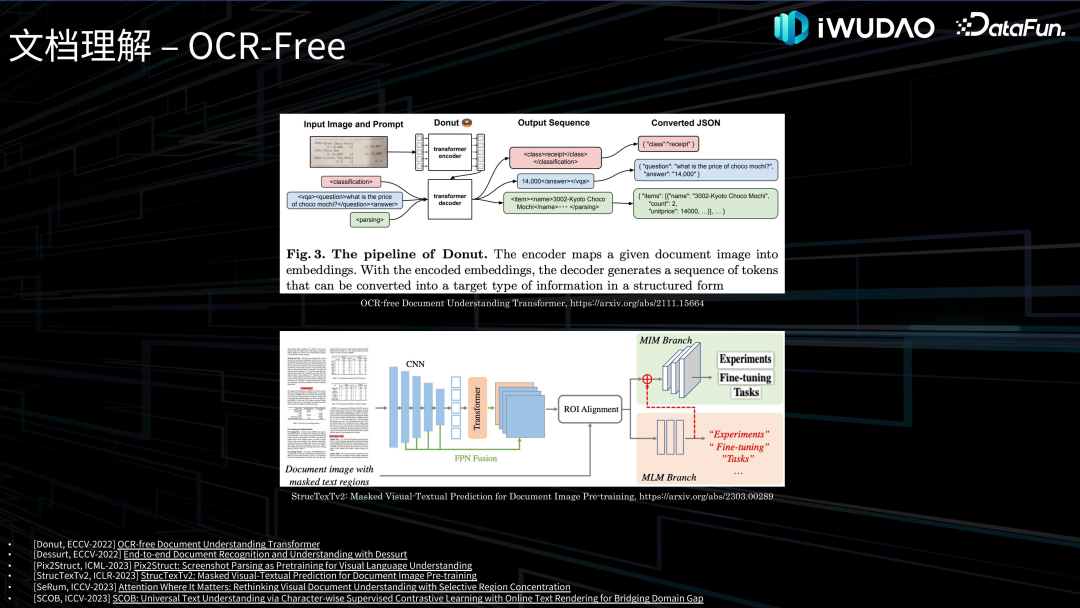
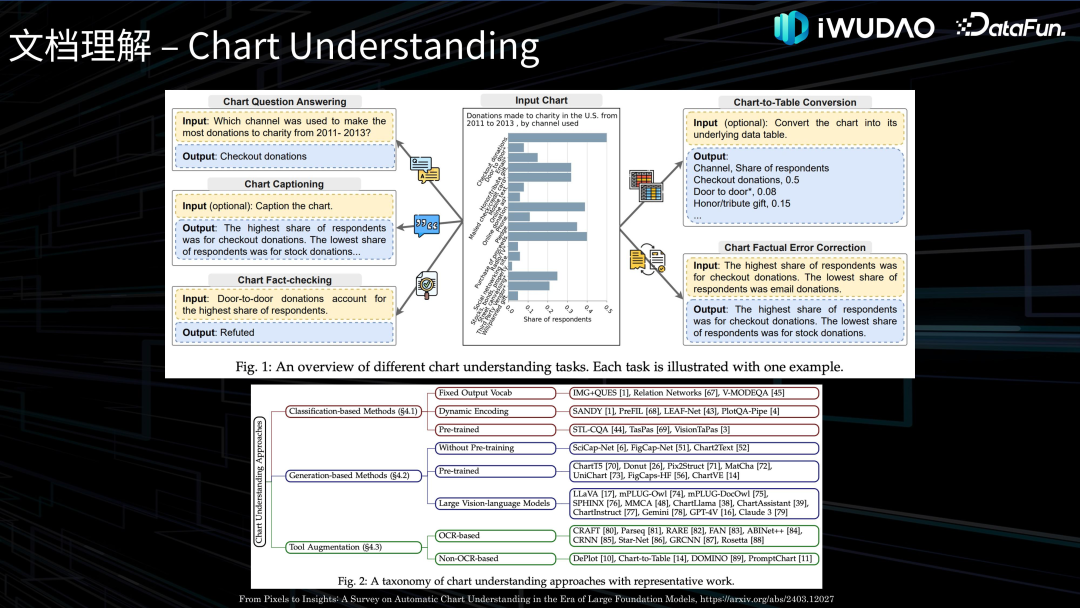
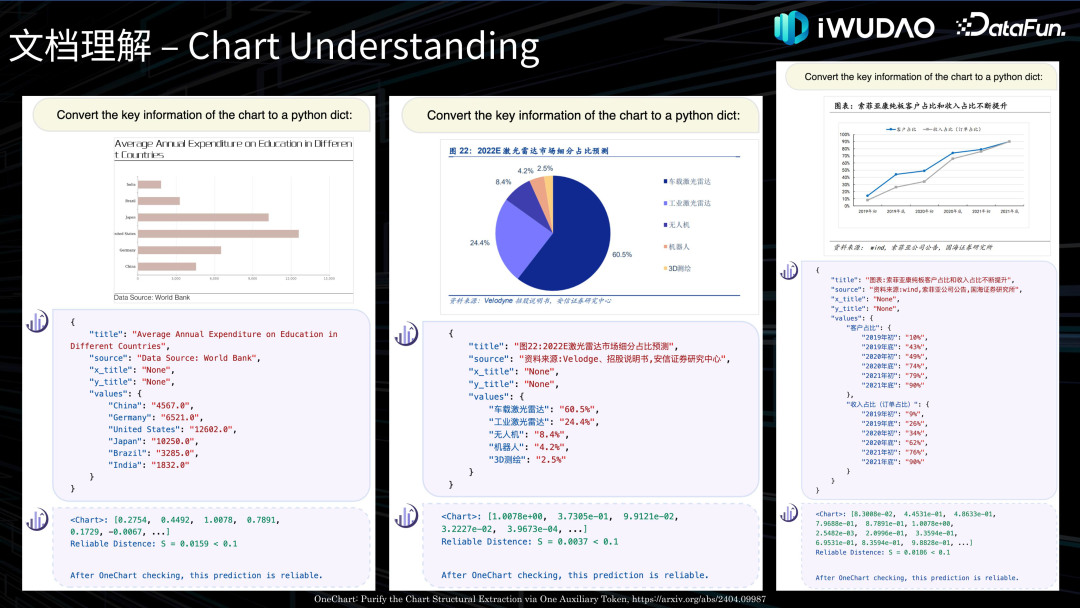
文档理解接下来介绍一下文档理解的相关技术。

文档智能未来展望最后探讨一下文档智能技术的未来发展趋势和展望。首先回顾一下文档智能在金融领域面临的挑战和问题:
- 金融行业是文档密集型的行业,有海量的公告、文书需要处理,金融文档种类繁多且复杂多样,如何构建能够泛化到不同金融文档类型的模型是目前面临的一大挑战。
- 金融文档通常页数很多,并且需要保持较高的分辨率,用基于深度学习或大模型的方法处理几百页的文档需要很多算力,如何快速响应是需要考虑的问题。
- 金融行业对数据安全性有极高的要求,如何保证模型尤其是大模型的可靠性和稳定性是工程落地需要思考的问题。 接着说下大模型技术给我的冲击和启示:
- ChatGPT 从发布到现在一年多,其发展速度说实话是比我想象中要快不少的,回看去年年初测试 davinci 和 codex 的实验文档,无论是从上下文长度、速度、价格还是效果来看都有非常大的进步,而多模态大模型和视觉大模型所拥有的理解能力也让我觉得很不可思议,我们的工作方式和技术路线都产生了巨大的变革。
- 大模型从技术上并不算是一个全新的概念,2020 年就发布了 GPT-3,但是感觉部署这样庞大的模型距离实际生产环境的落地还很远,所以继续聚焦在 BERT 为代表的常规预训练模型上,OpenAI 在发展很久还是局面不利的情况下依旧坚持 Autoregressive,是他们成功的原因。这也启示我要跳出局限的认知用发展的眼光看待技术。 最后讲一下我对未来的展望,抛出我的观点,我相信并且期望大模型可以一统江山,一个模型可以处理 NLP 和 CV 所有的任务,希望那一天早日到来。在学术研究迅速发展的同时,我们工业界也应该跟上节奏,提升对新技术的关注和敏感性,及时探索更多的落地场景和实际应用。以上就是本次分享的内容,谢谢大家。


分享嘉宾
INTRODUCTION

侯启予
南京吾道知信信息技术有限公司
技术预研负责人
吾道科技技术预研负责人,多年致力于 Document AI 领域相关工作。 往期推荐 基于 Native 技术加速 Spark 计算引擎 双核驱动的新质生产力,阿里云如何做? 阿里云大数据 AI 一体化最佳实践 机遇来了!大模型赋能服务助你突破企业发展瓶颈! 阿里妈妈基于因果结构学习的营销组合建模 在电商场景中,如何建设全链路数据血缘? 知乎基于Celeborn优化Spark Shuffle的实践 阿里云 PAI 大语言模型微调训练实践 大模型推荐系统的打怪升级之路! 从电商场景,看抖音集团数据治理实践


点个在看你最好看 SPRING HAS ARRIVED

