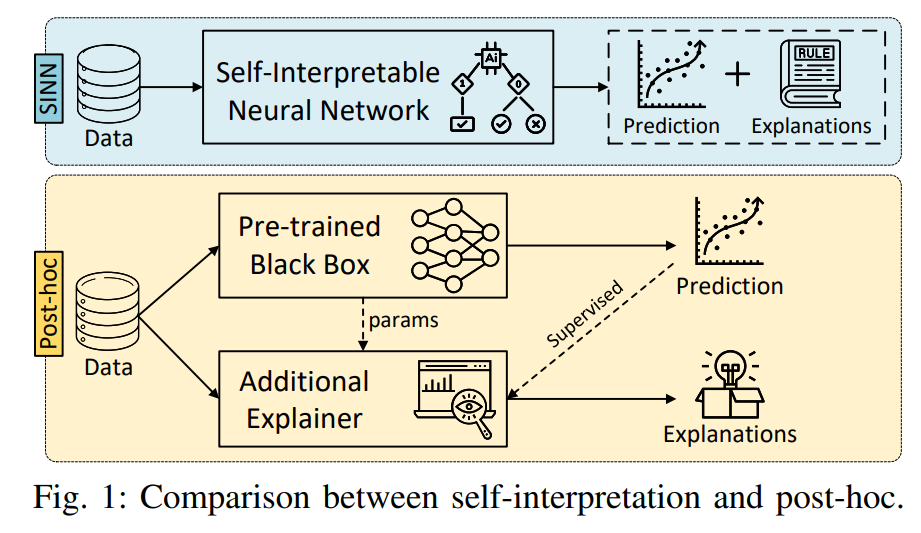
摘要—神经网络在各个领域取得了显著的成功。然而,缺乏可解释性限制了它们在实际应用中的使用,尤其是在关键决策场景中。事后可解释性(post-hoc interpretability)旨在为预训练模型提供解释,但通常面临鲁棒性和保真性的问题。这引发了对自解释神经网络(self-interpretable neural networks)的兴趣,该类网络通过模型结构本身内在地揭示预测的原理。尽管已有关于事后可解释性的调查,但关于自解释神经网络的全面系统性调查仍然缺乏。为了解决这一问题,我们首先收集并回顾了现有的自解释神经网络相关研究,并从五个关键视角对其方法进行结构化总结:基于归因的、自函数的、基于概念的、基于原型的和基于规则的自解释方法。我们还展示了具体的、可视化的模型解释示例,并讨论了它们在图像、文本、图数据和深度强化学习等多种场景中的适用性。此外,我们总结了现有的自解释性评估指标,并指出了该领域中的开放性挑战,为未来的研究提供了见解。为了支持这一领域的持续发展,我们提供了一个公开的资源,用于跟踪该领域的最新进展:https://github.com/yangji721/Awesome-Self-InterpretableNeural-Network。 关键词—可解释性;自解释神经网络;可解释人工智能;模型解释 I. 引言
在过去的十年中,神经网络在解决各个领域的复杂问题上取得了显著成功。这一成功主要得益于其广泛的假设空间,通过隐藏单元的深层信号传播得以实现。尽管神经网络具有出色的预测能力,但其缺乏可解释性仍然构成了重大挑战。在没有清晰理解模型如何得出决策的情况下,建立用户对模型预测的信任变得困难,尤其是在关键决策场景中。可解释人工智能(XAI)作为一个热门研究领域,旨在解决神经网络的可解释性问题。事后可解释性方法(post-hoc interpretability)已被广泛采用,旨在为预训练模型提供解释,提升模型透明度。这些方法旨在为预训练模型的预测生成人类可理解的解释。尽管这些方法具有灵活性,事后可解释性方法往往未能提供模型内部机制的透明视图[1],[2]。此外,它们通常计算开销较大,且难以忠实地捕捉预训练模型的真实行为[3]–[6]。正如最近的研究[7],[8]所强调的,模型固有的不透明性妨碍了对决策过程的理解。这一日益增强的对事后解释局限性的认识,推动了对能够本质上揭示预测推理的神经网络架构的需求。 传统的机器学习模型,如决策树和线性模型,自然具有可解释性。然而,它们的优化和学习范式与神经网络的范式有着根本的不同,限制了它们在当前以神经网络为主导的人工智能领域中的应用。例如,尽管决策树在特征预定义的分类任务中有效,但它们无法在神经网络的基于梯度的框架内工作,从而无法实现端到端的学习。这种不兼容性突显了探索自解释神经网络方法的必要性,这些方法既能保持深度模型强大的学习能力,又能提供固有的可解释性。 尽管已有众多综述讨论了神经网络中的可解释性技术,但它们要么专注于特定领域,要么仅涉及事后解释[9]–[13]。模型解释本身是一个主观且复杂的概念,常常因领域不同而显著变化,从而使得系统化总结变得困难。据我们所知,目前仍缺乏关于自解释神经网络(SINNs)的全面系统性综述。此外,该领域缺乏用于评估自解释性的统一总结,未来的研究方向仍未得到充分探索。 本文提供了对最先进自解释神经网络的全面综述。我们提出了一种分类法,将现有工作分为五个关键维度。这一分类设计基于这些网络架构中嵌入的各种解释形式。
- 基于归因的方法:识别哪些输入元素对模型预测的影响最大。
- 基于函数的方法:用更简单、透明的函数近似模型的函数,以理解内部变量之间的关系。
- 基于概念的方法:从人类可理解的概念角度解释模型,桥接模型的内部表示与领域相关概念之间的差距。
- 基于原型的方法:通过将输入与训练数据中学习到的代表性案例进行比较,提供模型预测的透明视图。
- 基于规则的方法:将逻辑规则引入神经网络架构中,实现符号推理。
为了进一步对这些方法进行背景阐述,我们讨论了广泛使用的可解释性技术,并突出了各个领域中新兴的研究方向,包括图像、文本、图数据和深度强化学习(DRL)。通过提供全面的综述,我们旨在为各种领域中的SINNs的实际应用、优点及潜在影响提供见解。 总结来说,我们的贡献如下:
- 新的分类法与系统性综述:我们提出了统一的视角,并对SINNs进行了最新的系统性综述。现有方法被分为五个类别。对于每个类别,我们抽象了其基础框架、可解释建模技术,并提供了详细的比较,突出了其优缺点。据我们所知,这是第一篇关于SINNs的系统性全面综述。
- 应用视角:为了更好地理解SINNs的实际应用,我们探索了它们在四个热门领域中的应用。我们提供了具体的模型解释示例,结合定制的解释技术,并讨论了一些趋势研究方向,如大型语言模型(LLMs)在这些领域中的应用。
- 定量评估指标:我们提供了对最先进的SINNs定量评估指标的全面概述,为研究人员提供了比较现有和新兴方法的具体指导和参考。
- 潜在的研究方向:我们对事后可解释性与自解释性之间的关系进行了全面分析与讨论,识别了未来模型设计和新应用场景的潜在研究方向。
本综述的其余部分将按以下结构组织:第二部分简要介绍术语和相关研究领域;第三部分介绍我们的SINNs分类法,并讨论这些网络中常用的结构;第四部分描述从主流应用角度常用的可解释性技术;第五部分提供定量性能评估指标;第六部分讨论自解释神经网络的有前景的研究方向;第七部分给出本文的结论。