

大型语言模型(LLMs)展现了显著的能力,但在进行复杂知识推理时,常常会出现幻觉现象和知识过时的问题,导致生成事实错误的输出。此前的研究尝试通过从大规模知识图谱(KGs)中检索事实性知识来帮助LLMs进行逻辑推理和答案预测。然而,这种方法常常引入噪音和无关数据,特别是在包含来自多个知识方面的大量上下文的情况下。在这种情况下,LLM的注意力可能会被误导,偏离问题和相关信息。
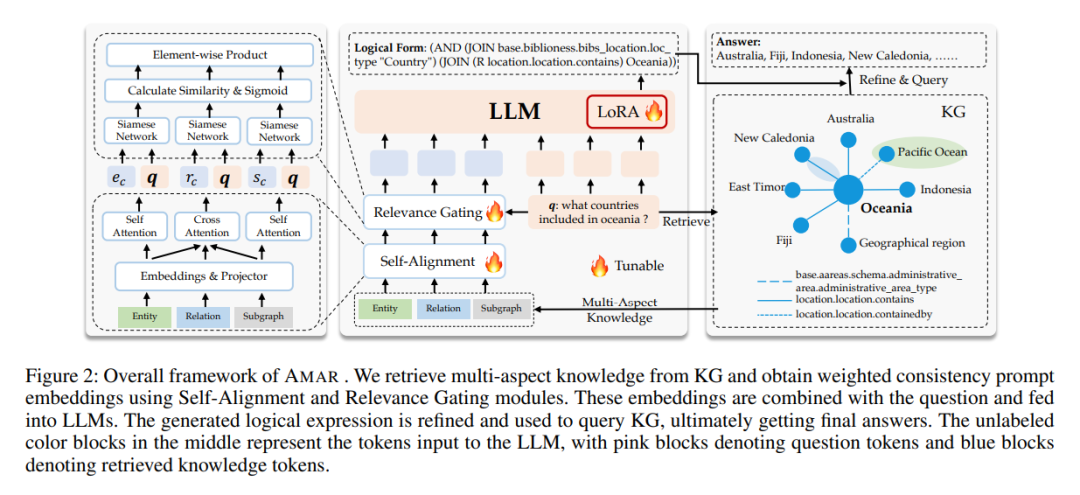
在我们的研究中,我们提出了一个基于知识图谱(KGs)的自适应多方面检索增强(AMAR)框架。该方法检索包括实体、关系和子图的知识,并将每一条检索到的文本转换为提示嵌入。AMAR框架包含两个关键子组件:1)自对齐模块,旨在对齐实体、关系和子图之间的共性,以增强检索文本,从而减少噪音干扰;2)相关性门控模块,采用软门控机制学习问题与多方面检索数据之间的相关性评分,以确定哪些信息应该被用来增强LLM的输出,甚至是完全过滤掉。
我们的方法在两个常见数据集WebQSP和CWQ上达到了最新的性能,准确率比最强竞争者提高了1.9%,在逻辑形式生成方面比直接使用检索文本作为上下文提示的方法提高了6.6%。这些结果展示了AMAR在提升LLM推理能力方面的有效性。
代码 — GitHub: Applied-Machine-Learning-Lab/AMAR
成为VIP会员查看完整内容
相关内容
Arxiv
183+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
183+阅读 · 2023年4月7日