© 作者|刘恩泽 机构|中国人民大学研究方向|推荐系统 随着大语言模型的迅速发展,生成式推荐作为一种有前景的新范式备受关注,因此本文聚焦生成式推荐领域挑选了十篇最新的相关工作。
文章也同步发布在 AI Box 知乎专栏(知乎搜索 AI Box 专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!
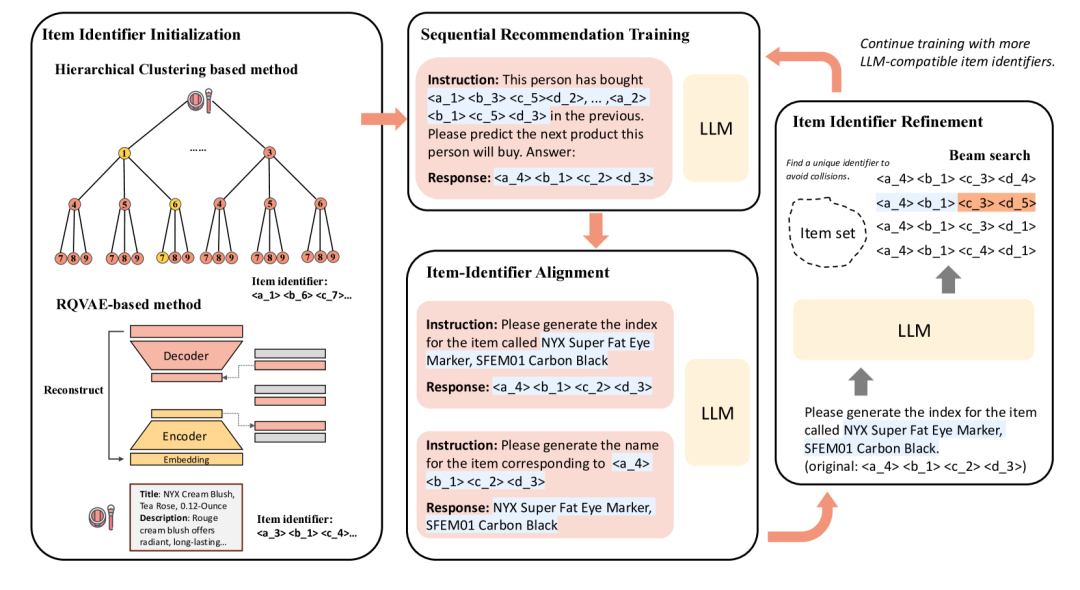
Enhancing Item Tokenization for Generative Recommendation through Self-Improvement
https://arxiv.org/abs/2412.17171 由大型语言模型(LLMs)驱动的生成式推荐系统,通过将物品建模为标记序列并以生成式方法进行推荐,提供了一种创新的用户偏好预测方式。该方法中的一个关键挑战是物品的有效标记化,确保其以与LLMs兼容的形式表示。当前的物品标记化方法包括使用文本描述、数字字符串或离散标记序列。虽然基于文本的表示与LLM的标记化无缝集成,但它们通常过于冗长,导致效率低下并增加了准确生成的复杂性。数字字符串虽然简洁,但缺乏语义深度,无法捕捉有意义的物品关系。将物品标记为新定义标记的序列已获得关注,但通常需要外部模型或算法进行标记分配。这些外部过程可能与LLM内部预训练的标记化方案不一致,导致不一致性并降低模型性能。为了解决这些限制,我们提出了一种自我改进的物品标记化方法,允许LLM在训练过程中优化其自身的物品标记。我们的方法从任何外部模型生成的物品标记开始,并根据LLM学习到的模式定期调整这些标记。这种对齐过程确保了标记化与LLM对物品的内部理解之间的一致性,从而产生更准确的推荐。此外,我们的方法易于实现,并可以作为即插即用的增强功能集成到现有的生成式推荐系统中。在多个数据集上使用各种初始标记化策略的实验结果证明了我们方法的有效性,推荐性能平均提高了8%。
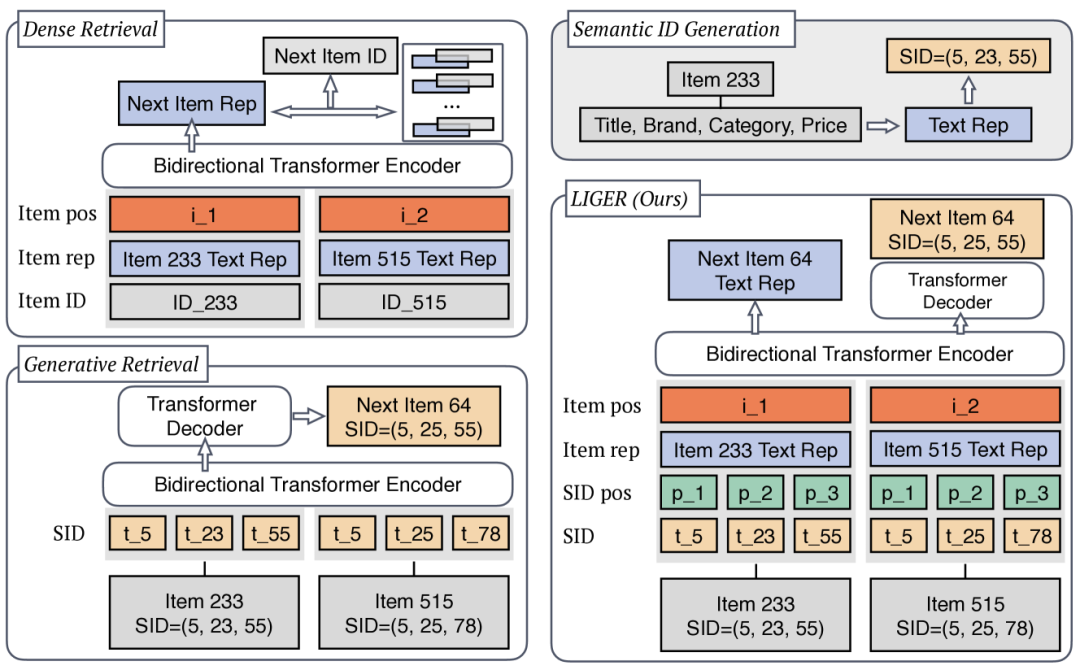
Unifying Generative and Dense Retrieval for Sequential Recommendation
https://arxiv.org/abs/2411.18814 序列密集检索模型利用先进的序列学习技术来计算物品和用户表示,然后通过用户与所有物品表示之间的内积计算来为用户排序相关物品。然而,这种方法需要为每个物品存储唯一的表示,随着物品数量的增加,会导致显著的内存需求。相比之下,最近提出的生成式检索范式提供了一种有前景的替代方案,它通过使用在包含物品语义信息的语义ID上训练的生成模型,直接预测物品索引。尽管生成式检索在大规模应用中具有潜力,但在公平条件下对生成式检索和序列密集检索进行全面比较的研究仍然缺乏,关于性能和计算权衡的问题仍未解决。为了解决这一问题,我们在学术基准上对这两种方法进行了受控条件下的比较,并提出了一种混合模型LIGER(LeveragIng dense retrieval for GEnerative Retrieval),该模型结合了这两种广泛使用方法的优势。LIGER将序列密集检索集成到生成式检索中,缓解了性能差异,并在评估的数据集中增强了冷启动物品推荐。这种混合方法为这些方法之间的权衡提供了见解,并在小规模基准测试中展示了推荐系统效率和有效性的提升。
Semantic Convergence: Harmonizing Recommender Systems via Two-Stage Alignment and Behavioral Semantic Tokenization
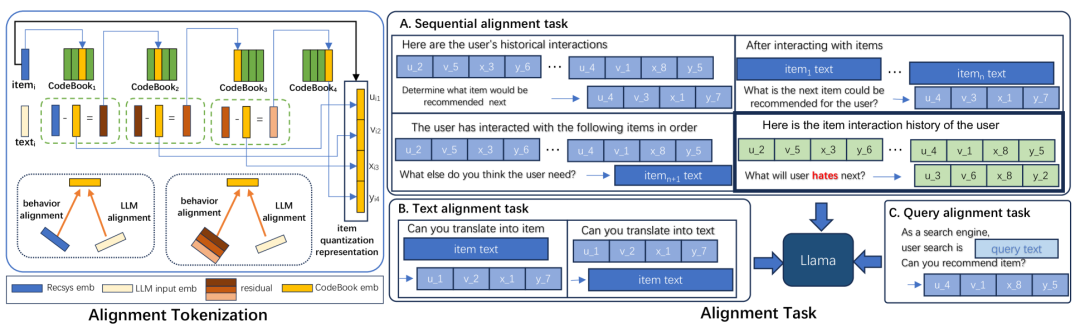
https://arxiv.org/abs/2412.13771 大型语言模型(LLMs)具备卓越的推理能力,能够从用户的历史行为中洞察深层次的兴趣,从而为推荐系统的发展提供了新的可能性。然而,推荐系统中常见的稀疏协同语义与LLMs中的密集标记表示之间仍存在显著差异。在本研究中,我们提出了一种新颖的框架,将传统推荐模型与LLMs的强大能力有机结合。我们通过提出的对齐标记化模块(Alignment Tokenization module),将ItemID转换为与LLMs语义空间对齐的序列,从而启动这一整合过程。此外,我们设计了一系列专门的监督学习任务,旨在将协同信号与自然语言语义的细微差别对齐。为了确保实际应用的可行性,我们通过预缓存每个用户的前K个结果来优化在线推理,从而降低延迟并提高效率。大量的实验证据表明,我们的模型显著提升了召回率指标,并展示了推荐系统卓越的可扩展性。
Preference Discerning with LLM-Enhanced Generative Retrieval
https://arxiv.org/abs/2412.08604 序列推荐系统旨在根据用户的交互历史为其提供个性化推荐。为了实现这一目标,这些系统通常会结合辅助信息,例如物品的文本描述,以及辅助任务,例如预测用户偏好和意图。尽管已经有许多努力来增强这些模型,但它们仍然面临个性化不足的问题。为了解决这一问题,我们提出了一种新的范式,称为偏好识别(preference discerning)。在偏好识别中,我们明确地将生成式序列推荐系统的上下文条件设定为用户偏好。为此,我们基于用户评论和物品特定数据,利用大型语言模型(LLMs)生成用户偏好。为了评估序列推荐系统的偏好识别能力,我们引入了一个新的基准测试,该基准测试提供了跨多种场景的全面评估,包括偏好引导和情感跟随。我们使用该基准测试评估了当前最先进的方法,并表明这些方法在准确识别用户偏好方面存在困难。因此,我们提出了一种名为Mender(多模态偏好识别器)的新方法,该方法改进了现有方法,并在我们的基准测试中实现了最先进的性能。我们的结果表明,即使训练过程中未观察到人类偏好,Mender也能有效地被人类偏好引导,从而为更加个性化的序列推荐系统铺平了道路。

Unleash LLMs Potential for Recommendation by Coordinating Twin-Tower Dynamic Semantic Token Generator
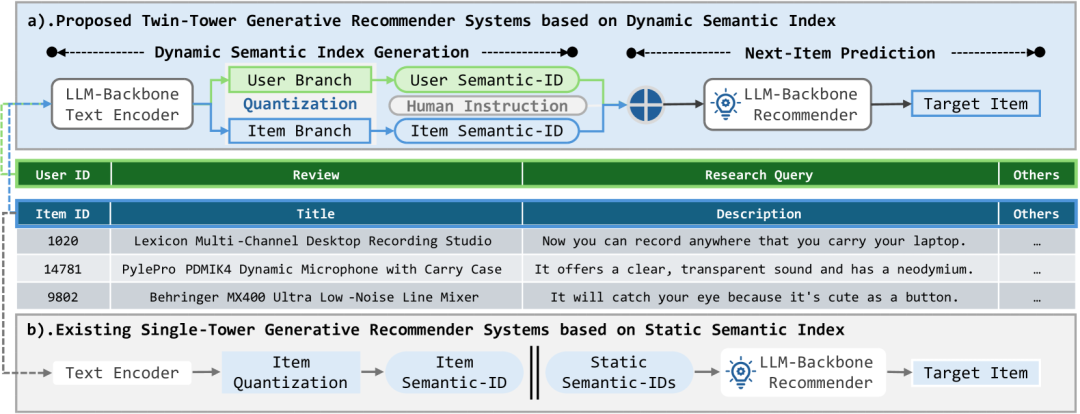
https://arxiv.org/abs/2409.09253 由于在语义理解和逻辑推理方面具备前所未有的能力,预训练的大型语言模型(LLMs)在开发下一代推荐系统(RSs)中展现了巨大的潜力。然而,当前方法采用的静态索引范式极大地限制了LLMs在推荐中的能力利用,不仅导致语义知识与协同知识之间的对齐不足,还忽视了高阶的用户-物品交互模式。本文提出了双塔动态语义推荐系统(TTDS),这是首个采用动态语义索引范式的生成式推荐系统,旨在同时解决上述问题。具体而言,我们首次设计了一个动态知识融合框架,将双塔语义标记生成器集成到基于LLM的推荐系统中,分层地为物品和用户分配有意义的语义索引,并据此预测目标物品的语义索引。此外,我们提出了一种双模态变分自编码器,以促进语义知识与协同知识之间的多粒度对齐。最后,我们提出了一系列专门定制的调优任务,用于捕捉高阶用户-物品交互模式,从而充分利用用户历史行为。在三个公开数据集上进行的大量实验证明了所提方法在开发基于LLM的生成式推荐系统中的优越性。与领先的基线方法相比,所提出的TTDS推荐系统在命中率(Hit-Rate)和归一化折损累计增益(NDCG)指标上分别平均提升了19.41%和20.84%。
Bridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other?
https://arxiv.org/abs/2410.16823 生成式检索在搜索和推荐领域是一种有前景的检索范式,它为依赖于外部索引和最近邻搜索的传统方法提供了一种替代方案。与这些传统方法不同,生成式模型直接将输入与物品ID关联起来。鉴于大型语言模型(LLMs)的突破性进展,这些生成式系统可以在一个单一模型中集中执行多种信息检索(IR)任务,例如查询理解、检索、推荐、解释、重排序和响应生成。尽管对IR系统采用这种统一的生成式方法的兴趣日益增长,但在文献中,使用单一多任务模型相对于多个专用模型的优势尚未得到充分验证。本文探讨了在搜索和推荐这两种广泛共存于多个工业在线平台(如Spotify、YouTube和Netflix)的IR任务中,这种统一方法是否以及何时能够优于特定任务模型。先前的研究表明:(1)生成式推荐器学习的物品潜在表示偏向于流行度;(2)基于内容和基于协同过滤的信息可以改进物品的表示。受此启发,我们的研究基于两个假设:[H1]联合训练能够规范化每个物品的流行度估计;[H2]联合训练能够规范化物品的潜在表示,其中搜索捕捉物品的基于内容的方面,而推荐捕捉基于协同过滤的方面。我们在模拟数据和真实数据上进行的大量实验支持了[H1]和[H2],这两者是统一搜索和推荐生成模型相对于单任务方法在效果提升方面的关键贡献因素。
CALRec: Contrastive Alignment of Generative LLMs for Sequential Recommendation
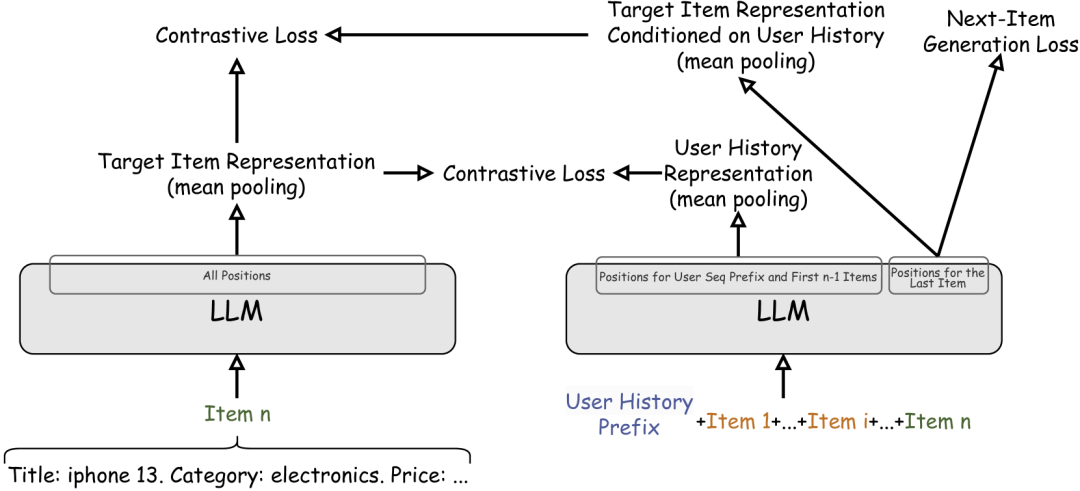
https://arxiv.org/abs/2405.02429 传统的推荐系统,如矩阵分解方法,主要专注于学习一个共享的密集嵌入空间来表示物品和用户偏好。随后,序列模型如RNN、GRU以及最近的Transformer相继出现,并在序列推荐任务中表现出色。这一任务需要理解用户历史交互中的序列结构,以预测用户可能喜欢的下一个物品。基于大型语言模型(LLMs)在多种任务中的成功,研究人员最近探索了使用在大量文本语料库上预训练的LLMs进行序列推荐。为了将LLMs用于序列推荐,用户交互历史和模型对下一个物品的预测都以文本形式表达。我们提出了CALRec,一个两阶段的LLM微调框架,该框架使用两种对比损失和语言建模损失的混合,以双塔方式对预训练的LLM进行微调:首先在多领域数据混合上进行微调,然后在目标领域进行另一轮微调。我们的模型显著优于许多最先进的基线方法(Recall@1提升37%,NDCG@10提升24%),并且我们的系统消融研究表明:(1)两个阶段的微调都至关重要,当结合使用时,我们能够实现性能的提升;(2)在我们实验探索的目标领域中,对比对齐是有效的。
Inductive Generative Recommendation via Retrieval-based Speculation
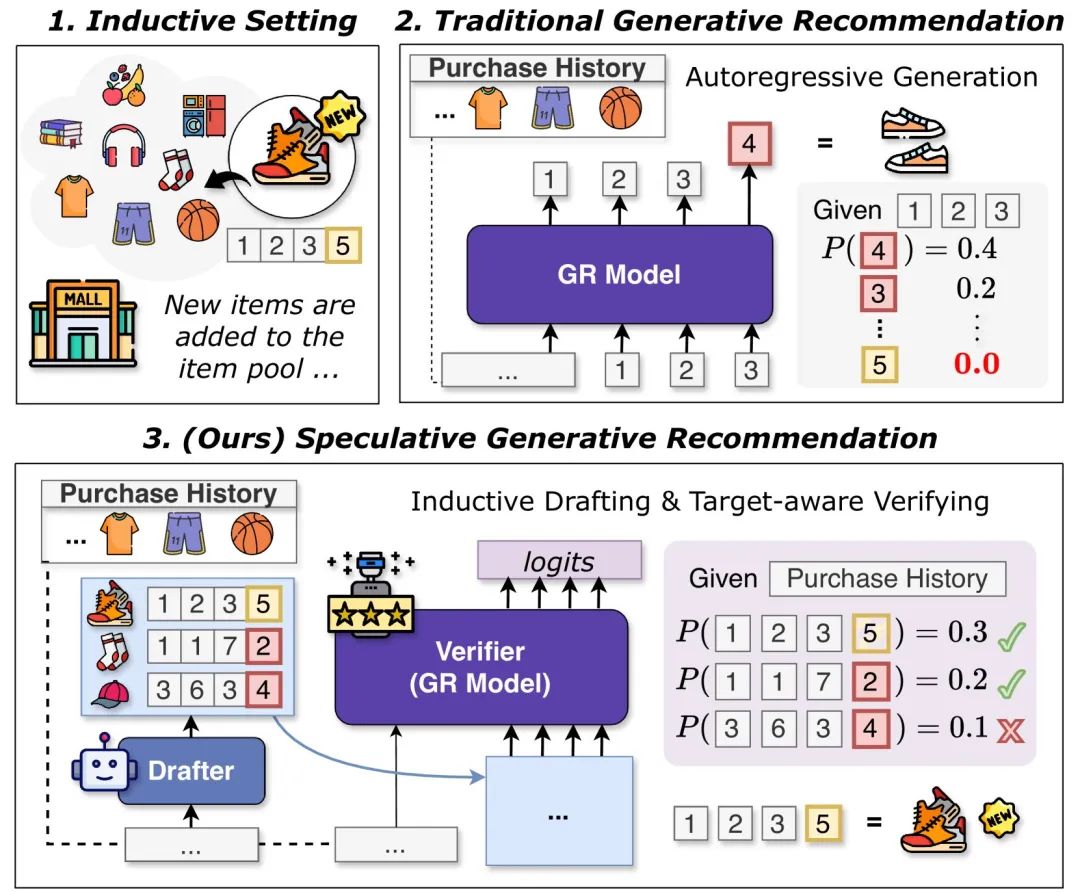
https://arxiv.org/abs/2410.02939 生成式推荐(GR)是一种新兴的范式,它将物品标记为离散的标记,并学习自回归生成下一个标记作为预测。尽管有效,GR模型在转导式设置下运行,这意味着它们只能生成训练期间见过的物品,而无法应用启发式重排序策略。在本文中,我们提出了SpecGR,一个即插即用的框架,使GR模型能够在归纳式设置下推荐新物品。SpecGR使用具有归纳能力的起草模型来提出候选物品,这些候选物品可能包括现有物品和新物品。然后,GR模型充当验证器,接受或拒绝候选物品,同时保留其强大的排序能力。我们进一步引入了引导式重起草技术,使提出的候选物品更符合生成式推荐模型的输出,从而提高验证效率。我们考虑了两种起草变体:(1)使用辅助起草模型以获得更好的灵活性,或(2)利用GR模型自身的编码器进行参数高效的自起草。在三个真实世界数据集上的大量实验表明,SpecGR不仅表现出强大的归纳推荐能力,而且在比较方法中具有最佳的整体性能。
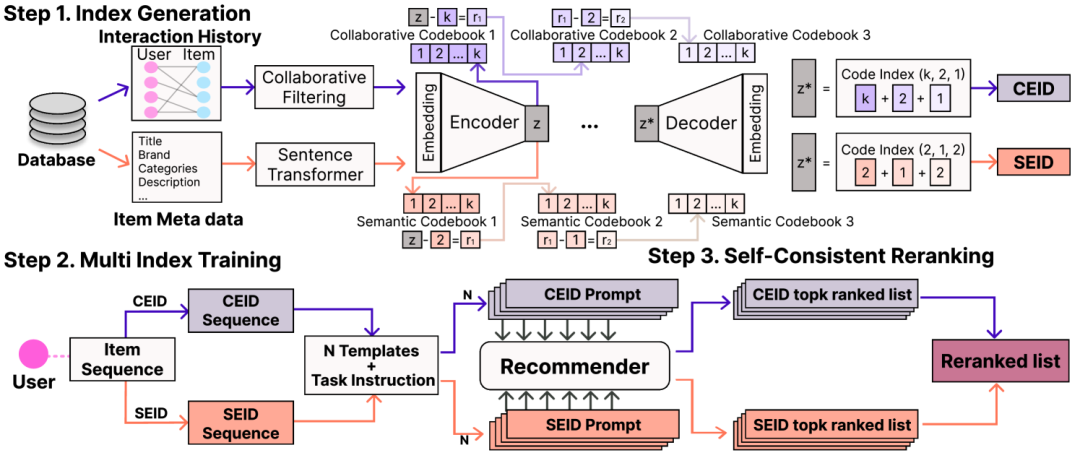
SC-Rec: Enhancing Generative Retrieval with Self-Consistent Reranking for Sequential Recommendation
https://arxiv.org/abs/2408.08686 语言模型(LMs)因其先进的语言理解和生成能力,越来越多地被应用于推荐系统中。最近基于生成式检索的推荐系统利用LMs的推理能力,根据用户交互历史中的物品序列直接生成下一个物品的索引标记。以往的研究主要集中在仅基于文本语义或协同信息的物品索引上。然而,尽管这些方面的独立有效性已得到证明,但这些信息的整合仍未得到充分探索。我们的深入分析发现,模型从异构物品索引和多样化输入提示中捕获的知识存在显著差异,这些差异具有很高的互补潜力。在本文中,我们提出了SC-Rec,一个统一的推荐系统,它从两种不同的物品索引和多个提示模板中学习多样化的偏好知识。此外,SC-Rec采用了一种新颖的重排序策略,该策略聚合了一组基于不同索引和提示推断的排序结果,以实现模型的自洽性。我们在三个真实世界数据集上的实证评估表明,SC-Rec显著优于现有的序列推荐方法,有效地整合了模型多样化输出的互补知识。
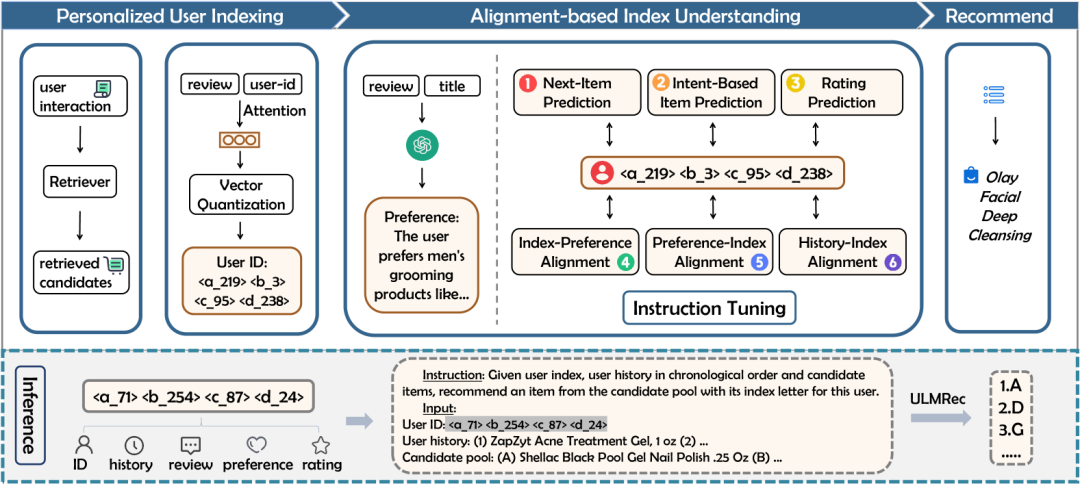
ULMRec: User-centric Large Language Model for Sequential Recommendation
https://arxiv.org/abs/2412.05543 近年来,大型语言模型(LLMs)在序列推荐任务中展现了出色的性能,这得益于其卓越的语言理解能力。然而,现有的基于LLM的推荐方法主要集中在建模物品级别的共现模式,而未能充分捕捉用户级别的个性化偏好。这是一个问题,因为即使表现出相似行为模式(例如点击或购买相似物品)的用户,其潜在兴趣也可能截然不同。为了缓解这一问题,本文提出了ULMRec,一个将用户个性化偏好有效整合到LLMs中以进行序列推荐的框架。考虑到物品ID与LLMs之间存在语义鸿沟,我们用用户历史行为中物品的标题替换物品ID,使模型能够捕捉物品语义。为了整合用户个性化偏好,我们设计了两个关键组件:(1)用户索引:一种个性化的用户索引机制,通过对用户评论和用户ID进行向量量化,生成有意义且唯一的用户表示;(2)对齐调优:一个基于对齐的调优阶段,采用全面的偏好对齐任务来增强模型捕捉个性化信息的能力。通过这一设计,ULMRec实现了语言语义与用户个性化偏好的深度融合,从而促进推荐的有效适应。在两个公开数据集上的大量实验表明,ULMRec显著优于现有方法,验证了我们方法的有效性。