视觉底层任务优秀开源工作:MMEditing 库使用方法

极市导读
本文整理自 MMEditing 原作者官方团队的关于 MMEditing 库的文档介绍,github 介绍以及相关知乎讲解,旨在对 MMEditing 库的特性和使用方法做一次汇总和梳理。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
目录
1 什么是 MMEditing 库
2 MMEditing 支持的模型库
3 安装 MMEditing
4 如何使用 MMEditing 开发自己的项目
5 OpenMMLab 的其他项目
6 致谢和引用
1 什么是 MMEditing 库
https://github.com/open-mmlab/mmediting/blob/master/README_zh-CN.md
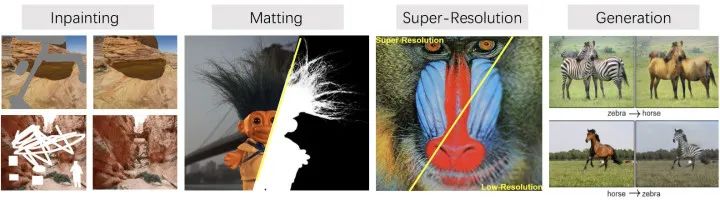
MMEditing 来自 OpenMMLab 项目,是基于 PyTorch 的图像和视频编辑开源工具箱。它目前包含了常见的编辑任务,比如图像修复,图像抠图,超分辨率和生成模型。在编辑图像或者视频的时候,我们往往是需要组合使用以上任务的,因此原作者们将它们整理到一个统一的框架下,方便大家使用。
作者团队:OpenMMLab 团队。http://openmmlab.com 社区Q群: 920178331。首先致敬大佬们!
本文整理自 MMEditing 原作者官方团队的关于 MMEditing 库的文档介绍,github 介绍以及相关知乎讲解,旨在对 MMEditing 库的特性和使用方法做一次汇总和梳理,算是个引子。 更多关于 1. MMEditing 代码解读,2. 如何使用等等的更多内容也欢迎大家参考下面的链接~ (持续更新)。
作者团队主页:
https://www.zhihu.com/people/openmmlab
官网教程:
https://mmediting.readthedocs.io/zh_CN/latest/
MMEditing 库链接:
https://github.com/open-mmlab/mmediting/blob/master/README_zh-CN.md
原作者知乎介绍:
https://zhuanlan.zhihu.com/p/178867385
https://zhuanlan.zhihu.com/p/393371989
MMEditing 的特点是:
-
功能全面: 涵盖经典的图像修复,图像抠图,超分辨率和生成模型算法,如 SRCNN, EDSR, ESRGAN, EDVR, CycleGAN 等等。 -
训练高效: 支持 DDP 多机多卡训练。 -
灵活设计: MMEditing 将编辑框架分解为不同的组件,并且可以通过组合不同的模块轻松地构建自定义的编辑器模型。 -
教程详尽: MMEditing 为大家提供了详细的使用方法官方教程。
2 MMEditing 支持的模型库
MMEditing 支持的全部模型及其相关论文可以参考原作者团队的文档:
图像修复总览 - MMEditing 文档图像修复(https://mmediting.readthedocs.io/zh_CN/latest/modelzoo.html)
-
Global&Local (ToG'2017) -
DeepFillv1 (CVPR'2018) -
PConv (ECCV'2018) -
DeepFillv2 (CVPR'2019)
图像抠图
-
DIM (CVPR'2017) -
IndexNet (ICCV'2019) -
GCA (AAAI'2020)
图像超分辨率
-
SRCNN (TPAMI'2015) -
SRResNet&SRGAN (CVPR'2016) -
EDSR (CVPR'2017) -
ESRGAN (ECCV'2018) -
RDN (CVPR'2018) -
EDVR (CVPR'2019) -
DIC (CVPR'2020) -
TTSR (CVPR'2020) -
GLEAN (CVPR'2021) -
LIIF (CVPR'2021)
视频超分辨率
-
TOF (IJCV'2019) -
TDAN (CVPR'2020) -
BasicVSR (CVPR'2021) -
BasicVSR++ (NTIRE'2021) -
IconVSR (CVPR'2021)
图像生成
-
CycleGAN (ICCV'2017) -
pix2pix (CVPR'2017)
视频插帧
-
CAIN (AAAI'2020)
MMEditing 支持的数据集同样可以参考下面链接,主要包含:
图像生成数据集
图像补全数据集
抠图数据集
超分辨率数据集
https://mmediting.readthedocs.io/zh_CN/latest/datasets.html
3 安装 MMEditing
完整的安装教程见作者团队提供的文档:
https://mmediting.readthedocs.io/zh_CN/latest/install.html#id2
需要的依赖库:
-
Linux (目前 Windows 暂无官方支持) -
Python 3.6+ -
PyTorch 1.3 或更高 -
CUDA 9.0 或更高 -
NCCL 2 -
GCC 5.4 或更高 -
mmcv
a 创建并激活 conda 虚拟环境:
conda create -n open-mmlab python=3.7 -y
conda activate open-mmlab
b 按照 PyTorch 官方文档 安装 PyTorch 和 torchvision:
确保 CUDA 编译版本和 CUDA 运行版本相匹配。用户可以参照 PyTorch 官网 对预编译包所支持的 CUDA 版本进行核对。
例1:如果 /usr/local/cuda 文件夹下已安装了 CUDA 10.1 版本,则需要安装 CUDA 10.1 下预编译的 PyTorch。
conda install pytorch cudatoolkit=10.1 torchvision -c pytorch
c 克隆 MMEditing 仓库:
git clone https://github.com/open-mmlab/mmediting.git
cd mmediting
d 安装相关依赖和 MMEditing:
pip install -r requirements.txt
pip install -v -e .
4 如何使用 MMEditing 开发自己的项目
-
了解 MMEditing 配置文件的写法
在学习使用 MMEditing 开发自己的项目之前,必经的工作是了解 MMEditing 配置文件的写法,详细的教程可以参考原作者的官方文档:
https://mmediting.readthedocs.io/zh_CN/latest/config.html
MMEditing 给大家提供了许多示例配置文件,它们的位置在$MMEditing/configs目录下。
这些配置文件都遵循统一的命名风格,转述如下:
{model}_[model setting]_{backbone}_[refiner]_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset}
{xxx} 是必填字段,[yyy] 是可选的。
-
{model}: 模型种类,例如srcnn,dim等等。 -
[modelsetting]: 特定设置一些模型,例如,输入图像resolution, 训练stagename。 -
{backbone}: 主干网络种类,例如r50(ResNet-50)、x101(ResNeXt-101)。 -
{refiner}: 精炼器种类,例如pln简单精炼器模型 -
[norm_setting]: 指定归一化设置,默认为批归一化,其他归一化可以设为:bn(批归一化),gn(组归一化),syncbn(同步批归一化)。 -
[misc]: 模型中各式各样的设置/插件,例如dconv,gcb,attention,mstrain。 -
[gpuxbatch_per_gpu]: GPU数目 和每个 GPU 的样本数, 默认为8x2。 -
{schedule}: 训练策略,如20k,100k等,意思是20k或100k迭代轮数。 -
{dataset}: 数据集,如places(图像补全)、comp1k(抠图)、div2k(图像恢复)和paired(图像生成)。
下面我们以图像超分 (SISR) 任务的 ESRGAN 模型为例,来解释下配置文件的含义,配置文件的位置在$MMEditing\configs\restorers\esrgan\esrgan_psnr_x4c64b23g32_g1_1000k_div2k.py。
注释按照:了解配置文件 - MMEditing 文档 的风格标注在了代码里面:
exp_name = 'esrgan_psnr_x4c64b23g32_g1_1000k_div2k' ## 实验名称
scale = 4 ## 上采样放大因子
## 模型设置
model = dict(
type='BasicRestorer', ## 图像恢复模型类型
generator=dict( ## 生成器配置
type='RRDBNet', ## 生成器类型
in_channels=3, ## 输入通道数
out_channels=3, ## 输出通道数
mid_channels=64, ## 中间特征通道数
num_blocks=23, ## 残差块数目
growth_channels=32, ## 上采样因子
upscale_factor=scale), ## 残差缩放因子
pixel_loss=dict(type='L1Loss', loss_weight=1.0, reduction='mean')) ## 像素损失函数的配置
## 模型训练和测试设置
train_cfg = None ## 训练的配置
test_cfg = dict( ## 测试的配置
metrics=['PSNR', 'SSIM'], ## 测试时使用的评价指标
crop_border=scale) ## 测试时裁剪的边界尺寸
## 数据集设置
train_dataset_type = 'SRAnnotationDataset' ## 用于训练的数据集类型
val_dataset_type = 'SRFolderDataset' ## 用于验证的数据集类型
train_pipeline = [## 训练数据前处理流水线步骤组成的列表
dict(
type='LoadImageFromFile', ## 从文件加载图像
io_backend='disk', ## 读取图像时使用的 io 类型
key='lq', ## 设置LR图像的键来找到相应的路径
flag='unchanged'), ## 读取图像的标识
dict(
type='LoadImageFromFile', ## 从文件加载图像
io_backend='disk', ## 读取图像时使用的io类型
key='gt', ## 设置HR图像的键来找到相应的路径
flag='unchanged'), ## 读取图像的标识
dict(type='RescaleToZeroOne', keys=['lq', 'gt']), ## 将图像从[0,255]重缩放到[0,1]
dict(
type='Normalize', ## 正则化图像
keys=['lq', 'gt'], ## 执行正则化图像的键
mean=[0, 0, 0], ## 平均值
std=[1, 1, 1], ## 标准差
to_rgb=True), ## 更改为 RGB 通道
dict(type='PairedRandomCrop', gt_patch_size=128), ## LR 和 HR 成对随机裁剪
dict(
type='Flip', ## 图像翻转
keys=['lq', 'gt'], ## 执行翻转图像的键
flip_ratio=0.5, ## 执行翻转的几率
direction='horizontal'), ## 翻转方向
dict(type='Flip', ## 图像翻转
keys=['lq', 'gt'], ## 执行翻转图像的键
flip_ratio=0.5, ## 执行翻转的几率
direction='vertical'), ## 翻转方向
dict(type='RandomTransposeHW', ## 图像的随机的转置
keys=['lq', 'gt'], ## 执行转置图像的键
transpose_ratio=0.5), ## 执行转置的几率
dict(type='Collect', ## Collect 类决定哪些键会被传递到生成器中
keys=['lq', 'gt'], ## 传入模型的键
meta_keys=['lq_path', 'gt_path']), ## 元信息键。在训练中,不需要元信息
dict(type='ImageToTensor', keys=['lq', 'gt']) ## 将图像转换为张量
]
test_pipeline = [ ## 测试数据前处理流水线步骤组成的列表
dict(
type='LoadImageFromFile', ## 从文件加载图像
io_backend='disk', ## 读取图像时使用的io类型
key='lq', ## 设置LR图像的键来找到相应的路径
flag='unchanged'), ## 读取图像的标识
dict(
type='LoadImageFromFile', ## 从文件加载图像
io_backend='disk', ## 读取图像时使用的io类型
key='gt', ## 设置HR图像的键来找到相应的路径
flag='unchanged'), ## 读取图像的标识
dict(type='RescaleToZeroOne', keys=['lq', 'gt']), ## 将图像从[0,255]重缩放到[0,1]
dict(
type='Normalize', ## 正则化图像
keys=['lq', 'gt'], ## 执行正则化图像的键
mean=[0, 0, 0], ## 平均值
std=[1, 1, 1], ## 标准差
to_rgb=True), ## 更改为RGB通道
dict(type='Collect', ## Collect类决定哪些键会被传递到生成器中
keys=['lq', 'gt'], ## 传入模型的键
meta_keys=['lq_path', 'lq_path']), ## 元信息键
dict(type='ImageToTensor', keys=['lq', 'gt']) ## 将图像转换为张量
]
data = dict(
workers_per_gpu=8, ## 单个 GPU 的 dataloader 的进程
train_dataloader=dict(samples_per_gpu=16, drop_last=True),
val_dataloader=dict(samples_per_gpu=1),
test_dataloader=dict(samples_per_gpu=1),
## 训练
train=dict( ## 训练数据集的设置
type='RepeatDataset', ## 基于迭代的重复数据集
times=1000, ## 重复数据集的重复次数
dataset=dict(
type=train_dataset_type, ## 数据集类型
lq_folder='data/DIV2K/DIV2K_train_LR_bicubic/X4_sub', ## lq文件夹的路径
gt_folder='data/DIV2K/DIV2K_train_HR_sub', ## gt文件夹的路径
ann_file='data/DIV2K/meta_info_DIV2K800sub_GT.txt', ## 批注文件的路径
pipeline=train_pipeline, ## 训练流水线,如上所示
scale=scale)), ## 上采样放大因子
## 验证
val=dict(
type=val_dataset_type, ## 数据集类型
lq_folder='data/val_set5/Set5_bicLRx4', ## lq 文件夹的路径
gt_folder='data/val_set5/Set5', ## gt 文件夹的路径
pipeline=test_pipeline, ## 测试流水线,如上所示
scale=scale, ## 上采样放大因子
filename_tmpl='{}'), ## 文件名模板
## 测试
test=dict(
type=val_dataset_type, ## 数据集类型
lq_folder='data/val_set14/Set14_bicLRx4', ## lq 文件夹的路径
gt_folder='data/val_set14/Set14', ## gt 文件夹的路径
pipeline=test_pipeline, ## 测试流水线,如上所示
scale=scale, ## 上采样放大因子
filename_tmpl='{}')) ## 文件名模板
## 优化器设置
optimizers = dict(generator=dict(type='Adam', lr=2e-4, betas=(0.9, 0.999))) ## 用于构建优化器的设置,支持PyTorch中所有参数与PyTorch中参数相同的优化器
## 学习策略
total_iters = 1000000 ## 训练模型的总迭代数
lr_config = dict( ## 调度器的策略,使用余弦、循环等
policy='CosineRestart',
by_epoch=False,
periods=[250000, 250000, 250000, 250000],
restart_weights=[1, 1, 1, 1],
min_lr=1e-7)
checkpoint_config = dict( ## 模型权重钩子设置,更多细节可参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py
interval=5000, ## 模型权重文件保存间隔为5000次迭代
save_optimizer=True, ## 保存优化器
by_epoch=False) ## 按迭代次数计数
evaluation = dict( ## 构建验证钩子的配置
interval=5000, ## 执行验证的间隔为5000次迭代
save_image=True, ## 验证期间保存图像
gpu_collect=True) ## 使用gpu收集
log_config = dict( ## 注册日志钩子的设置
interval=100, ## 打印日志间隔
hooks=[
dict(type='TextLoggerHook', by_epoch=False), ## 记录训练过程信息的日志
dict(type='TensorboardLoggerHook'), ## 同时支持 Tensorboard 日志
# dict(type='PaviLoggerHook', init_kwargs=dict(project='mmedit-sr'))
])
visual_config = None ## 可视化的设置
# runtime settings
dist_params = dict(backend='nccl') ## 建立分布式训练的设置,其中端口号也可以设置
log_level = 'INFO' ## 日志等级
work_dir = f'./work_dirs/{exp_name}' ## 记录当前实验日志和模型权重文件的文件夹
load_from = None ## 从给定路径加载模型作为预训练模型. 这个选项不会用于断点恢复训练
resume_from = None ## 加载给定路径的模型权重文件作为断点续连的模型, 训练将从该时间点保存的周期点继续进行
workflow = [('train', 1)] ## runner 的执行流. [('train', 1)] 代表只有一个执行流,并且这个名为 train 的执行流只执行一次
-
测试预训练模型:
MMEditing 官方文档介绍了如何使用该框架来测试训练好的模型:
MMEditing 使用 MMDistributedDataParallel 实现 分布式测试。
下面的指令为在单个或多个 GPU 上测试的指令:
# 单 GPU 测试
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--save-path ${IMAGE_SAVE_PATH}]
# 多 GPU 测试
./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--save-path ${IMAGE_SAVE_PATH}]
举例:
# 单 GPU 测试
python tools/test.py configs/example_config.py work_dirs/example_exp/example_model_20200202.pth --out work_dirs/example_exp/results.pkl
# 多 GPU 测试
./tools/dist_test.sh configs/example_config.py work_dirs/example_exp/example_model_20200202.pth --save-path work_dirs/example_exp/results/
dist_test 的代码是:
#!/usr/bin/env bash
CONFIG=$1
CHECKPOINT=$2
GPUS=$3
PORT=${PORT:-29500}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
$(dirname "$0")/test.py $CONFIG $CHECKPOINT --launcher pytorch ${@:4}
训练一个模型:
MMEditing 使用 MMDistributedDataParallel 实现 分布式训练。
所有输出(日志文件和模型权重文件)都将保存到工作目录中, 工作目录由配置文件中的 work_dir 指定。
默认情况下,我们在多次迭代后评估验证集上的模型,您可以通过在训练配置中添加 interval 参数来更改评估间隔。
evaluation = dict(interval=1e4, by_epoch=False) # 每一万次迭代进行一次评估。
下面的指令为在单个或多个 GPU 上训练的指令:
./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
可选参数是:
-
--no-validate代码库将在训练期间每 k 次迭代执行一次评估。若使用 --no-validate,则不进行此操作。所以一般不建议使用。 -
--work-dir${WORK_DIR}: 覆盖配置文件中指定的工作目录。 -
--resume-from${CHECKPOINT_FILE}: 从已有的模型权重文件恢复。
resume-from 用于模型在训练中因意外中断导致的问题,此时需要加载模型权重和优化器状态,迭代也从指定的检查点继承。
load-from 只加载模型权重,训练迭代从 0 开始,通常用于预训练好了以后我们的 Fine-tune 过程。
dist_train.sh 的代码是:
#!/usr/bin/env bash
CONFIG=$1
GPUS=$2
PORT=${PORT:-29500}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
$(dirname "$0")/train.py $CONFIG --launcher pytorch ${@:3}
5 OpenMMLab 的其他项目
-
MMCV: OpenMMLab 计算机视觉基础库 -
MIM: OpenMMlab 项目、算法、模型的统一入口 -
MMClassification: 图像分类工具箱与测试基准 -
MMDetection: OpenMMLab 检测工具箱与测试基准 -
MMDetection3D: OpenMMLab 新一代通用3D目标检测平台 -
MMSegmentation: 语义分割工具箱与测试基准 -
MMAction2: OpenMMLab 新一代视频理解工具箱与测试基准 -
MMTracking: OpenMMLab 一体化视频目标感知平台 -
MMPose: OpenMMLab 姿态估计工具箱与测试基准 -
MMEditing: OpenMMLab 图像视频编辑工具箱 -
MMOCR: OpenMMLab 全流程文字检测识别理解工具包 -
MMGeneration: OpenMMLab 生成模型工具箱 -
MMFlow: OpenMMLab 光流估计工具箱与测试基准 -
MMFewShot: OpenMMLab 少样本学习工具箱与测试基准 -
MMHuman3D: OpenMMLab 人体参数化模型工具箱与测试基准
6 致谢和引用
MMEditing 是一款由不同学校和公司共同贡献的开源项目。我们感谢所有为项目提供算法复现和新功能支持的贡献者,以及提供宝贵反馈的用户。我们希望该工具箱和基准测试可以为社区提供灵活的代码工具,供用户复现现有算法并开发自己的新模型,从而不断为开源社区提供贡献。
如果您觉得 MMEditing 对您的研究有所帮助,请考虑引用它:
@misc{mmediting2020,
title={OpenMMLab Editing Estimation Toolbox and Benchmark},
author={MMEditing Contributors},
howpublished = {\url{https://github.com/open-mmlab/mmediting}},
year={2020}
}
引用链接:
https://mmediting.readthedocs.io/zh_CN/latest/
https://github.com/open-mmlab/mmediting/blob/master/README_zh-CN.md
公众号后台回复“数据集”获取50+深度学习数据集下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选




