吴恩达的课上完了?如何科学开启你的深度学习论文阅读生涯

大数据文摘出品
编译:睡不着的iris、Zhifu、Hope、CoolBoy
当你阅读了深度学习相关的书籍或者上过精彩的在线课程后,你将如何深入学习?如何才能够“自力更生”,独立地去了解相关领域中最新的研究进展?本文作者Nityesh Agarwal,毕业于贾达普大学,在学校里学习过信息技术,现在作为志愿者为开源社区做贡献。以下是作者第一人称给出的建议。
事先声明——我不是深度学习方面的专家。我也是最近才开始阅读研究论文的。本文将会介绍我自己在开始阅读文献的时候积累的一些经验。
意义所在
曾经有人在Quora上提问,如何才能鉴定一个人是否有资格从事机器学习工作。谷歌大脑创始人之一、百度人工智能小组前负责人吴恩达(Andrew Ng)如是说:任何人都有资格。当你上过一些机器学习相关的课程后,想要更进一步时,可以阅读一些研究论文。最好能做到重现论文中的方法,得到相似的结果。
OpenAI研究者达里奥·阿莫迪(Dario Amodei)对这个问题的回答是:“为了验证你是否适合在人工智能安全或者机器学习领域工作,请快速尝试使用各种模型。在近期的一篇论文中找到一个机器学习模型,运用这个模型,并尝试让它快速运行起来。”
这些都说明阅读研究论文对于进一步理解该领域至关重要。
在深度学习领域,每个月都会有数百篇论文被发表。如果要做到认真地学习,仅凭借学习教程或者上课是远远不够的。在你读文章的时候,新的突破性研究正在进行中。深度学习领域的研究正以前所未有的迅猛速度发展着。只有养成良好习惯,持续阅读科研文献,才能跟上节奏。
本文中,我会教大家如何独立阅读一篇论文,并提供一些切实可行的建议。然后,在文末我会带大家破解一篇真实的科研论文,让大家能够进行实践。
方法建议
首先,阅读科研论文很难。事实上——“没有什么事情比阅读科研论文更令你感到愚蠢了。”

我这么说是为了让你在读文章百思不得其解的时候,不要感到气馁。开始读了好几遍的时候,可能你还是不能够理解文章的意思。没事,请坚持下去,再读一次!
现在,我们介绍一些有助于文献阅读的宝贵资源。
arXiv.org
这是在互联网上大家发表文章的一个地方,充满了一些尚未在知名期刊正式发表的文章(这些文章也可能永远无法正式发表)
他们为什么要这么做?
事实证明,做研究和写文章并不是科研的全部!将论文提交并发表在某些科学期刊上是一个相当漫长的过程。一旦论文被提交至某个期刊,就会进入非常缓慢的同行评审过程(有些甚至需要多年的时间!)。当下,对于机器学习这些快速发展的领域,这种速度真是让人无法忍受。
这就是arXiv出现的意义!!!
研究人员将他们的论文发表在arXiv这样的预印库上,以便快速发布他们的研究并获得及时的反馈。
Arxiv Sanity Preserver
研究人员能够便捷地提前发表研究论文是好事情,但是对于读者来说呢?当你打开arXiv的网站,很容易感到害怕、渺小和迷茫,认为这绝对不是新手该来的地方(仅个人观点,但非常欢迎你使用它☺)。
输入Arxiv Sanity Preserver。
这是由特斯拉的人工智能部门主管Andrej Karpathy创建,他是我个人非常喜欢的AI大神。
Arxiv Santiy在arXiv的作用与Twitter的信息流在Twitter的作用相似(不过Arxiv Sanity是完全开源的,而且没有任何广告)。从浩如烟海的微型博客中, Twitter的信息流会根据个人喜好为你推送有趣的微型博客。
Arxiv Sanity采用类似的方法,为你推荐arXiv上你可能最感兴趣的机器学习论文。使用Arxiv Santiy,你可以根据当前趋势、你的过往喜好和你所关注的人的喜好对论文进行排序。(这就是在社交媒体上我们已经习惯使用的个性化推荐功能。)
关于网站的简介可以浏览这个视频☝
机器学习:Reddit上的WAYR主题帖
WAYR是What Are You Reading(你正在阅读什么)的简写。它是Reddit机器学习板块的一个主题帖,大家把自己本周读过的机器学习论文发布在上面,并对感兴趣的问题展开讨论。
正如我之前所说,每周有非常多关于机器学习领域的论文被发表在arXiv上。对于需要兼顾日常生活的正常人,每天需要上学、工作或与人沟通,不可能每周都把所有的论文读完。另外,并不是所有的论文都值得花时间去阅读。
因此,你需要把精力放在最有意思的论文上,上面我提到的主题帖就是一种方法。
电子报刊,电子报刊,电子报刊!
电子报刊是我的个人最爱,通过它我可以时时刻刻追踪人工智能领域最新的进展。你可以非常简单地订阅它们,并且让它们每周一传送到你的电子信箱里面,不用花一分钱!就这么简单,你就可以了解本周与AI相关的最有意思的新闻、文章和研究论文。
以下是我目前订阅的一些电子报刊:
1.Jack Clark的引入AI
https://jack-clark.net/
这是我的最爱,因为这份电子报刊除了提供我上面提到的所有信息以外,它还包括一个叫做“科技童话”的部分,包含一篇由过去一周的新闻主题编辑的AI科幻短篇小说。悄悄地告诉你,即使有那么几周我对AI的新进展失去热情,我也会因为想看科技童话这部分而浏览这个电子报刊
2.Sam DeBrule的机器学习
https://machinelearnings.co/
作者还有一本同名的媒体出版物,其中包含了一些非常有趣的文章,请务必查看。
文章链接
https://machinelearnings.co/a-humans-guide-to-machine-learning-e179f43b67a0
3.Nathan Benaich的Nathan.ai
https://www.getrevue.co/profile/nathanbenaich
前两份电子报刊都是周报,而这份是季刊。因此,每隔三个月你会收到一封长长的电子邮件,里面总结了过去三个月以来AI领域最有趣的发现和发展状况。
4.Denny Britz的AI狂野一周
https://www.getrevue.co/profile/wildml
我个人真的很喜欢这份电子报刊,因为它的版面很干净,演示很简洁,不过近两个月以来好像没有继续更新了。无论如何,给大家一个参考,希望Danny什么时候再恢复更新。
5.Twitter上面的AI大V
另一个可以追踪时新的方法是关注知名研究者和开发人员的Twitter账户。以下是我关注的人员列表:
Michael Nielsen
Andrej Karpathy
Francois Chollet
Yann LeCun
Chris Olah
Jack Clark
Ian Goodfellow
Jeff Dean
OpenAI
听起来都很不错,但是我应该怎么开始呢?
是的,这是一个更加迫切的问题。
好的,首先你需要确保自己已经了解了机器学习的相关基础知识,例如回归等算法;你还需要知道一些深度学习的基本知识,比如最基本的神经网络,反向传播,正则化。
最好还能够稍微了解难一些的概念,例如ConvNets、RNN 和LSTM是如何工作的。我真心不觉得阅读研究论文是了解这些基础知识的最好的方法,有很多其它的资源可以供你参考。
一旦有了基本的了解,你首先应该阅读一篇相关的论文。这样,你就可以专注地熟悉学术论文的基本格式和体裁。你并不需要完全读懂你阅读的第一篇学术论文,因为你对论文的主题已经非常熟悉了。
我建议你先从讲述AlexNet的论文开始。
链接:
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks
为什么选择这篇论文?
请看下面的这张图:
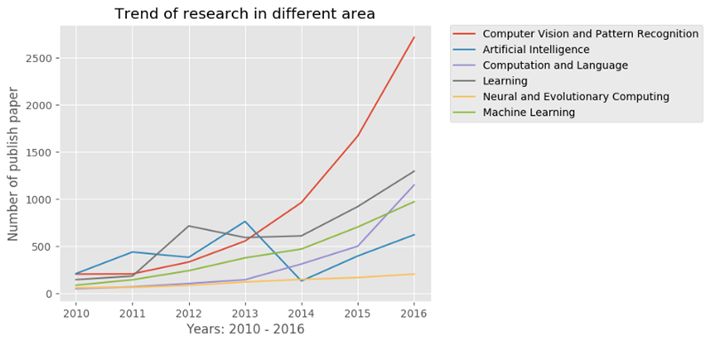
你看见代表Computer Vision and Pattern Recognition的红线从2012年之后飙升得非常明显了吧?这种情况很大程度上要归功于这篇论文。
这篇论文重新点燃了人们对深度学习的所有兴趣。
由Alex Krizhevsky,Ilya Sutskever和Geoffrey Hinton撰写,题为《ImageNet Classification with Deep Convolutional Networks》的这篇论文被认为是该领域最具影响力的论文之一。这篇论文描述了作者如何使用名为AlexNet的卷积神经网络,并赢得2012年度ImageNet大规模视觉识别挑战赛(ILSVRC)的冠军。
如果你不太了解情况,让我来为你解释一下。让计算机能够观察和识别对象(又名计算机视觉)是计算机科学最早的目标之一。 ILSVRC就像是这个领域内的奥运会。参赛者(计算机算法)试图将图像正确地归为1000个类别的其中一个。 在2012年,AlexNet以绝对巨大的优势赢得了这一挑战:
AlexNet以15.3%的top-5(模型预测概率的前五位包含目标物体)错误率荣登榜首,而第二名的错误率则只有26.2%!
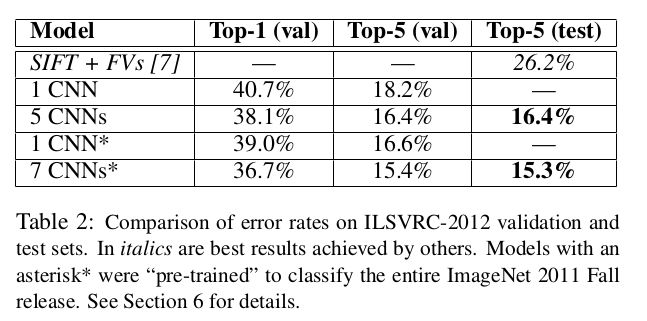
毫无疑问,整个计算机视觉社区都震惊了,关于该领域的研究正前所未有地飞速发展。人们开始意识到深度神经网络的强大,利用它每个人都能够从中受益!
别看这篇文章看起来很难,如果你通过一些课程或者教材对卷积神经网络有基本的了解,那么掌握这篇论文的内容是非常容易的。赶紧行动吧!
当你读完了上面那篇文章之后,你可以阅读与卷积神经网络相关的其他具有开创性意义的论文,也可以转移到你感兴趣的其他架构(比如RNN,LSTM,GAN)。
Github的存储库上面也有很多重要的深度学习方面的研究论文。 当你开始阅读的时候请先看看这份指引,它们将帮助你创建属于自己的阅读列表。
链接:
https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap
不得不提到的其它资源
Distill.pub :
https://distill.pub/about/
我只想提一点:如果所有研究论文都在Distill期刊上发表,那我这篇文章就可以不用写了。你不必阅读这篇文章来学习如何开始阅读研究论文,并且我们也不需要在互联网上创建这么多的课程和教程来解释这些开创性的研究思想,Distill就是这样一个综合性的平台。
相关链接:
https://towardsdatascience.com/getting-started-with-reading-deep-learning-research-papers-the-why-and-the-how-dfd1ac15dbc0
【今日机器学习概念】
Have a Great Definition


Contributors
回复“志愿者”加入我









