导读 本文将分享数据湖的发展近况。主要内容包括:
- 数据湖发展趋势分析
- 数据湖整体架构
- 数据集成
- Lakehouse 核心能力
- Lakehouse 开放性设计
- 流批一体
- 实时 OLAP
- 湖内建仓 分享嘉宾|受春柏 华为云 大数据架构师 编辑整理|马信宏 内容校对|李瑶 出品社区|DataFun
01
数据湖发展趋势分析****
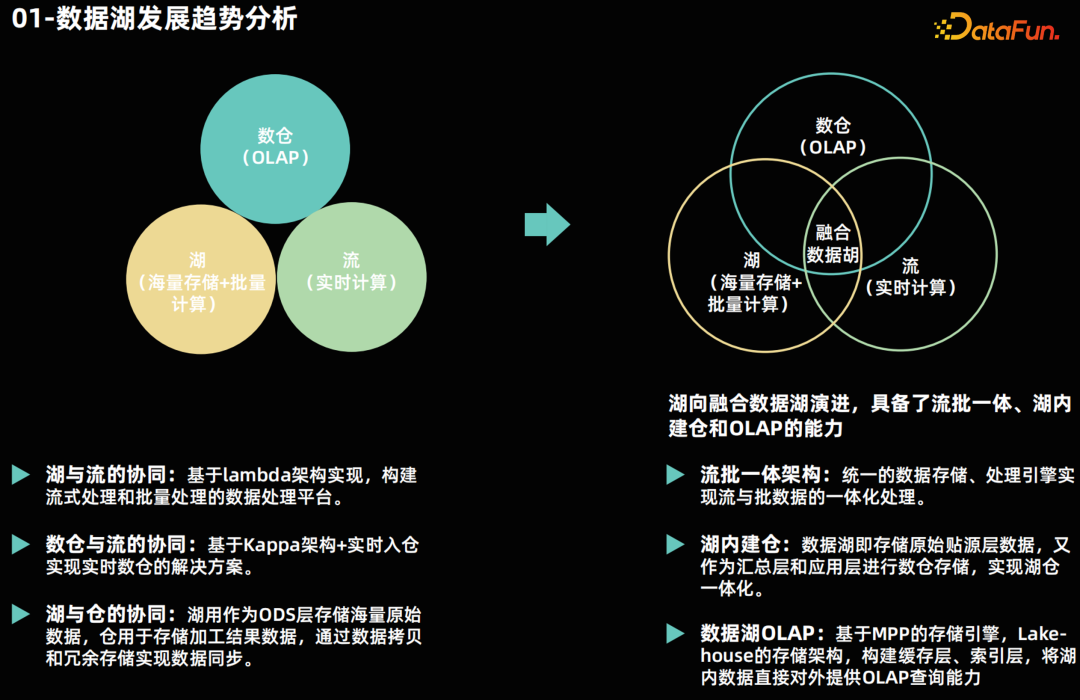
- 数据湖:由 Hadoop 搭建的大数据平台承载,负载海量数据存储与批量计算。
- 流式计算:一般由 Flink 组件承载,负责实时的数据流处理。
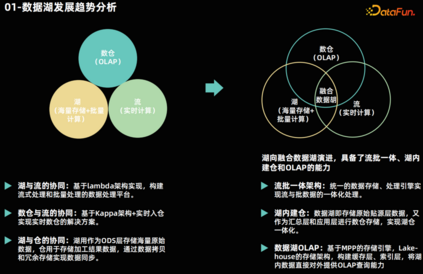
- OLAP 数仓:可选择技术比较多,包括:开源的 Doris、StarRocks、Clickhouse 等以及传统数仓,负责承载数据查询业务。 这三个平台在以往通常是独立建设的,集群也是独立部署。三者之间数据互相拉通,采用以下方案:湖平台与流式平台的互通:通常采用 Lambda 架构搭建实时计算平台和离线批量计算平台,以实现流式计算与数据湖之间的协同。流式计算平台与 OLAP 仓互通:一般实际与计算引擎的数据源对接方式拉通,还会基于 Kappa 架构在流式计算中进行实时的数据加工处理,将计算结果写入数仓中,以实现实时的 OLAP 查询,这也是通常讲的实时数仓解决方案。湖平台与数仓平台互通:一般是通过数据拷贝方式,将数据湖的原始数据或者批量计算结果数据复制一份到数仓当中。以上的解决方案存在一些问题。首先,从建设和维护的角度来看,这种架构需要分别建设三个平台,导致建设与维护成本增大;其次,数据共享需要进行一定的冗余存储和数据拷贝,导致方案复杂读变高。因此大家现在在逐渐尝试将三个功能平台融合到一起,形成融合数据湖。在融合数据湖中,将通过流批一体的架构实现实时计算和批量计算的数据共享,解决数据冗余和数据搬迁的问题。通过湖内建仓的方式,在数据湖实现数仓的能力,构建 OLAP 能力,避免了数据的搬迁。这种融合数据湖的架构不仅可以提高数据处理的效率,还可以降低数据平台的建设和维护成本,实现数据的共享和流通。02****
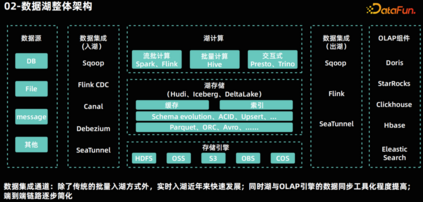
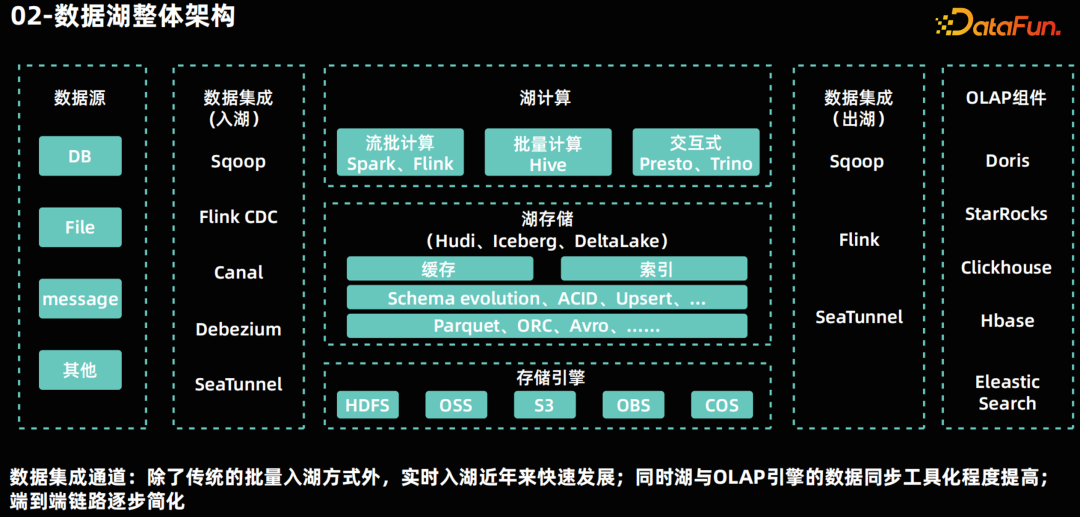
数据湖整体架构********
数据集成********
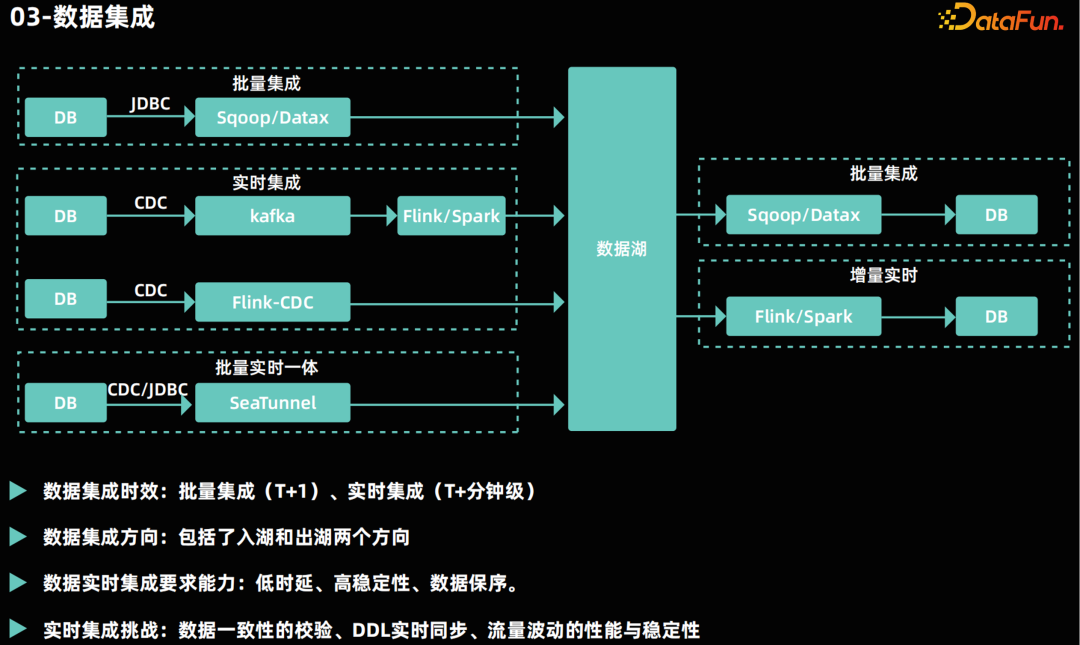
- 完整性保证:区别于批量集成,实时集成是实时采集每一条变更的新数据,在异常场景要保证数据不丢。
- 有序性保证:在流式计算中数据流有更新操作,数据是否保序会影响到计算结果的准确性,例如:上游数据库对同一主键记录更新多次,数据集成会采集到多条记录,如果乱序那计算结果就会错误。
- 稳定性保证:日常的业务通常会有波峰波谷的出现,在实时集成通道要有能力保证流量增大也能保证任务运行的稳定性,可以通过加强监控的方式发现问题,通过弹性伸缩能力或者上线前压测,保证任务的资源分配到位,或者通过限流措施牺牲波峰的时效性来保证稳定性。 随着技术的发展,一些开源工具已经能够实现流批一体的实时数据集成,这些工具不仅可以降低建设成本,还能够减少技术复杂度。04****
Lakehouse 核心能力****

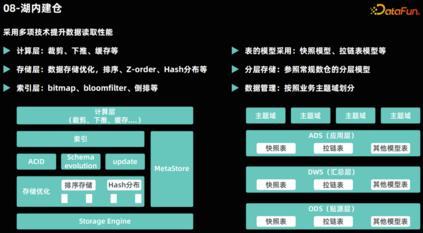
- 增强的 DML SQL 能力:Lakehouse 新增了 update、upsert 和 merge into 等操作,数据湖也具备了更新能力。
- Schema Evolution:业务系统不断演进过程中,会带来表结构的变更,传统大数据在该场景通常采用的是重新建表的方式。Lakehouse 支持 Alter table 能力,保证数据湖表可以更加灵活的适配业务的演进发展。
- ACID 事务和多版本支持:为了确保数据的一致性和完整性,Lakehouse 应提供 ACID 事务支持,并在异常情况下提供数据的回滚能力。多版本支持则允许访问历史数据,为数据的时间旅行提供可能。
- 并发控制:在多用户环境中,Lakehouse 应能够处理并发读写操作,确保数据的一致性和准确性。这包括对同一张表的并发写入以及在读写操作中的严格一致性保证。
- 时间旅行:Lakehouse 应支持时间旅行功能,使用户能够访问任意时间点的数据快照。这不仅为数据回溯和历史分析提供了便利,还支持了流式的增量读取能力。
- 文件存储优化:为了支持高效的 OLAP 查询,Lakehouse 应优化数据存储格式,以便在特定场景下能够快速检索数据。
- 流批一体处理:Lakehouse 应同时支持流式和批量的数据读写,实现数据的一体化存储和处理,满足多样化的数据处理需求。
- 索引构建:为了加速 OLAP 查询,Lakehouse 提供了索引构建能力,以满足业务对查询时延的要求。
- 自动化管理:Lakehouse 具备自动化管理能力,包括数据的合并、历史数据的清理、索引的构建等,以减轻用户的维护负担,并提高数据平台的可靠性和稳定性。 05****
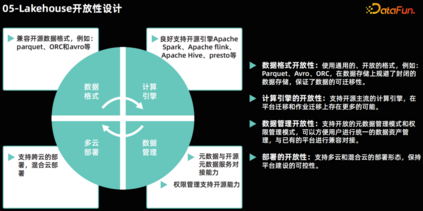
Lakehouse 开放性设计
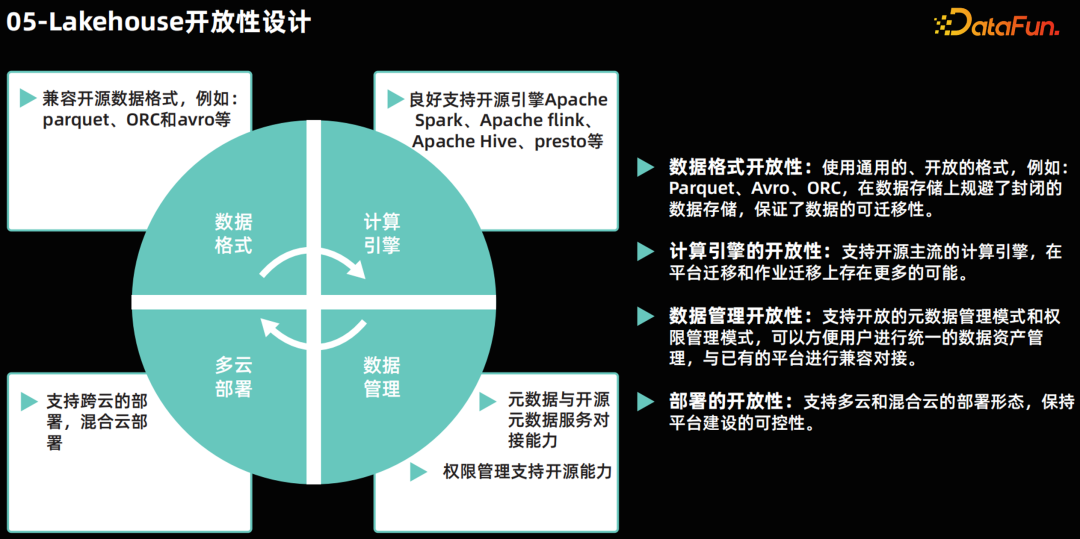
- 数据格式的开放性:Lakehouse 架构应确保其支持的数据格式具有开放性。这意味着使用标准化的、与开源社区广泛兼容的数据格式,如 Parquet 和 ORC。这种开放的数据格式允许 Lakehouse 与各种数据处理工具和计算引擎无缝对接,无论是开源的还是商业的。例如,Apache Spark、Presto 和 Flink 等流行的开源计算引擎都能够高效地读取和写入这些开放格式的数据。
- 计算引擎的开放性:Lakehouse 架构还应支持多种开源和商业计算引擎的接入。这种开放性确保了企业可以根据具体的业务需求和数据处理的场景,选择最合适的计算引擎。无论是实时数据处理、批处理还是交互式查询,Lakehouse 都能够与各种计算引擎协同工作,提供高效的数据处理能力。
- 元数据与数据权限的集成:在 Lakehouse 中,元数据和数据权限管理是数据管理的基本能力要求。这种能力不仅确保了数据的组织和管理效率,还提供了精细的数据访问控制,保障了数据的安全性和合规性。
- 多云部署能力:Lakehouse 架构应支持多云部署策略,包括在私有云和公共云环境中的部署。这种灵活性确保了企业可以根据自身的业务需求和资源状况,选择最合适的部署环境,同时保证了平台的持续稳定演进。 06****
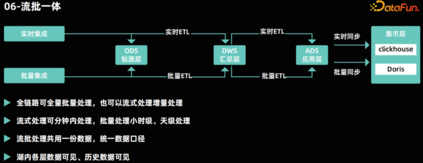
流批一体********
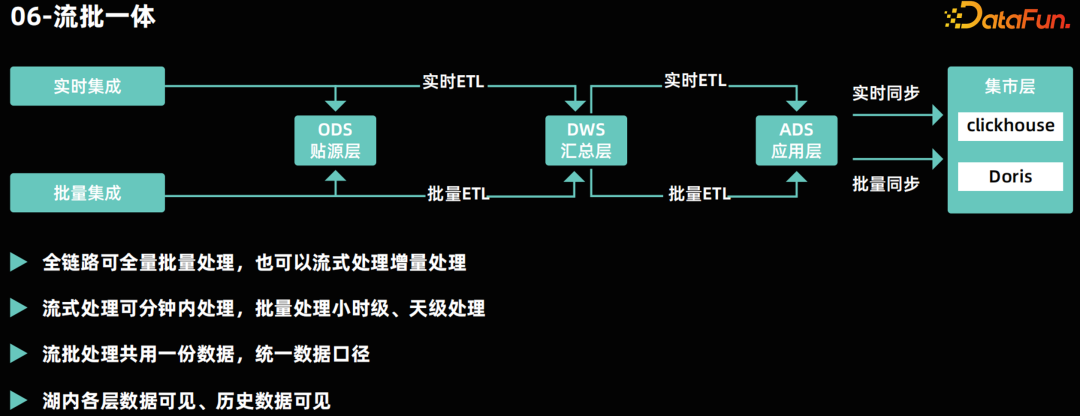
- 数据存储的流批一体:同一份数据既支持流式读取也支持批量读取。物理上数据存储是一份。这种存储模式确保了数据的一致性,并减少了数据冗余。
- 计算引擎的流批一体:指流式计算和批量计算可以由同一个计算引擎完成。例如,Apache Flink 和 Apache Spark 都支持流批一体的数据处理。这种方式可以降低架构复杂度,降低开发者的使用门槛。
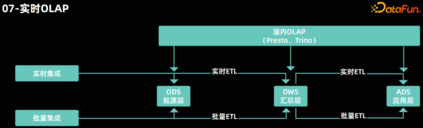
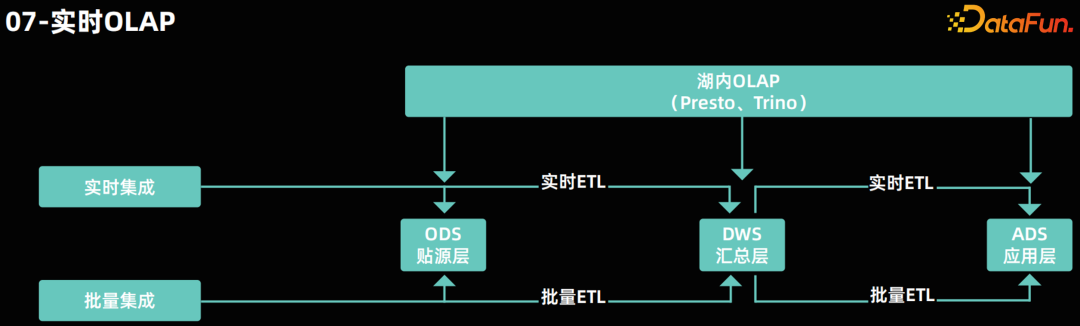
- 数据处理代码的流批一体化:指数据处理的代码可以同时适用于流式和批量的方式执行。这样可以降低开发成本,同时保证流批的任务代码逻辑一致性。在流批一体架构中,全链路支持批量和实时 ETL 计算。在数据仓库的各分层中,企业可以采用批量计算来保证小时级和天级的处理能力,同时利用实时计算来保证分钟级的数据处理能力。通过数据的统一处理,企业可以实现分钟级的数据可见性,并确保数据的一致性,避免批处理和流处理数据结果的不一致性。 07****
实时 OLAP********
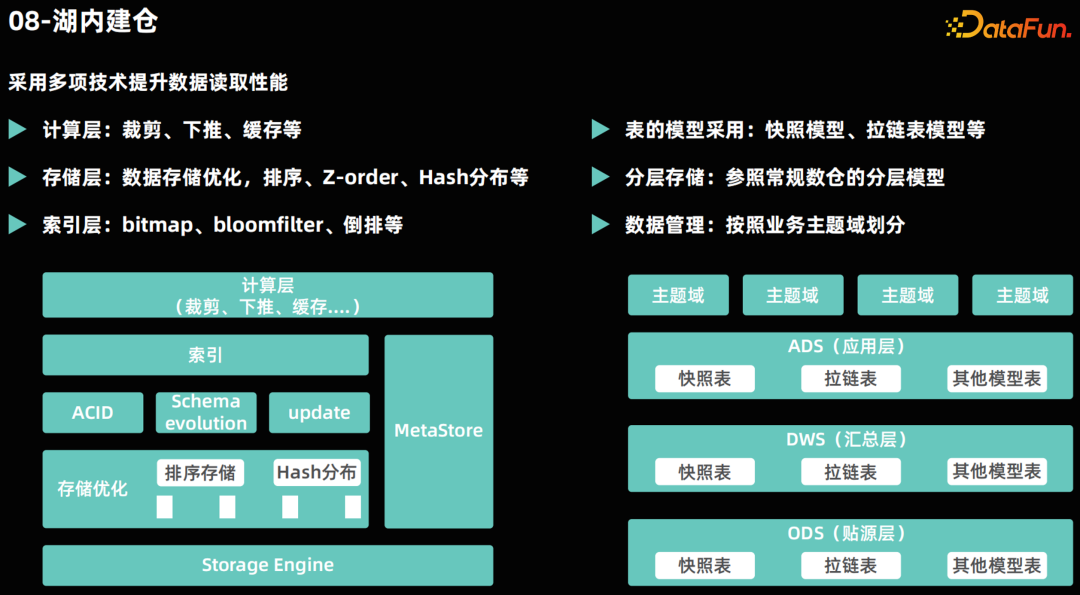
湖内建仓********
分享嘉宾
INTRODUCTION

受春柏
华为云
大数据架构师
华为云大数据架构师,主要负责实时数据湖架构设计。