导读 本文将分享百度商业多模态理解及 AIGC 创新实践,主要包括两大部分:
- 富媒体多模态理解;
- 百度AIGC-擎舵。分享嘉宾|杨羿 百度 商业策略中台技术负责人 编辑整理|曹加印 内容校对|李瑶出品社区|DataFun
01富媒体多模态理解
首先来介绍一下我们对多模态内容的感知。1. 多模态理解
提升内容理解能力,让广告系统在细分场景下更懂内容

在提升内容理解能力时,会遇到很多现实的问题: * 商业业务场景多、行业多,独立建模冗余且会导致过拟合,场景间分布共性和特异性,统一建模如何兼顾; * 商业视觉物料周边文本差,易导致配图badcase; * 系统充斥无意义ID类特征、泛化性差; * 富媒体时代,如何高效利用视觉语义,这些内容特征、视频特征和其他特征如何融合,是我们需要去解决的,用以提升系统内对富媒体内容的感知力度。
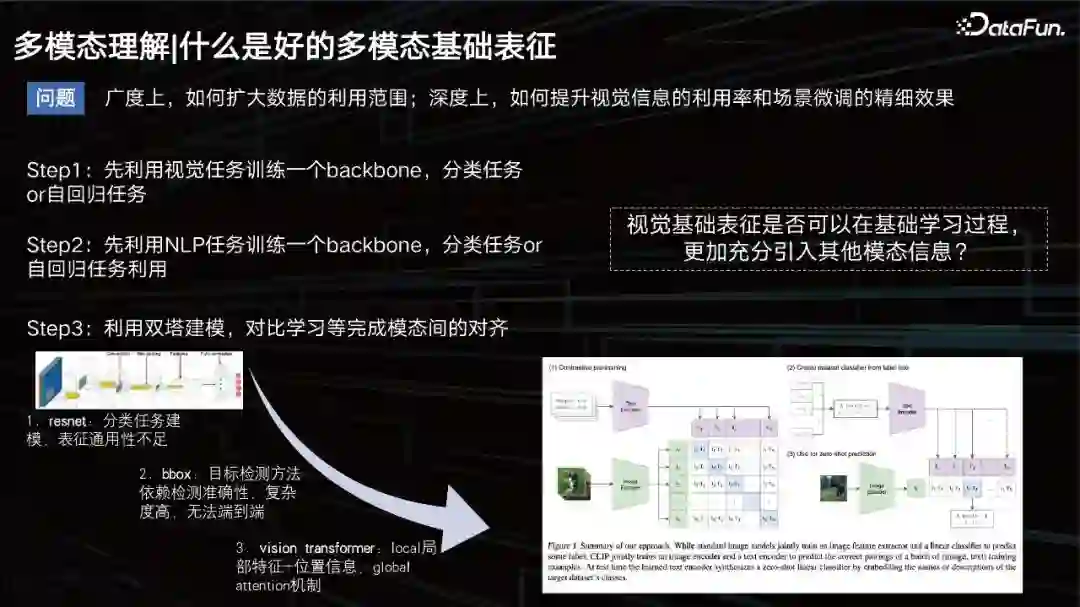
什么是好的多模态基础表征
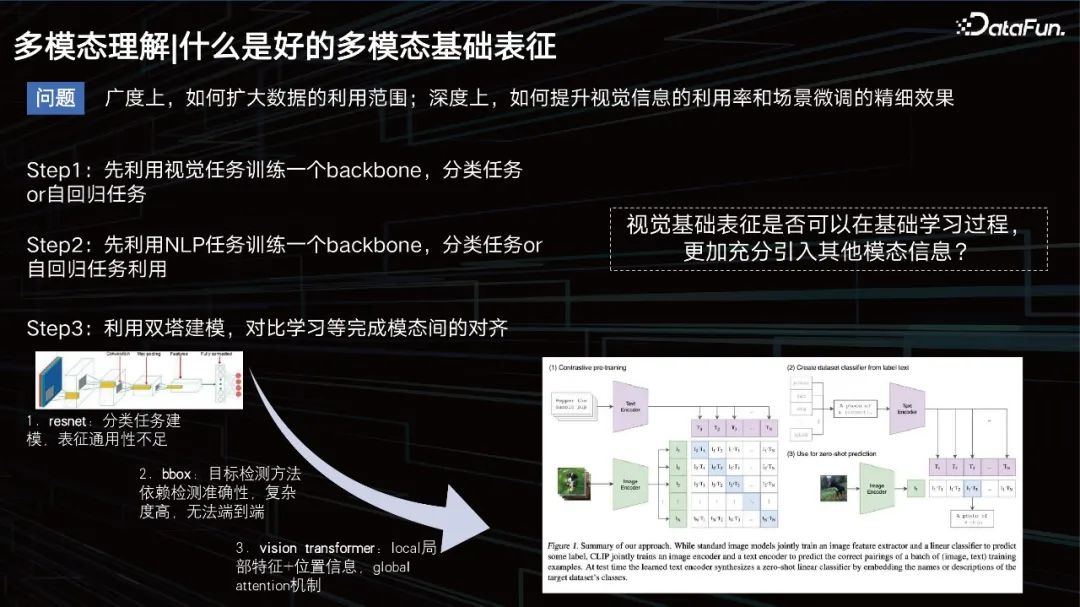
什么是一个好的多模态表征? 从广度上要扩大数据应用的范围,从深度上要提升视觉效果,同时保证场景的数据微调。 之前,常规的思路是,训练一个模型去学习图片的模态,一个自回归的任务,然后做文本的任务,再套用一些双塔的模式,去拉近二者的模态关系。那时的文本建模比较简单,大家更多的是在研究视觉怎么建模。最开始是CNN,后面包括一些基于目标检测的方式去提升视觉的表征,比如bbox方式,但这种方式的检测能力有限,并且太重了,并不利于大规模的数据训练。 到了2020年和2021年前后, VIT方式成为了主流。这里不得不提的一个比较有名的模型就是 OpenAI在20年发布的一个模型CLIP,基于双塔的架构分别去做文本和视觉的表征。再用cosine去拉进二者的距离。该模型在检索上面非常优秀,但在VQA任务等一些需要逻辑推理的任务上,就稍显能力不足了。 学表征:提升自然语言对视觉的基础感知能力

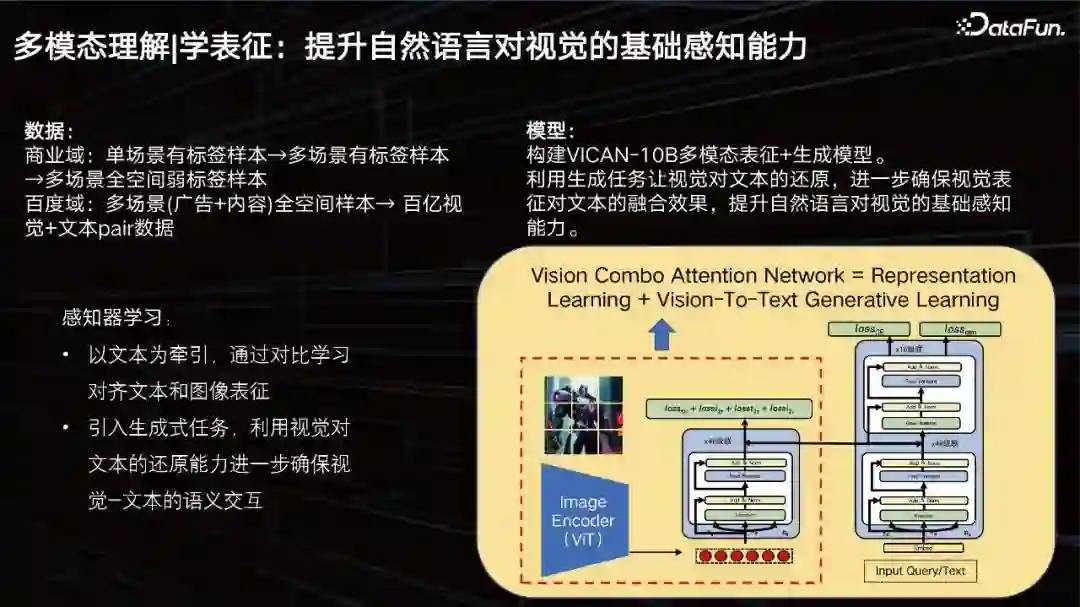
我们的目标就是要提升自然语言对视觉的基础感知能力。数据方面,我们的商业域有着亿级的数据,但仍然不够,我们需要进一步扩展,引入商业域以往的数据,并进行清洗和梳理。构建了百亿级别的训练集。 我们构建了VICAN-12B多模态表征+生成模型,利用生成任务让视觉对文本的还原,进一步确保视觉表征对文本的融合效果,提升自然语言对视觉的基础感知能力。上图中展示了模型的整体结构,可以看到它还是一个双塔+单塔的复合结构。因为首先要解决的是一个大规模图片检索的任务。左边的框中的部分我们称之为视觉的感知器,是一个20亿参数规模的ViT结构。右边可以分两层看,下面为了做检索,是一个文本的transformer的堆叠,上面为了做生成。模型分为了三个任务,一个是生成任务,一个是分类任务,一个是图片对比任务,基于这三个不同目标去训练模型,所以达到了比较好的效果,但我们还会进一步去优化。 一套高效、统一、可迁移的多场景全域表征方案

结合商业场景数据,引入了LLM模型提升模型理解能力。CV模型是感知器,LLM模型是理解器。我们的做法就是需要把视觉特征进行相应的迁移,因为刚才提到,表征是多模态的,大模型是基于文本的。我们只需要让它去适配我们的文心LLM的大模型就可以了,所以我们需要利用Combo attention的方式,去做相应的特征融合。我们需要保留大模型的逻辑推理能力,所以尽量不动大模型,只是加入商业场景反馈数据,去促进视觉特征到大模型的融合。我们可以用few shot的方式去支撑下任务。主要任务包括: * 图片的描述,其实它不仅仅是个描述,而是一个Prompt逆向工程,优质的图文数据可以作为我们后面文生图的一个比较好的数据来源; * 图文相关性控制,因为商业需要做配置,需要做对图片信息的理解,我们广告配图的搜索词和图片语义其实是需要做控制的,当然这是一个很通用的方式,就可以对图片和Prompt进行相关的判定; * 图片风险&体验控制,我们已经能够对图片的内容进行比较好的描述了,那么我们只需要简单利用风控的小样本数据迁移就能够清楚地知道它是否涉及一些风险问题。
下面,重点分享下场景化精调。 2. 场景化精调
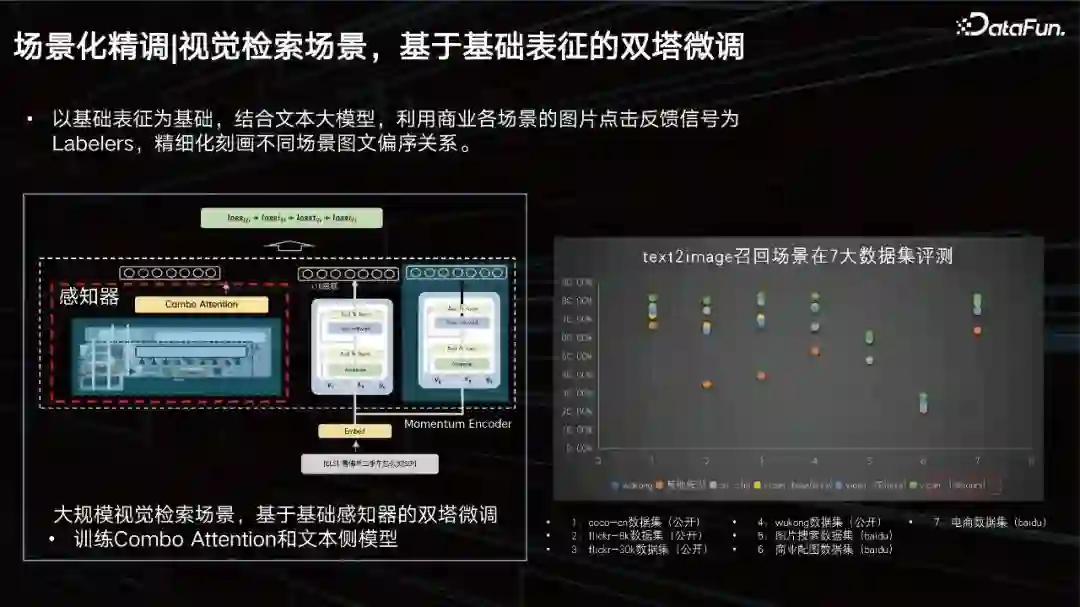
视觉检索场景,基于基础表征的双塔微调
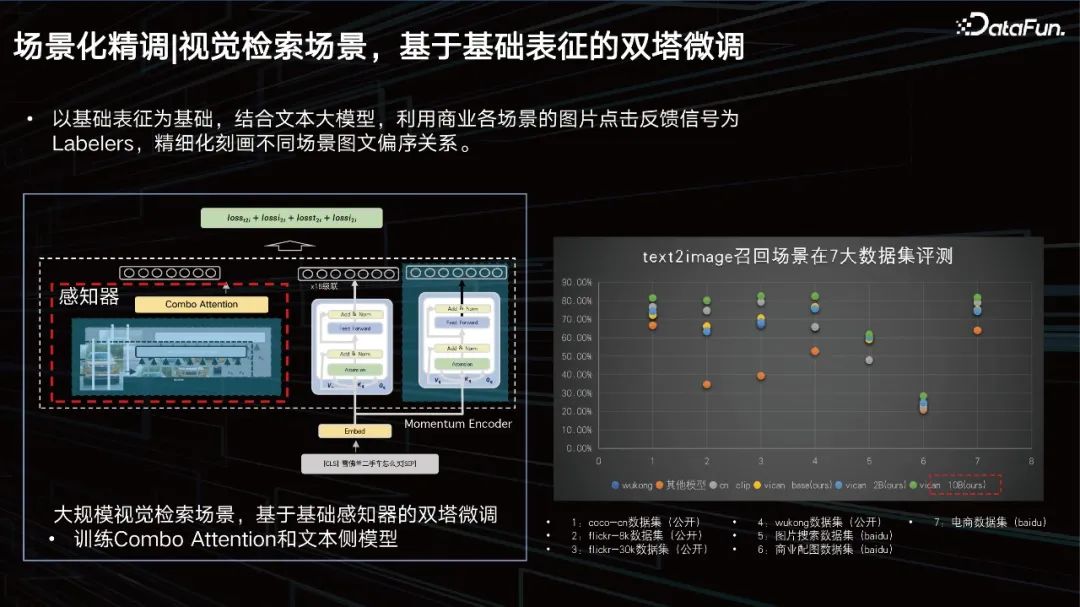
以基础表征为基础,结合文本大模型,利用商业各场景的图片点击反馈信号为Labelers,精细化刻画不同场景图文偏序关系。我们在7大数据集上进行了评测,均能达到SOTA的效果。 排序场景,受文本切词启发,将多模态特征语义量化
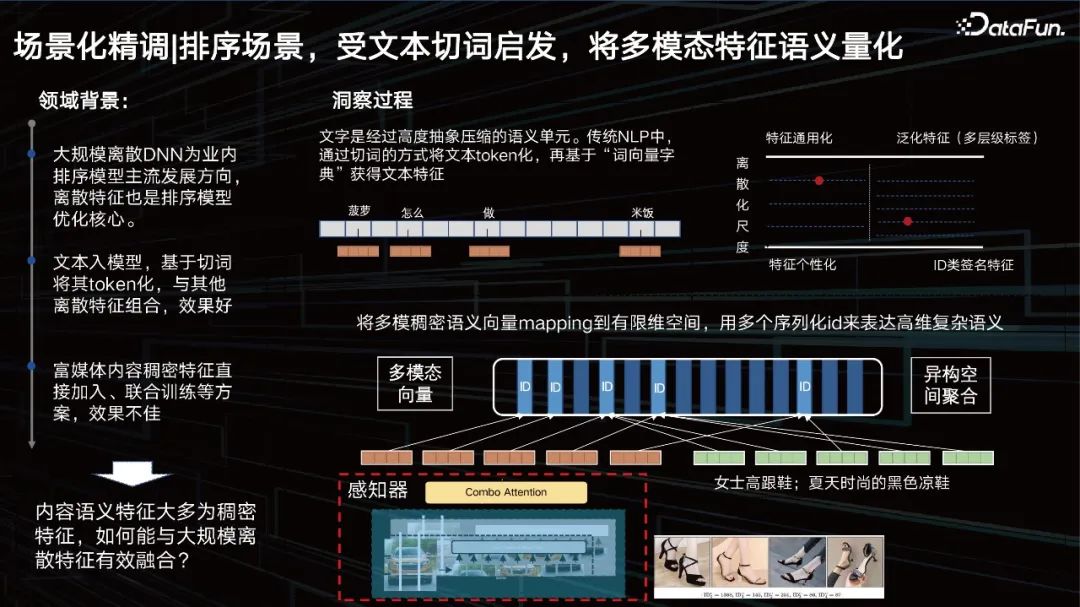
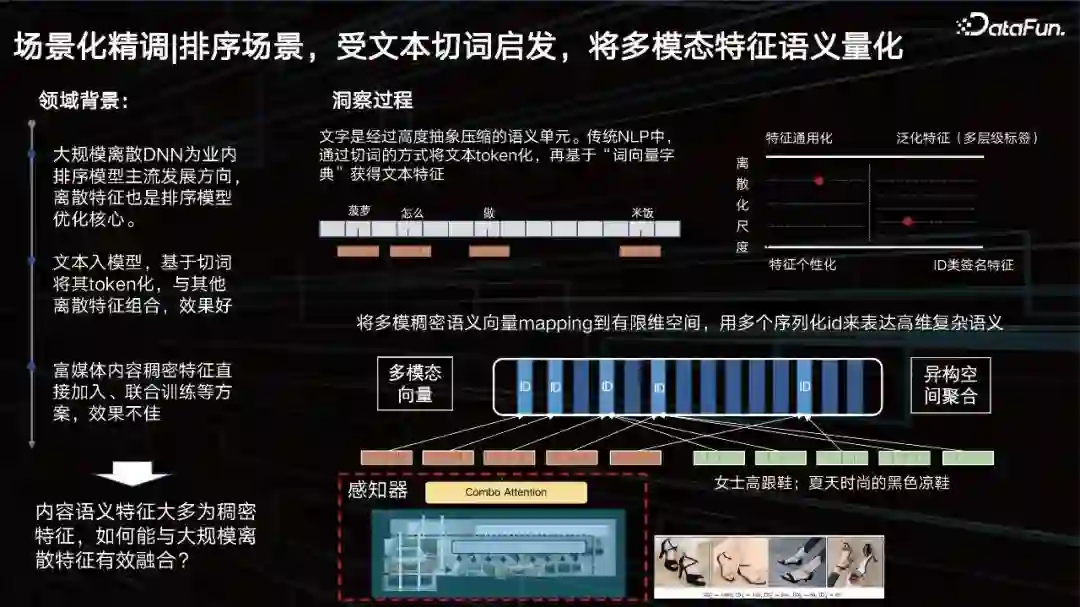
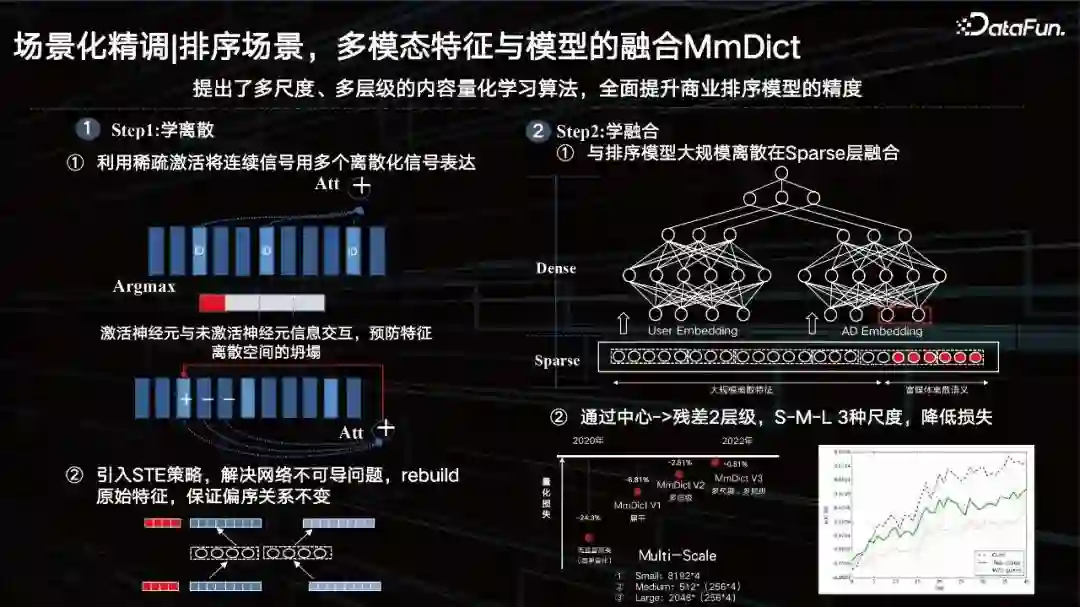
表征以外,另一个问题是如何提升排序场景中视觉的效果。先来看一下领域背景,大规模离散DNN为业内排序模型主流发展方向,离散特征也是排序模型优化的核心。文本入模型,基于切词将其token化,与其他离散特征组合,效果好。而对于视觉,我们希望也能将其进行token化。 ID类特征其实是一个极具个性化的特征,但是泛化特征通用性好了,其刻画精度可能就变差了。我们需要通过数据和任务去动态调节这个平衡点在哪。也就是希望找到一个和数据最相关的尺度,去把特征进行相应的”切词”变成一个ID,像文本一样去切分多模态特征。所以我们提出了一个多尺度、多层级的内容量化学习方法,去解决这一问题。 排序场景,多模态特征与模型的融合 MmDict
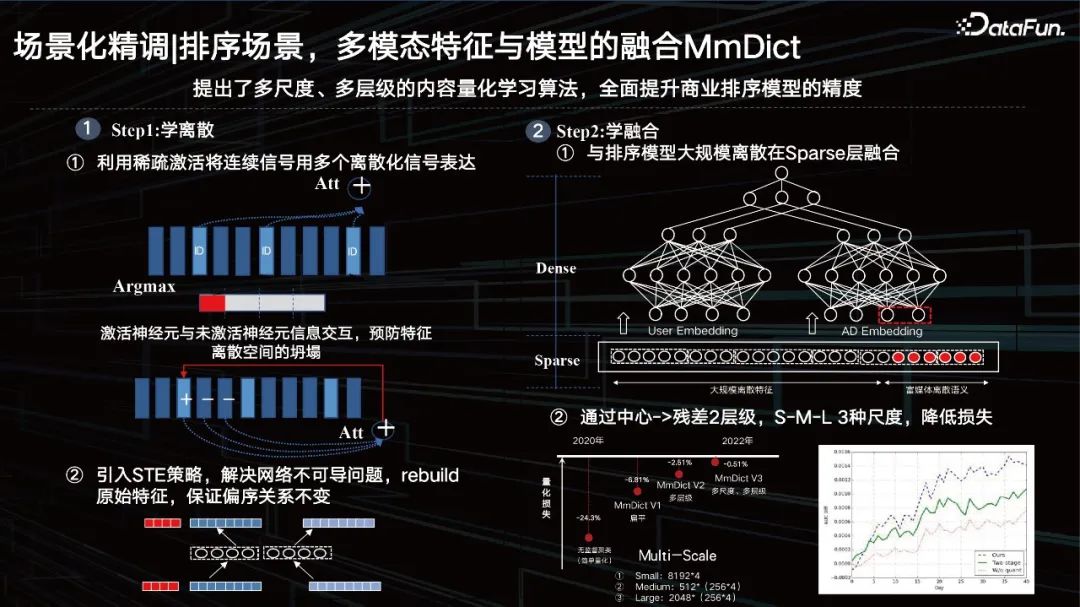
主要分两步,第一步是学离散,第二步是学融合。 Step1:学离散
① 利用稀疏激活将连续信号用多个离散化信号表达;也就是通过稀疏激活的方式把稠密特征进行切分,然后去激活对应多模态codebook里面的ID,但这里面其实只有argmax操作,会引来不可导的问题,同时为了去防止特征空间的坍塌,加入了激活神经元与未激活神经元信息交互。 ② 引入 STE 策略,解决网络不可导问题, rebuild原始特征,保证偏序关系不变; 通过encoder-decoder的方式,把稠密特征进行序列量化,再通过正确的方式把量化出来的特征进行还原。还原前后要保证它的偏序关系不变,几乎可以控制特征在具体任务上的量化损失小于1%,这样的ID具备了当下数据分布个性化的同时,还具有泛化特性。 Step2:学融合
① 与排序模型大规模离散在 Sparse层融合; 那么刚才提到的隐层复用直接放在上面去,其实效果一般。如果把它ID化,量化之后,到sparse特征层和其他类的特征进行融合,有着比较好的效果。 ② 通过中心 -> 残差2层级, S-M-L 3种尺度,降低损失; 当然我们也采用了一些残差,以及多尺度的方式。从2020年开始,我们把量化的损失逐步压低,去年达到了一个点以下,这样就可以在大模型抽出来特征之后,我们用这种可学习量化的方式对视觉内容进行刻画,具备语义关联ID的特征其实非常适配我们现在的商业系统,包括推荐系统的ID的这样一个探索的研究方式。02************擎舵
1. 商业AIGC 深度结合营销,提升内容生产力,效率效果联动优化

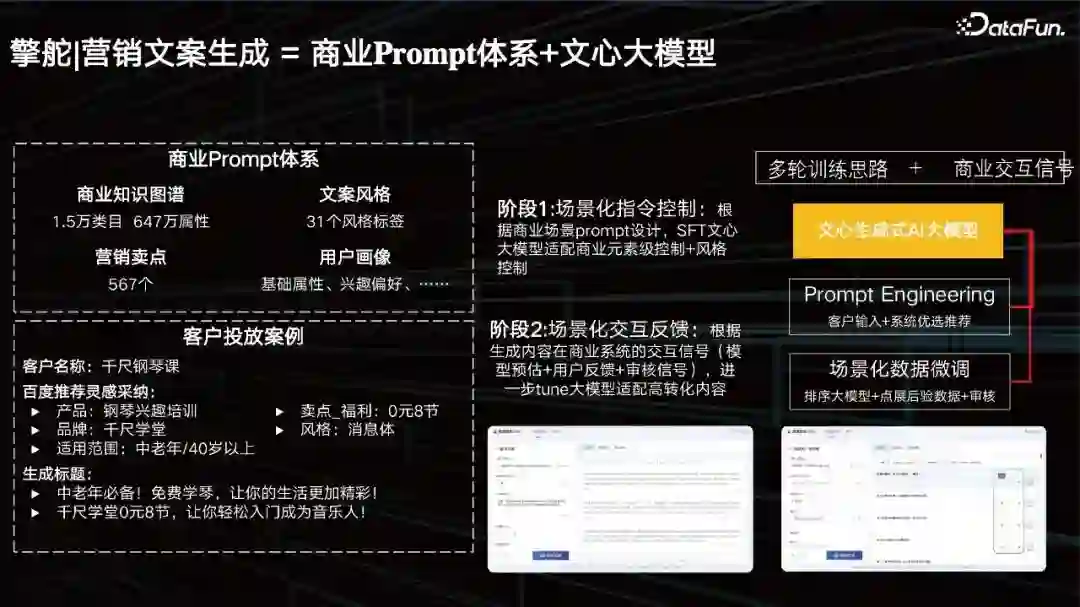
百度营销AIGC创意平台从灵感到创作,再到投放形成了一个完美的闭环。从解构、生成、反馈都在推进优化我们的AIGC。 灵感:AI理解(内容&用户理解)。AI能不能帮助我们去找到什么样的Prompt是好的。从素材洞察到创意指导。 创作:AIGC,如文本生成,图片生成,还有数字人、视频生成等等。 投放:AI优化。从经验试错到自动优化。 2. 营销文案生成 = 商业 Prompt 体系+ 文心大模型

一个好的商业Prompt,具备以下一些要素: * 知识图谱,比如说卖车,车到底需要包含哪些商业元素,仅有品牌是不够的,广告主更希望有一个完整的知识体系; * 风格,例如现在『文艺范』的宣传体,其实是需要把它抽象成一些标签,去帮助我们判断主要是什么样的营销标题或营销的一些描述。 * 卖点,卖点其实就是产品属性的一个特征,即为最强有力的消费理由。 * 用户画像,是根据目标的行为观点的差异区分为不同类型,迅速组织在一起,然后把新得出的类型提炼出来,形成一个类型的用户画像。
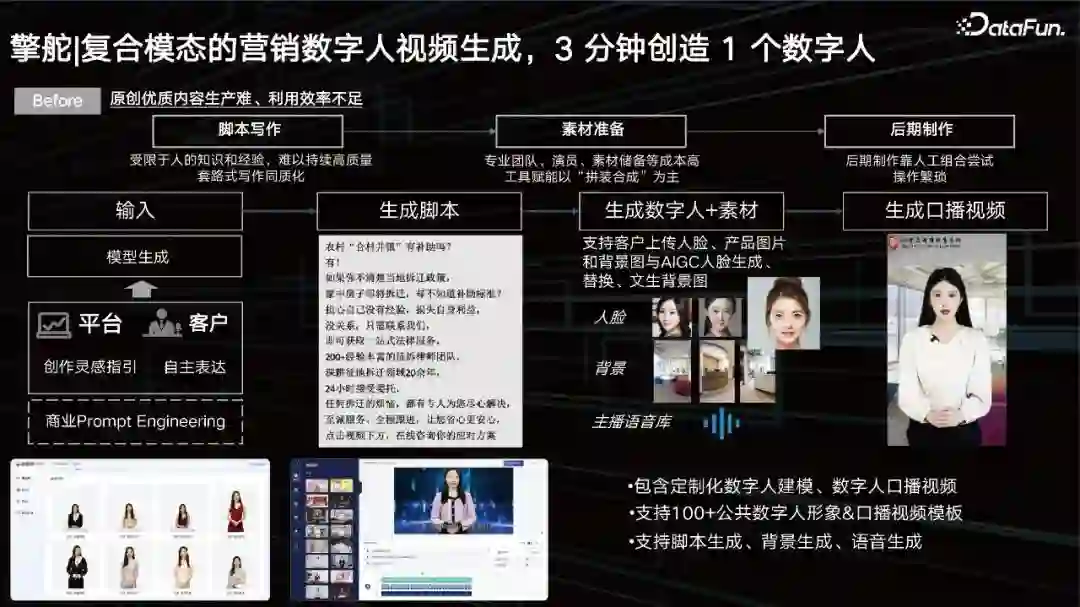
3. 复合模态的营销数字人视频生成, 3 分钟创造 1 个数字人
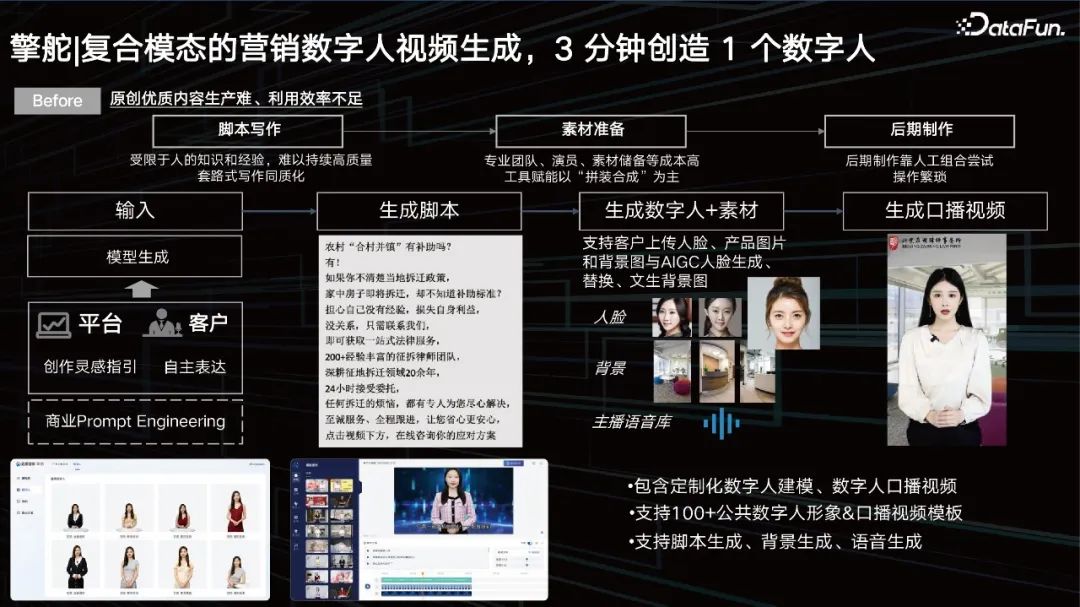
视频生成目前已经比较成熟。但它其实依然存在着一些问题: 脚本写作:受限于人的知识和经验,难以持续高质量写作,同质化严重; 素材准备:专业团队、演员、素材储备等成本高工具赋能,以“拼装合成”为主; 后期制作:后期制作靠人工试错,操作繁琐。 前期通过prompt来输入,想生成一个什么样的视频,希望选择一个什么样的人,让他去说什么,都通过prompt来输入,然后我们根据其诉求,能够准确控制我们的大模型去生成相应的脚本。 接下来我们可以通过我们的数字人库去召回相应的数字人,但是可能利用AI技术进一步提升数字人的多样性,比如人脸替换、背景替换、口音语音替换去适配我们的prompt,最后脚本、数字人唇形替换、背景替换、人脸替换,视频压制之后,就可以得到一个口播视频。客户得以利用数字人的方式去介绍产品对应的一些营销卖点。这样3分钟即可做好一个数字人,极大地提升了广告主做数字人的能力。 4. 营销海报图生成,结合多模态表征的营销图片生成
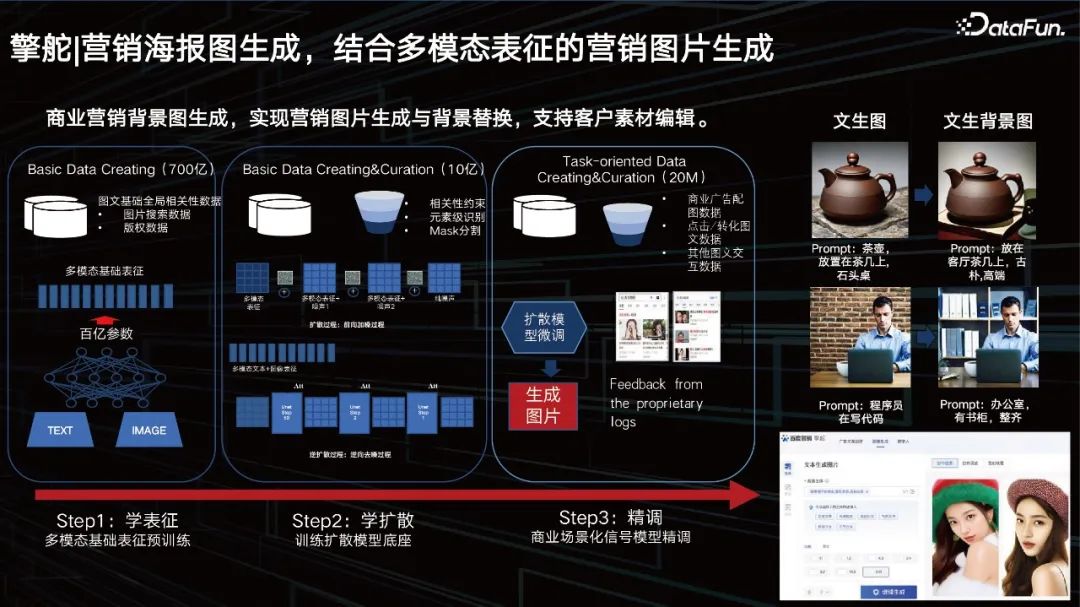
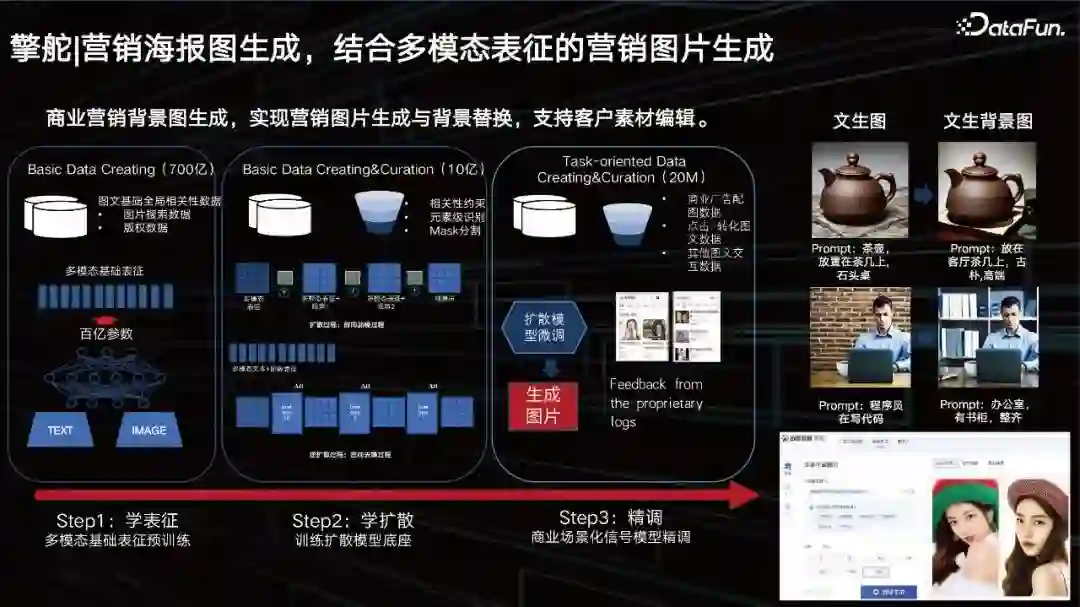
大模型还可以帮助商业实现营销海报的生成和商品背景的替换。我们已有一个百亿规模的多模态表征,中间这一层是我们学的一个扩散,我们基于好的动态表征去学unet。通过大数据的训练之后,客户还希望有一些特别个性化的东西,所以我们还需要加入一些微调的方式。 我们提供了一个帮助客户微调的方案,一个大模型动态加载小参数的方案,这也是目前业界的一个通用的解决方案。 首先我们为客户提供一个生图能力,客户可以通过编辑或者Prompt去改变这个图片背后的背景。
以上就是本次分享的内容,谢谢大家。


分享嘉宾
INTRODUCTION

杨羿
百度
商业策略中台技术负责人
统计学硕士毕业,17年加入百度,负责商业策略中台与AIGC相关技术。在文、图、视频、落地页等多模态理解、生成方面,突破了多项复杂技术问题,广泛提升了公司系统模型对富媒体内容的高阶认知和常识推理的能力,大幅提升了公司商业系统的变现效果。主持的项目多次获得公司及部门奖励,其中多模态理解项目-“视界”项目获得百度2021年最高奖Top8。近年来个人提出的多项核心算法,被KDD、SIGIR、EMNLP、CIKM等国际顶级会议所接收,总计发表论文10+篇。