万字长文带你看尽深度学习中的各种卷积网络

AI 科技评论按:深度学习中的各种卷积网络大家知多少?对于那些听说过却又对它们没有特别清晰的认识的小伙伴们,Kunlun Bai 这篇文章非常值得一读。Kunlun Bai 是一位人工智能、机器学习、物体学以及工程学领域的研究型科学家,在本文中,他详细地介绍了 2D、3D、1x1 、转置 、空洞(扩张)、空间可分离、深度可分离、扁平化、 分组等十多种卷积网络类型。AI 科技评论编译如下。
如果你曾听过深度学习的各种卷积网络(例如 2D/3D/ 1x1 / 转置 /空洞(扩张)/ 空间可分离 / 深度可分离 /扁平化 / 分组 / 混洗分组卷积)并疑惑它们到底都是什么的话,你可以通过这篇文章了解它们实际的工作原理。
在文中,我概括性地介绍了在深度学习中常见的几种卷积,并采用了大家都能够明白的方式来解释它们。针对这一主题,这篇文章以外也有其他的一些文章可供大家参考,我将这些文章的链接附在了文末参考部分,大家可前往阅读。
希望这篇文章能够帮助大家建立起对这几种卷积的认知,并为大家的学习/研究带来有用的参考价值。
本文的内容包括:
1. 卷积 VS 互关联
2. 深度学习中的卷积网络(单通道版,多通道版)
3.3D 卷积
4. 1x1 卷积
5. 卷积算法
6. 转置卷积(反卷积,棋盘效应)
7. 空洞卷积(扩张卷积)
8. 可分离卷积(空间可分离 卷积,深度可分离卷积)
9. 扁平化卷积
10. 分组卷积
11. 混洗分组卷积
12. 逐点分组卷积
1. 卷积 VS 互关联
卷积是一项广泛应用于信号处理、图像处理以及其他工程/科学领域的技术。在深度学习中,卷积神经网络(CNN)这一模型架构就由这项技术命名的。然而,深度学习中的卷积本质上就是信号/图像处理中的互关联(cross-correlation)。二者间只有细微的差别。
不深入考虑细节的话,二者的区别在于:在信号/图像处理中,卷积被定义为:
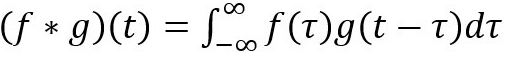
它的定义是:一个函数经过翻转和移动后与另一个函数的乘积的积分。下面的图像形象化地展示了这个思想:
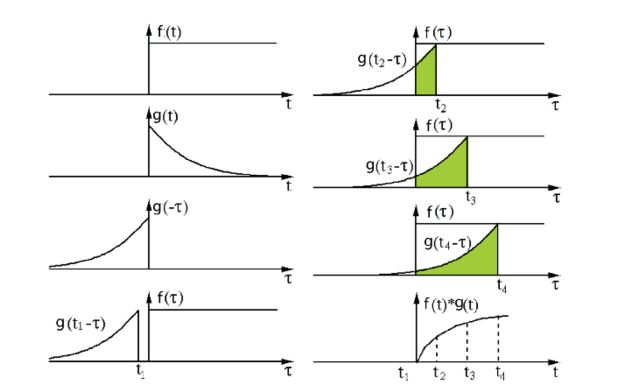
信号处理中的卷积。过滤函数 g 经过翻转然后沿着横轴滑动。对于该函数在横轴上滑过的每个点的位置,都计算出函数 f 与翻转后的函数 g 的重合区域。这个重合的区域就是函数 g 在横轴上滑过的某个特定位置的卷积值。图像来源:http://fourier.eng.hmc.edu/e161/lectures/convolution/index.html
在这里,函数 g 是一个过滤函数。这个函数经过翻转然后沿着横轴滑动。对于该函数在横轴上滑过的每个点的位置,都计算出函数 f 与翻转后的函数 g 的重合区域。这个重合的区域就是函数 g 在横轴上滑过的某个特定位置的卷积值。
而另一方面,互关联是这两个函数的滑动的点积(dot product)或滑动的内积(inner-product)。互关联的过滤函数不经过翻转,它直接滑动通过函数 f。函数 f 和函数 g 的重合区域就是互关联。下图展示了卷积和互关联的区别:
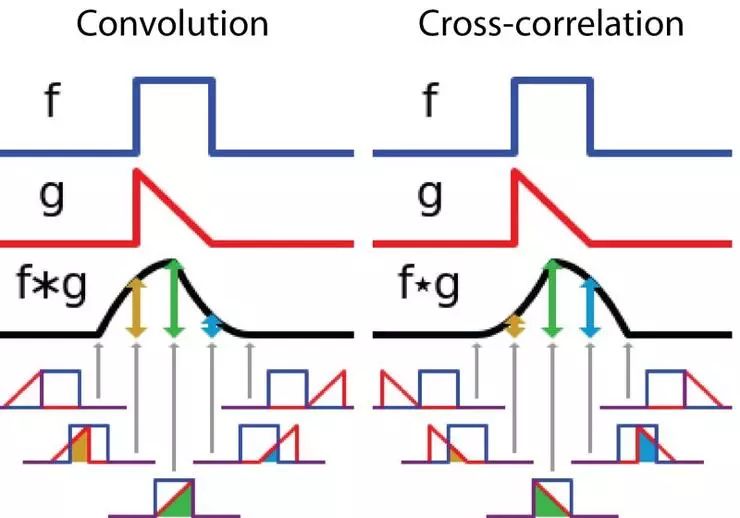
在信号处理中,卷积和互关联的区别。图像来源:https://en.wikipedia.org/wiki/Convolution
在深度学习中,卷积中的过滤函数是不经过翻转的。严格来说,它就是互关联。我们本质上就是在执行 element-wise 乘法和加法。但是,这个「卷积」仅在深度学习中被称为卷积,可以这样做的原因是因为卷积在训练期间就学到了过滤函数的权重,如果上面示例中的经翻转的函数 g 是正确的函数,那么经过训练后,卷积所学到的过滤函数就会找到翻转后的函数 g。因此,在正确的卷积中,就不需要在训练前早早地翻转过滤函数。
2. 深度学习中的卷积
执行卷积的目的就是从输入中提取有用的特征。在图像处理中,执行卷积操作有诸多不同的过滤函数可供选择,每一种都有助于从输入图像中提取不同的方面或特征,如水平/垂直/对角边等。类似地,卷积神经网络通过卷积在训练期间使用自动学习权重的函数来提取特征。所有这些提取出来的特征,之后会被「组合」在一起做出决策。
进行卷积操作有许多优势,例如权重共享(weights sharing)和平移不变性(translation invariant)。此外,卷积也可以考虑到像素的空间关系。这些优势都非常有帮助,尤其是在许多的计算机视觉任务中,因为这些任务往往涉及到对某些组成部分与其他组成部分有某些空间关系的目标进行识别(例如一只狗的身体通常是跟它的脑袋、四条腿以及尾巴相连的)。
2.1 卷积:单通道版
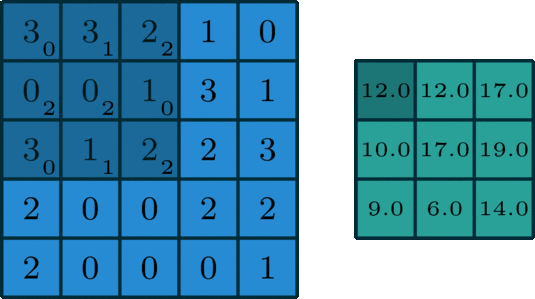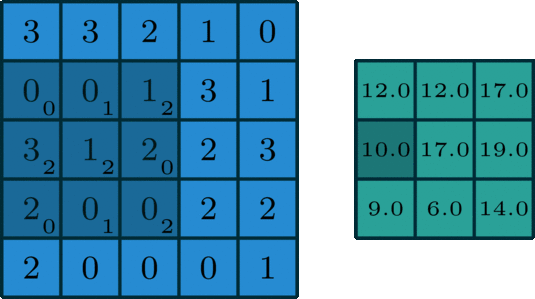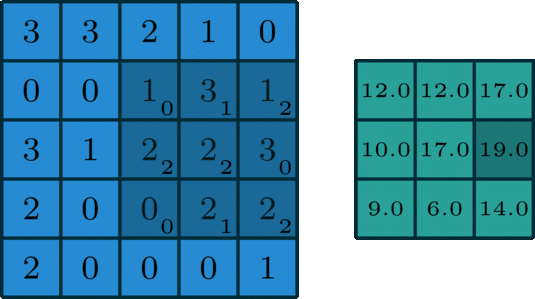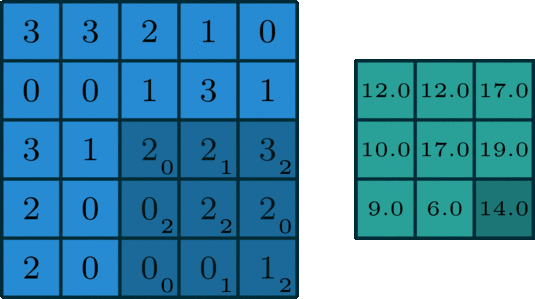
面向单通道的卷积,图像源自:https://towardsdatascience.com/intuitively-understanding-convolutions-for-deep-learning-1f6f42faee1
在深度学习中,卷积就是元素级别( element-wise) 的乘法和加法。对于一张仅有 1 个通道的图像,卷积过程如上图所示,过滤函数是一个组成部分为 [[0, 1, 2], [2, 2, 0], [0, 1, 2]] 的 3 x 3 矩阵,它滑动穿过整个输入。在每一个位置,它都执行了元素级别的乘法和加法,而每个滑过的位置都得出一个数字,最终的输出就是一个 3 x 3 矩阵。(注意:在这个示例中,卷积步长=1;填充=0。我会在下面的算法部分介绍这些概念。)
2.2 卷积:多通道版
在许多应用中,我们处理的是多通道的图像。一个典型的案例就是 RGB 图像,如下图所示,每一个 RGB 通道都分别着重于原始图像的不同方面。

每一个 RGB 通道都分别着重于原始图像的不同方面,图片拍摄于:中国云南元阳
另一个多通道数据的案例就是卷积神经网络中的层。一个卷积网络层往往都由多个通道(一般为数百个通道)组成,每一个通道描述出前一个层的不同方面。那我们如何实现不同深度的层之间的过渡呢?又如何将深度为 n 的层转化为后面的深度为 m 的层呢?
在介绍这个过程之前,我们先搞清楚几个名词:层(layer)、通道(channel)、特征映射(feature map)、过滤器(filter)以及卷积核(kernel)。从层级角度来说,「层」和「过滤器」的概念属于一个层级,而「通道」和「卷积核」都在下一个层级。「通道」和「特征映射」是指同一个东西。一层可以有多个通道(或特征映射);如果输入的是 RGB 图像,那这个输入层有 3 个通道。「通道」一般用来形容「层」的架构。类似地,「卷积核」则用来形容「过滤器」的架构。
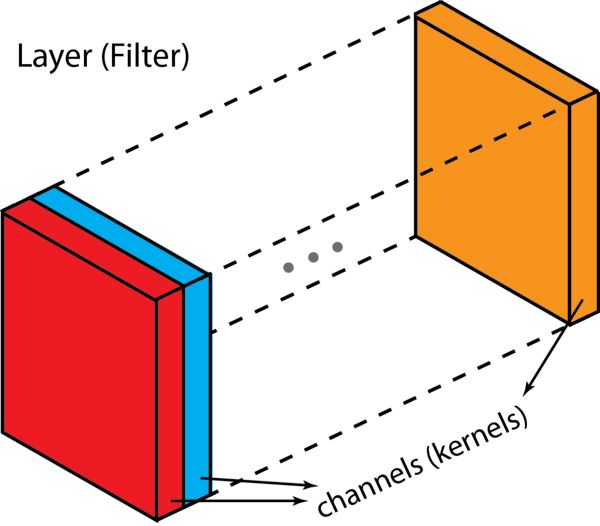
「层」(「过滤器」)和「通道」(「卷积核」)之间的区别
过滤器和卷积核之间的区别非常微妙,有时候,二者可以交替使用,这无疑就制造了些困惑。但根本上来讲,二者还是有些细微区别的:「卷积核」指的是指权重组成的 2D 数组 ;「过滤器」则是由多个卷积核堆叠在一起的 3D 架构概念。对于一个 2D 过滤器来说,过滤器就相当于卷积核,但是对于一个 3D 过滤器以及深度学习中的大多数卷积而言,一个过滤器由一组卷积核组成。每个卷积核都是独一无二的,强调了输入通道的不同方面。
带着对这些概念的了解,下面让我们一起来看看多通道卷积。生成一个输出通道,就需要将每一个卷积核应用到前一层的输出通道上,这是一个卷积核级别的操作过程。我们对所有的卷积核都重复这个过程以生成多通道,之后,这些通道组合在一起共同形成一个单输出通道。下图可以让大家更清晰地看到这个过程。
这里假设输入层是一个 5 x 5 x 3 矩阵,它有 3 个通道。过滤器则是一个 3 x 3 x 3 矩阵。首先,过滤器中的每个卷积核都应用到输入层的 3 个通道,执行 3 次卷积后得到了尺寸为 3 x 3 的 3 个通道。
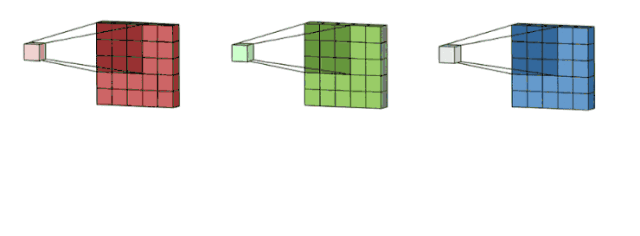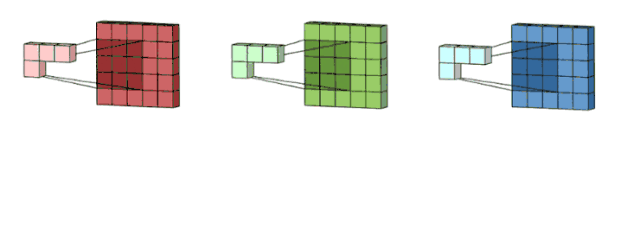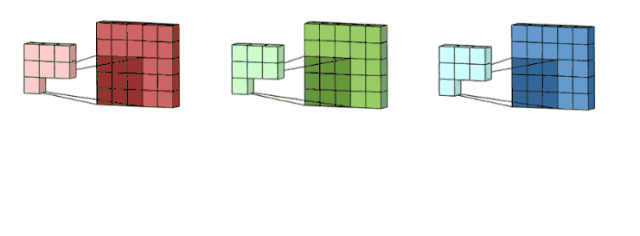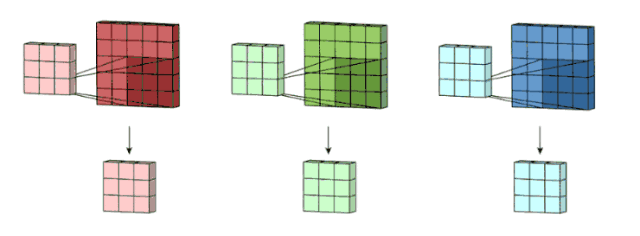
面向多通道的 2D 卷积的第一步:过滤器每个卷积核分别应用到输入层的 3 个通道上。图片源自:https://towardsdatascience.com/intuitively-understanding-convolutions-for-deep-learning-1f6f42faee1
之后,这 3 个通道都合并到一起(元素级别的加法)组成了一个大小为 3 x 3 x 1 的单通道。这个通道是输入层(5 x 5 x 3 矩阵)使用了过滤器(3 x 3 x 3 矩阵)后得到的结果。
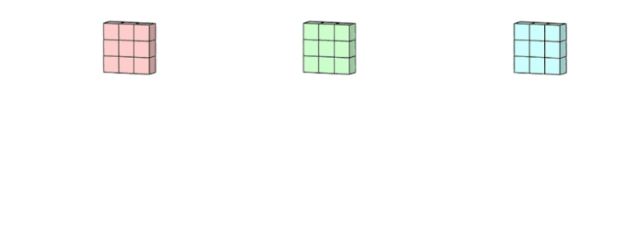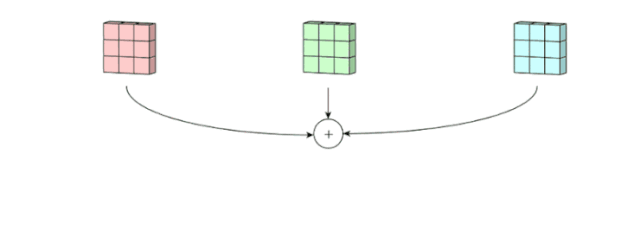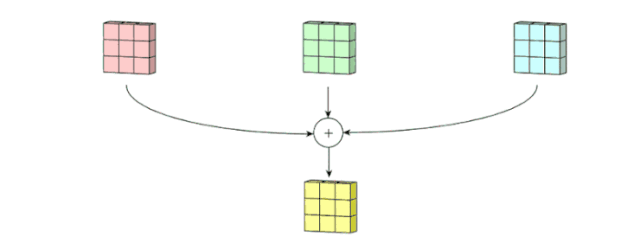
面向多通道的 2D 卷积的第二步:3 个通道都合并到一起(元素级别的加法)组成了一个大小为 3 x 3 x 1 的单通道。图片源自:https://towardsdatascience.com/intuitively-understanding-convolutions-for-deep-learning-1f6f42faee1
同样地,我们可以将这个过程视作将一个 3D 过滤器矩阵滑动通过输入层。注意,这个输入层和过滤器的深度都是相同的(即通道数=卷积核数)。这个 3D 过滤器仅沿着 2 个方向(图像的高&宽)移动(这也是为什么 3D 过滤器即使通常用于处理 3D 体积数据,但这样的操作还是被称为 2D 卷积)。在每一个滑过的位置,我们都执行元素级别的乘法和加法,最终得出一个数值。下面这个例子中,过滤器横向滑过 5 个位置、纵向滑过 5 个位置。全部完成后,我们得到了一个单输出通道。
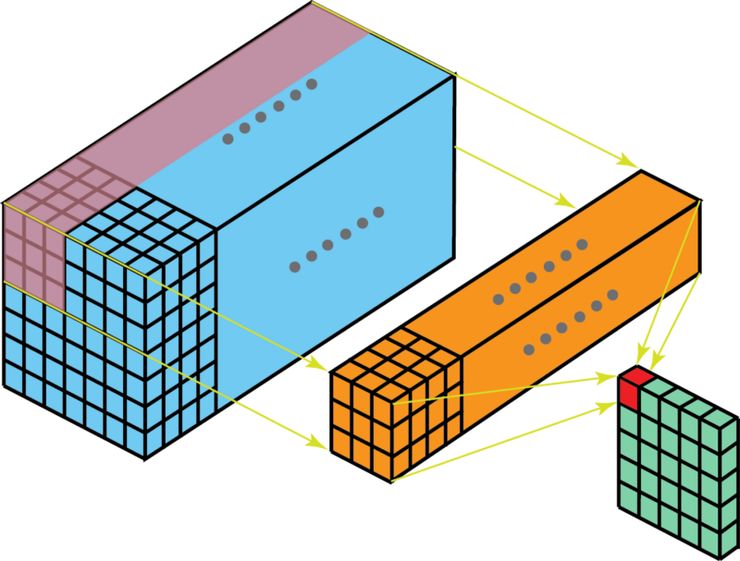
看待 2D 卷积的另一个角度:将这个过程视作将一个 3D 过滤器矩阵滑动通过输入层。注意,这个输入层和过滤器的深度都是相同的(即通道数=卷积核数)。这个 3D 过滤器仅沿着 2 个方向(图像的高&宽)移动(这也是为什么 3D 过滤器即使通常用于处理 3D 体积数据,但这样的操作还是被称为 2D 卷积)。输出是一个 1 层的矩阵。
现在我们可以看到如何在不同深度的层之间实现过渡。假设输入层有 Din 个通道,而想让输出层的通道数量变成 Dout ,我们需要做的仅仅是将 Dout 个过滤器应用到输入层中。每一个过滤器都有 Din 个卷积核,都提供一个输出通道。在应用 Dout 个过滤器后,Dout 个通道可以共同组成一个输出层。
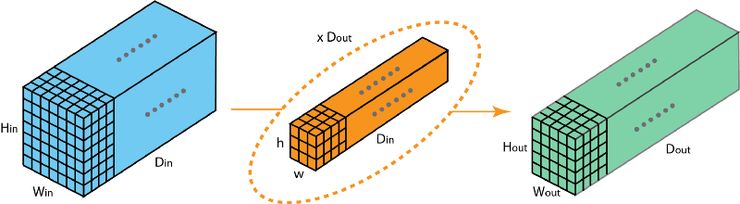
标准 2D 卷积。通过使用 Dout 个过滤器,将深度为 Din 的层映射为另一个深度为 Dout 的层。
3.3D 卷积
在上部分的最后一张图中,我们看到了将卷积在 3D 体积上的执行情况。但是一般而言,我们依旧将这一操作视为深度学习中的 2D 卷积——3D 体积数据上的 2D 卷积:其过滤器和输入层的深度是一样的;3D 过滤器仅沿着 2 个方向(图像的高&宽)移动。这样操作得出的结果就是一个 2D 图像(仅有 1 个通道)。
有 2D 卷积,自然就有 3D 卷积。3D 卷积是 2D 卷积的一般化。在 3D 卷积中,过滤器的深度要比输入层的深度更小(卷积核大小<通道大小),结果是,3D 过滤器可以沿着所有 3 个方向移动(高、宽以及图像的通道)。每个位置经过元素级别的乘法和算法都得出一个数值。由于过滤器滑动通过 3D 空间,输出的数值同样也以 3D 空间的形式呈现,最终输出一个 3D 数据。
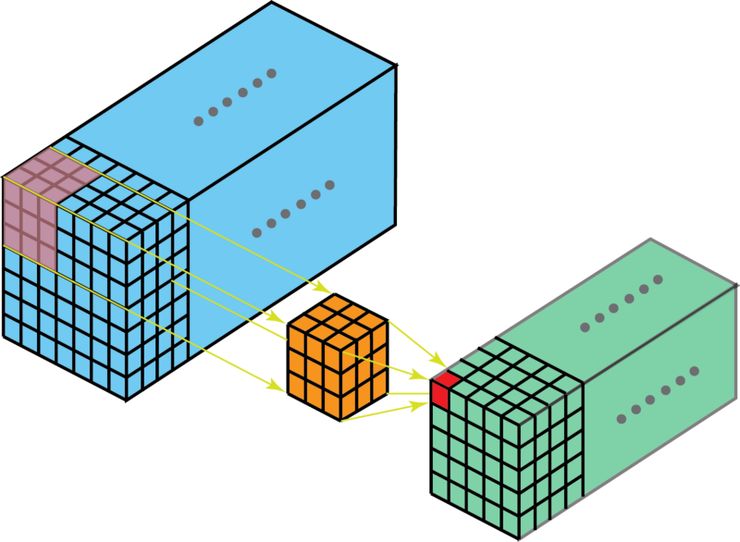
在 3D 卷积中,过滤器的深度要比输入层的深度更小(卷积核大小<通道大小),结果是,3D 过滤器可以沿着所有 3 个方向移动(高、宽以及图像的通道)。每个位置经过元素级别的乘法和算法都得出一个数值。由于过滤器滑动通过 3D 空间,输出的数值同样也以 3D 空间的形式呈现,最终输出一个 3D 数据。
和对 2D 区域中目标的空间关系进行解码的 2D 卷积相似,3D 卷积也可以描述 3D 空间中目标的空间关系。对于一些应用来说,这种 3D 关系很重要,例如在 CT 和 MRI 等生物医学图像的 3D 分割/重建中,这些图像的目标如血管都是蜿蜒分布在 3D 空间中的。
4. 1x1 卷积
由于我们在前一个部分——3D 卷积中探讨了深度级别的操作,接下来让我们了解另一个有趣的操作,1 x 1 卷积。
你或许想知道为什么这个卷积是有帮助作用的。我们刚刚是否让输入层中的每个数值都乘以了一个数值?是,也不是。对于仅有 1 个通道的层来说,这项操作不重要。在上面的示例中,我们让每一个组成部分都乘以了一个数值。
如果输入层有多个通道,那事情就变得非常有趣了。下图阐述了 1 x 1 卷积在一个维度为 H x W x D 的输入层上的操作方式。经过大小为 1 x 1 x D 的过滤器的 1 x 1 卷积,输出通道的维度为 H x W x 1。如果我们执行 N 次这样的 1 x 1 卷积,然后将这些结果结合起来,我们能得到一个维度为 H x W x N 的输出层。
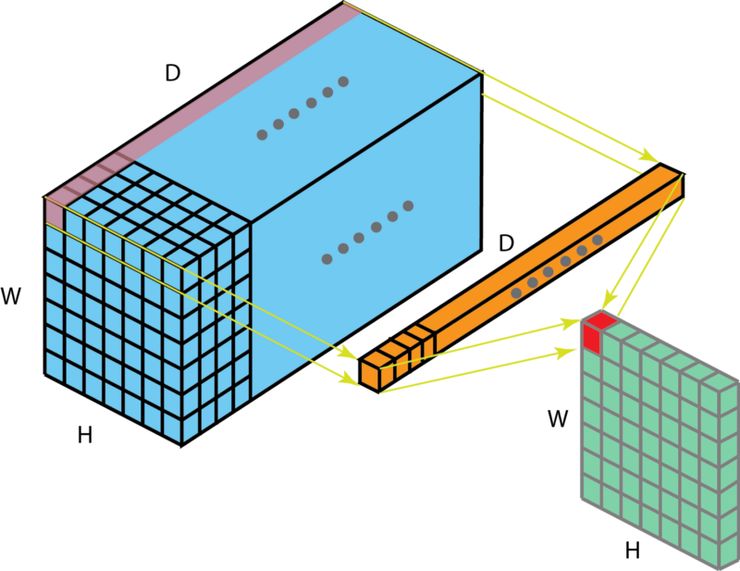
过滤器大小为 1 x 1 x D 的 1 x 1 卷积
1 x 1 卷积最初是在 Network-in-network 的论文(论文阅读地址:https://arxiv.org/abs/1312.4400)中被提出的,之后在谷歌的 Inception 论文(论文阅读地址:https://arxiv.org/abs/1409.4842)中被大量使用。1 x 1 卷积具有如下几个优势:
减少维度以实现更有效率的计算;
进行更有效率的低维度嵌入,或者对特征进行池化;
卷积以后反复应用非线性特征。
前两个优势我们可以从上面的图像中观察到。执行 1 x 1 卷积后,我们明显减少了维度的深度级别。假设原始输入有 200 个通道,1 x 1 卷积会将这些通道(特征)嵌入到一个单通道中。第三个优势在 1 x 1 卷积执行后才显现出来,它会将线性整流函数(ReLU)等非线性激活函数添加进模型中。非线性特征让网络学习更复杂的函数。
谷歌的 Inception 论文中也对这些优势进行了描述:
上面这个模块(至少在这个朴素的形式中)的一个大问题是,即便是数量适度的 5 x 5 卷积,在有大量过滤器的卷积层之上的计算也会过于昂贵。
这就给提出的框架带来了第二个思路:明智地减少维度并进行投影,不然就会过度增加对于计算的要求。这是基于成功实现嵌入上的:即便是低维度的嵌入也可以容纳大量关于相对较大的图像块的信息... 也就是说,在执行计算昂贵的 3 x 3 卷积和 5 x 5 卷积前,往往会使用 1 x 1 卷积来减少计算量。此外,它们也可以利用调整后的线性激活函数来实现双重用途。
针对 1 x 1 卷积,Yann LeCun 提出了一个非常有趣的角度:「在卷积网络中,不存在像「全连接层」这样的东西,而只有含有一些 1x1 卷积核和 1 个全连接表的卷积层」

5. 卷积算法
我们现在知道了如何处理卷积的深度。接下来讨论一下怎样处理在其他两个方向(高&宽)中的卷积,以及重要的卷积算法(convolution arithmetic)。
这里有一些需要了解的名词:
卷积核大小(Kernel size):卷积核在前一部分已经讨论过了。卷积核大小确定卷积的视野。
卷积步长(Stride):它确定的是卷积核滑动通过图像的步长。步长为 1 表示卷积核一个像素一个像素地滑动通过图像;步长为 2 则表示卷积核在图像上每滑动一次就移动了 2 个像素(即跳过 1 个像素)。对于下面这个案例中的图像,我们采用大于或等于 2 的步长。
填充(Padding):填充定义如何处理图像的边界。如果有必要的话,可以通过将输入边界周围的填充设置为 0,这样的话,经过填充后的卷积(Tensorflow 中的「相同」填充)就可以保持空间输出维度与输入图像的维度一样。另一方面,如果不在输入边界周围添加 0 填充,未填充的卷积(Tensorflow 中的「有效」填充)仅对输入图像的像素执行卷积,输出大小也会小于输入大小。
下图表示使用卷积核大小为 3、步长为 1;填充为 1 的 2D 卷积:
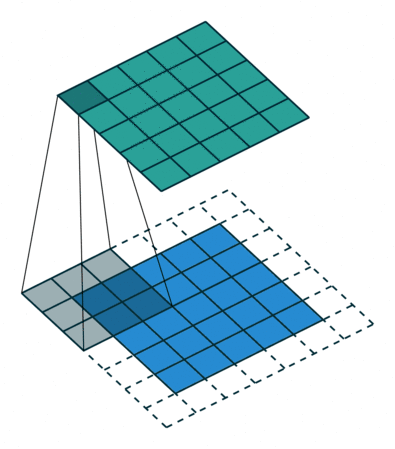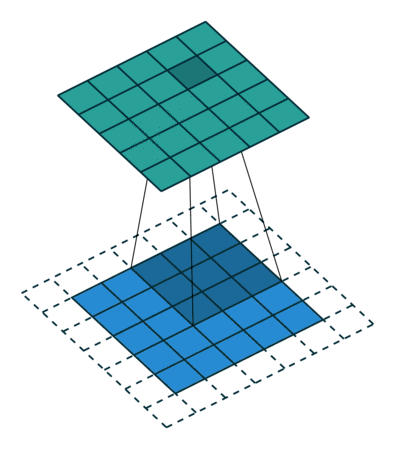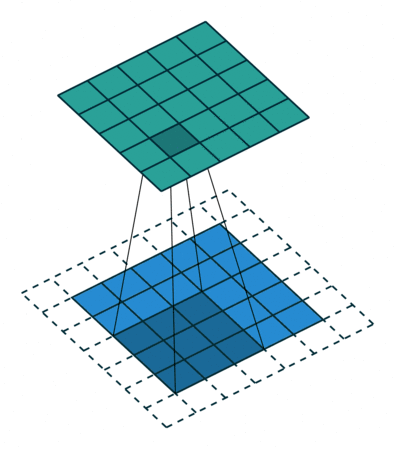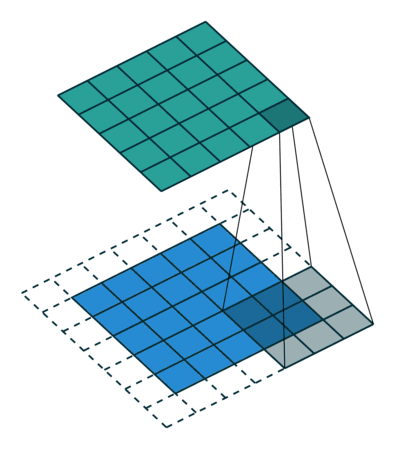
这里有一篇不错的文章(A guide to convolution arithmetic for deep learning,https://arxiv.org/abs/1603.07285)详细地描述了算法,大家可前往阅读。这篇文章对其进行了详细介绍,并针对不同的卷积核大小、卷积步长以及填充分别进行了案例分析。这里我仅仅概括出了最常用的结果:
对于一个大小为 i、卷积核大小为 k、填充为 p 以及卷积步长为 s 的输入图像,经过卷积的输出图像的大小为 o:
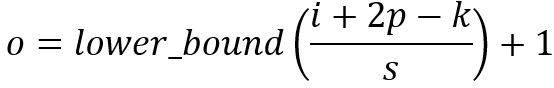
6. 转置卷积(反卷积)
对于许多应用以及在许多网络架构中,我们通常需要朝与标准卷积相反的方向做转换,例如,当我们想要执行上采样(up-sampling)时。这些案例其中就包括生成高分辨率图像以及在自动编码器或语义分割中将低维度特征映射映射到高维度空间中。(在随后的案例中,语义分割首先在编码器中提取特征映射,然后在解码器中还原原始图像的大小从而能够在原始图像中对每一个像素进行分类。)
传统上,研究者可以通过应用插值(interpolation)方案或者手动创建规则来实现上采样。神经网络等现代架构则反过来趋向于让网络自己自动学习合适的转换,而不需要人类的干预。我们可以使用转置卷积(Transposed Convolution)来实现这一点。
在书面表达上,转置卷积也称作反卷积(deconvolution),或小数步长的卷积(fractionally strided convolution)。不过值得一提的是,将其称作「反卷积」并不是那么合适,因为转置卷积并不完全是信号/图像处理中所定义的反卷积。从技术上来说,信号处理中的反卷积是卷积的逆向操作,跟这里所说的转置卷积不一样。正因为此,一些论文作者强烈反对将转置卷积称作反卷积,而大众要这样称呼主要是为了简单起见。随后,我们会探讨为什么将这种操作称作转置卷积才是自然且更合适的。
我们可以直接使用卷积来实现转置卷积。例如在下图的案例中,我们 2 x 2 的输入上做转置卷积:其卷积核为 3 x 3,卷积步长为 1,填充为 2 x 2 的空格。上采样的输出大小为 4 x 4。
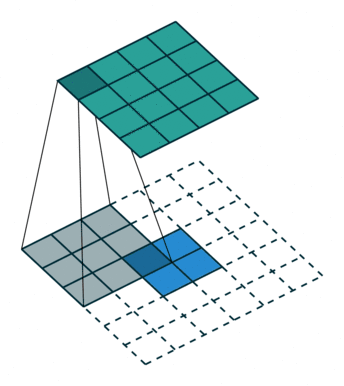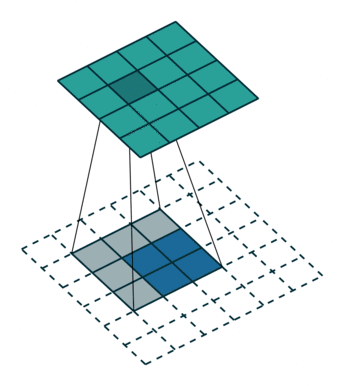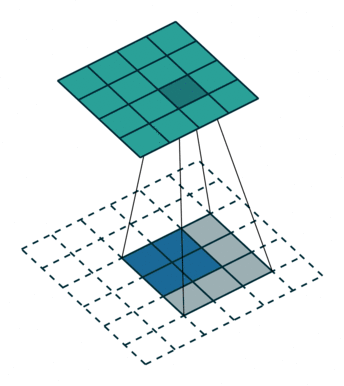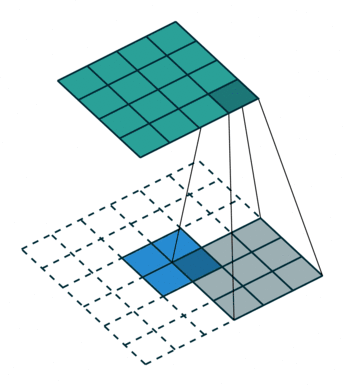
将 2 x 2 输入上采样为 4 x 4 输出,图片源自: https://github.com/vdumoulin/conv_arithmetic
非常有趣的是,研究者可以通过应用花式填充和步长,将相同的 2 x 2 输入图像映射出不同的图像大小。下图中,在同一个卷积核为 3 x 3,卷积步长为 1,填充为 2 x 2 空格的 2 x 2 的输入(输入之间插入了一个空格)上做转置卷积,得出的输出大小为 5 x 5。
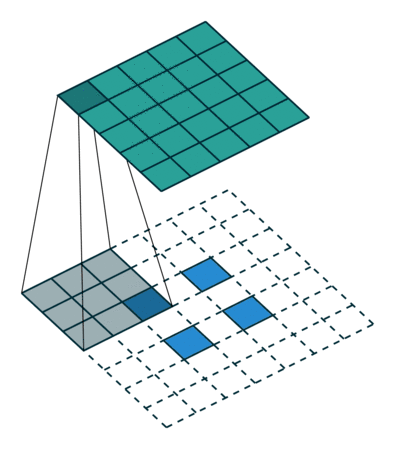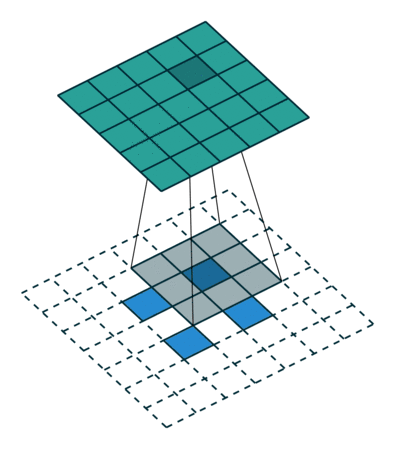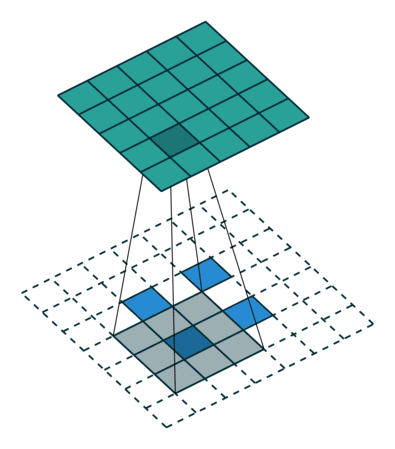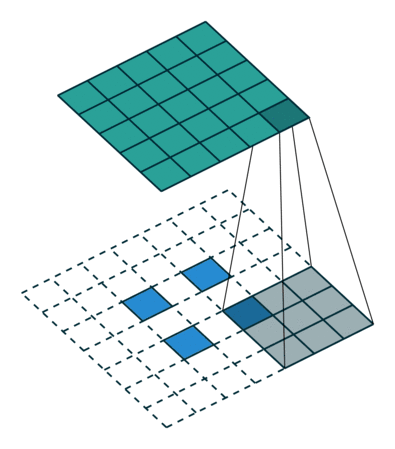
将 2 x 2 输入上采样为 5 x 5 输出,图片源自: https://github.com/vdumoulin/conv_arithmetic
通过观察上述案例中的转置卷积,我们可以初步建立一些认知。但是要想较好地掌握它的应用,在电脑上看看它怎样通过矩阵乘法来实现会比较有用。从中,我们还可以了解到为什么「转置卷积」这个名字更合适。
在卷积中,我们设定卷积核为 C,输入图像为 Large,卷积输出的图像为 Small。在做卷积(矩阵乘法)后,我们将大图像下采样(down-sample)为小的输出图像。矩阵乘法中的卷积实现遵循 C x Large = Small。
下面案例显示了这项操作如何实现。它将输入也压平为 16 x 1 矩阵,之后将卷积核转换为一个稀疏矩阵 (4 x 16),接着在稀疏矩阵和压平的输入间执行矩阵乘法运算,最终得出的矩阵(4 x 1)转换回 2 x 2 的输出。
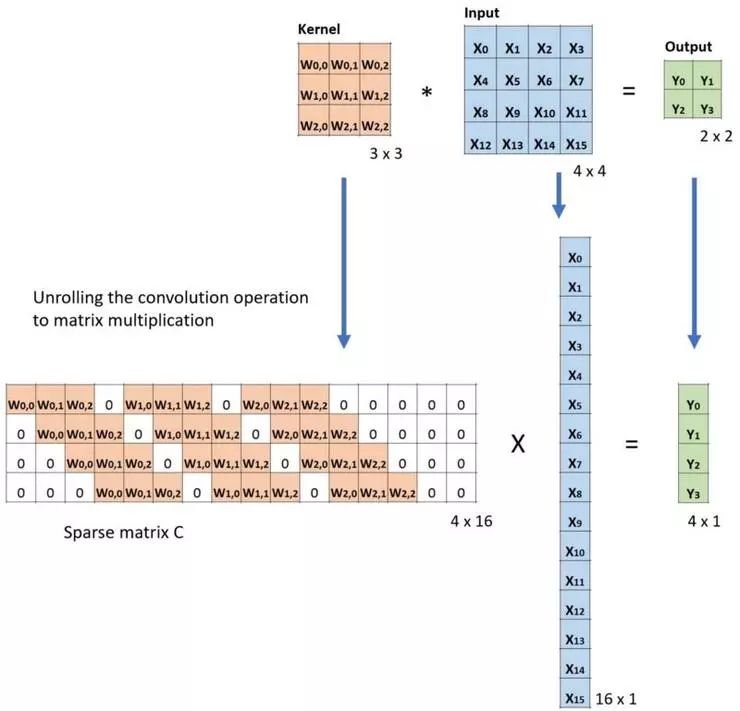
卷积的矩阵乘法:从大小 4 x 4 为 Large 输入图像到大小为 2 x 2 的 Small 输出图像
现在,如下图所示,如果我们对等式两边的矩阵 CT 进行多次转置,并利用一个矩阵和其转置矩阵相乘得出一个单元矩阵的属性,我们可以得出下面的运算公式:CT x Small = Large。
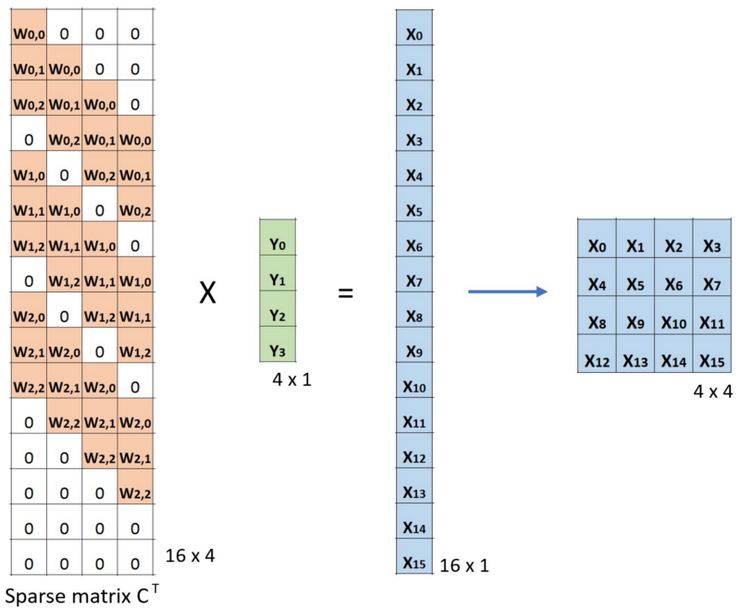
卷积的矩阵乘法:从大小 2x 2 为 Large 输入图像到大小为 4 x 4 的 Small 输出图像
正如你在这里看到的,转置卷积执行的是从小图像到大图像的上采样。这也是我们所要实现的。而现在,你也可以了解到「转置卷积」这个名字的由来。
转置卷积的通用算法可以在《深度学习的卷积算法指南》「A guide to convolution arithmetic for deep learning」这篇文章的「Relationship 13」和「Relationship 14」章节中找到。
6.1 棋盘效应
所谓的「棋盘效应」(Checkerboard artifacts),是研究人员在使用转置卷积时可以观察到的一种令人不快的现象(奇怪的棋盘格状伪影)。

「棋盘效应」的一些案例。图片源自论文「Deconvolution and Checkerboard Artifacts」,https://distill.pub/2016/deconv-checkerboard/
《反卷积和棋盘效应》(Deconvolution and Checkerboard Artifacts,https://distill.pub/2016/deconv-checkerboard)对于这一现象有一个非常好的阐述。大家可以前往阅读这篇文章了解详细内容。这里我仅仅概括出关键点。
造成棋盘效应的原因是转置卷积的「不均匀重叠」(uneven overlap)。这种重叠会造成图像中某个部位的颜色比其他部位更深。
在下图中,顶部这层是输入层,底部这层则是操作转置卷积后的输出层。在转置卷积过程中,小的这层映射到大的那层。
在案例(a)中,其卷积步长为 1,过滤器大小为 2。正红线所标出的,输入图像上的第一个像素映射为输出图像上的第一个和第二个像素。绿线标出的则是输入图像上的第二个像素映射为输出图像上的第二个和第三个像素。这样的话,输出图像上的第二个像素就收到了输入图像上的第一个和第二个像素的双重信息,而整个卷积过程中,输出图像中间部分的像素都从输入图像中接收到了同样多的信息,这样就导致了卷积核重叠的区域。而在案例(b)中,当过滤器的大小增加到 3 时,这个接收到最多信息的中间部分缩小了。但是这样的话问题不大,因为重叠部分依旧是均匀的。在输出图像中间部分的像素从输入图像中接收到同样多的信息。
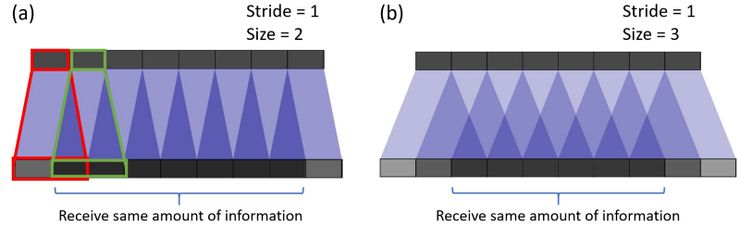
图片源自论文「Deconvolution and Checkerboard Artifacts」,https://distill.pub/2016/deconv-checkerboard/
现在针对下面的案例,我们将卷积步长改为 2。在案例(a)中,过滤器的大小为 2,输出图像上的所有像素从输入图像中接收到同样多的信息,它们都从输入图像中接收到一个像素的信息,这里就不存在转置卷带来的重叠区域。
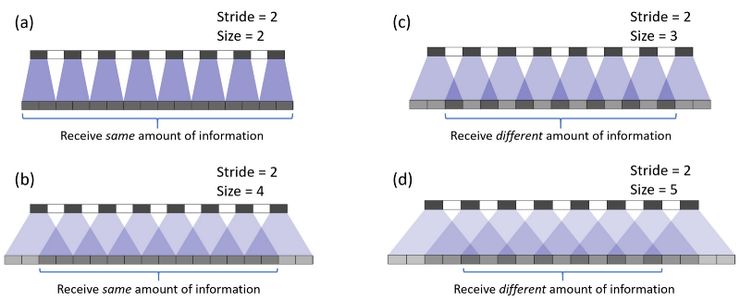
图片源自论文「Deconvolution and Checkerboard Artifacts」,https://distill.pub/2016/deconv-checkerboard/
而在案例(b)中,当我们将过滤器大小增至 4 时,均匀的重叠区域缩小了,但是研究者依旧可以将输出图像的中间部分用作有效的输出,其中每个像素从输入图像中接收到的信息是同样多的。
然而,在案例(c)和(d)中,当过滤器大小变成 3 或 5 时,情况就变得非常有趣了。在这两个案例中,输出图像上的每个像素与其毗邻的像素所接收到的信息量都不相同。研究者在输出图像上无法找到一个连续并均匀的重叠区域。
当过滤器大小无法被卷积步长整除时,转置卷积就会出现「不均匀重叠」。这种「不均匀重叠」会造成图像中某个部位的颜色比其他部位更深,因而会带来「棋盘效应」。实际上,不均匀重叠区域会在二维上更加极端。因为二维上的两个模式会相乘,因而最终的不均匀性是原来的平方。
在应用转置卷积时,可以做两件事情来减轻这种效应。第一,确认使用的过滤器的大小是能够被卷积步长整除的,从而来避免重叠问题。第二,可以采用卷积步长为 1 的转置卷积,来减轻「棋盘效应」。然而,正如在最近许多模型中所看到的,这种效益依旧可能会显露出来。
这篇论文进一步提出了一个更好的上采样方法:首先调整图像大小(使用最近邻域内插法(Nearest Neighbor interpolation)和双向性内插法(bilinear interpolation)),然后制作一个卷积层。通过这样做,论文作者成功避免了这一「棋盘效应」。大家或许也想要在自己的应用中尝试一下这个方法吧。
7. 空洞卷积(扩张卷积)
下面这两篇论文对空洞卷积(Dilated Convolution)进行了介绍:
《使用深度卷积网络和全连接 CRF 做语义图像分割》(Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs,https://arxiv.org/abs/1412.7062)
《通过空洞卷积做多规模的上下文聚合》(Multi-scale context aggregation by dilated convolutions,https://arxiv.org/abs/1511.07122)
空洞卷积也称作扩张卷积(Atrous Convolution)。
这是一个标准的离散卷积:
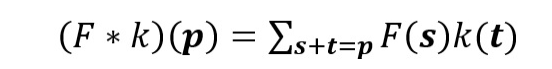
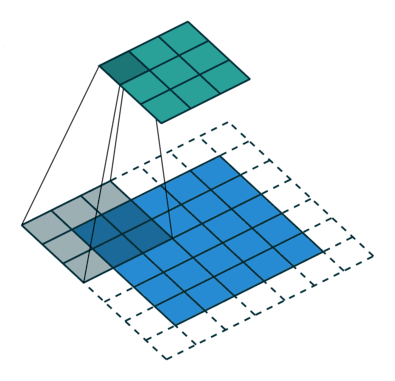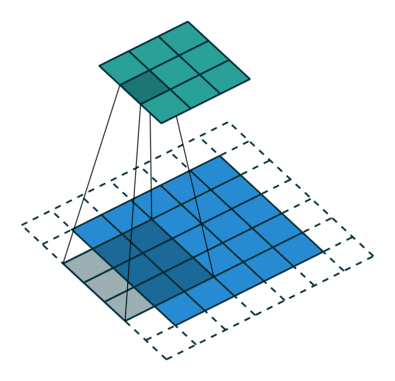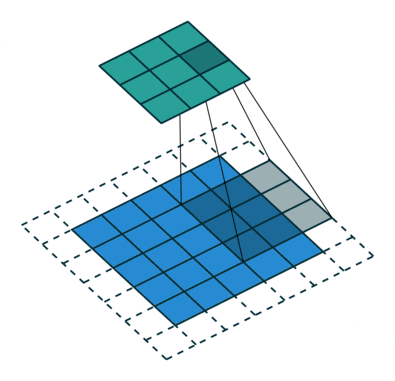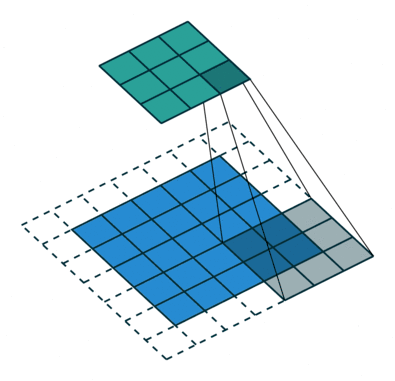
标准卷积
空洞卷积如下:
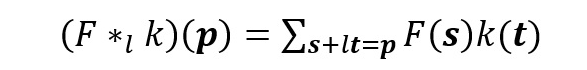
当 l=1 时,空洞卷积就变成了一个标准卷积。
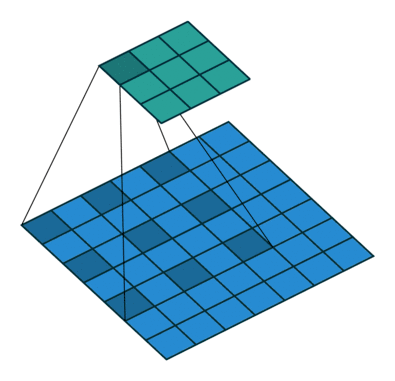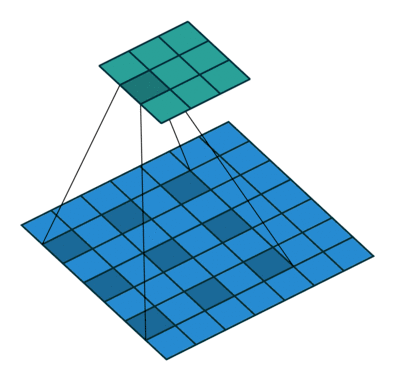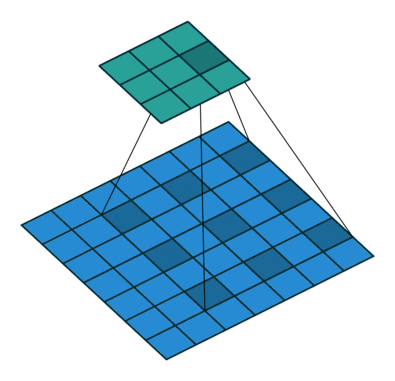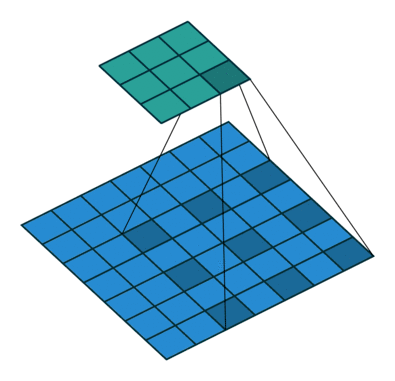
直观上,空洞卷积通过在卷积核部分之间插入空间让卷积核「膨胀」。这个增加的参数 l(空洞率)表明了我们想要将卷积核放宽到多大。虽然各实现是不同的,但是在卷积核部分通常插入 l-1 空间。下图显示了当 l-1,2,4 时的卷积核大小。
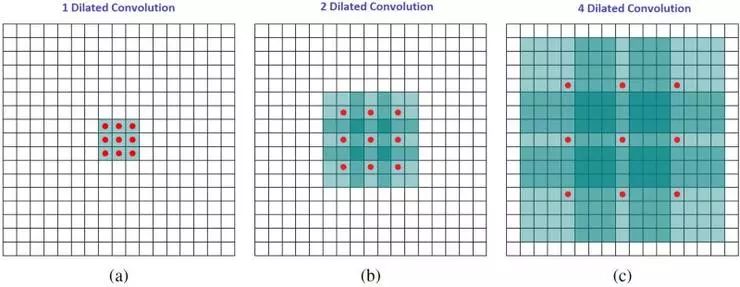
空洞卷积的感受野。本质上是在不增加额外的计算成本的情况下观察感受野。
在图像中,3 x 3 的红点表明经过卷积后的输出图像的像素是 3 x 3。虽然三次空洞卷积都得出了相同维度的输出图像,但是模型观察到的感受野(receptive field)是大不相同的。l=1 时,感受野为 3 x 3;l=2 时,感受野是 7 x 7;l=3 时,感受野增至 15x15。有趣的是,伴随这些操作的参数数量本质上是相同的,不需要增加参数运算成本就能「观察」大的感受野。正因为此,空洞卷积常被用以低成本地增加输出单元上的感受野,同时还不需要增加卷积核大小,当多个空洞卷积一个接一个堆叠在一起时,这种方式是非常有效的。
《通过空洞卷积做多规模的上下文聚合》的论文作者在多层空洞卷积以外创建了一个网络,其中的空洞率 l 每层都以指数级的方式增长。结果,当参数数量每层仅有直线式的增长时,有效的感受野实现了指数型的增长。
该论文中,空洞卷积被用于系统地聚合多规模的上下文信息,而不需要损失分辨率。该论文表明,其提出的模块提高了当时(2016 年)最先进的语义分割系统的准确率。大家可以阅读这篇论文获得更多信息。
8. 可分离卷积
可分离卷积用于一些神经网络架构,例如 MobileNet(该架构论文地址:https://arxiv.org/abs/1704.04861)。可分离卷积分为空间可分离卷积(spatially separable convolution)和深度可分离卷积(depthwise separable convolution)。
8.1 空间可分离卷积
空间可分离卷积在图像的 2D 空间维度上执行,例如高和宽两个维度。从概念上来看,顾名思义,空间可分离卷积将卷积分解为两项单独的操作。下面所展示的案例中,一个卷积核为 3x3 的 Sobel 卷积核拆分成了一个 3x1 卷积核和一个 1x3 卷积核。
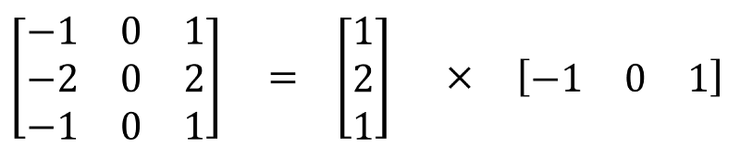
一个卷积核为 3x3 的 Sobel 卷积核拆分成了一个 3x1 卷积核和一个 1x3 卷积核
在卷积中,3x3 卷积核可以直接对图像进行卷积操作。在空间可分离卷积中,首先由 3x1 卷积核对图像进行卷积,之后再应用 1x3 卷积核。在执行相同的操作中,这就要求 6 个而不是 9 个参数了。
此外,比起卷积,空间可分离卷积要执行的矩阵乘法运算也更少。举一个具体的案例,在卷积核为 3x3 的 5x5 图像上做卷积,要求横向扫描 3 个位置(以及纵向扫描 3 个位置)上的卷积核,共有 9 个位置,如下图标出的 9 个点所示。在每个位置都进行 9 次元素级别的乘法运算,共执行 9 x 9 = 81 次运算。
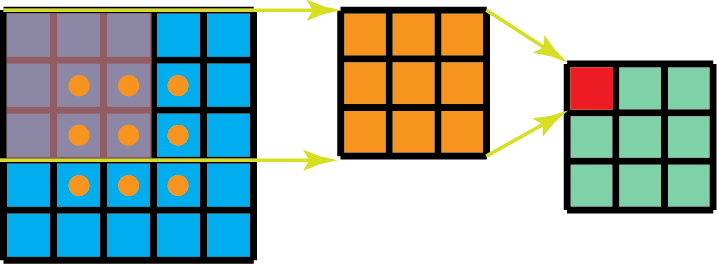
针对空间可分离卷积,另一方面,我们先在 5x5 图像上应用一个 3x1 的过滤器,这样的话就能横向扫描 5 个位置的卷积核以及纵向扫描 3 个位置的卷积核,总共 5 x 3=15 个位置,如下图所标的点所示。这样的话就共要进行 15 x 3 = 45 次乘法运算。现在得到的是一个 3 x 5 的矩阵,这个矩阵经过 1 x 3 卷积核的卷积操作——从横向上的 3 个位置以及纵向上的 5 个位置来扫描该矩阵。对于这 9 个位置中的每一个,都进行了 3 次元素级别的乘法运算,这个步骤总共要求 9 x 3=27 次乘法运算。因此,总体上,该空间可分离卷积共进行了 45 + 27 = 72 次乘法运算,也比标准的卷积所要进行的乘法运算次数要少。
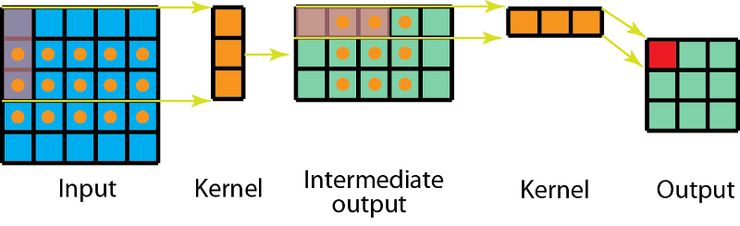
有 1 个通道的空间可分离卷积
让我们稍微概括一下上面的案例。假设我们现在在 m x m 卷积核、卷积步长=1 、填充=0 的 N x N 图像上做卷积。传统的卷积需要进行 (N-2) x (N-2) x m x m 次乘法运算,而空间可分离卷积只需要进行 N x (N-2) x m + (N-2) x (N-2) x m = (2N-2) x (N-2) x m 次乘法运算。空间可分离卷积与标准的卷积的计算成本之比为:
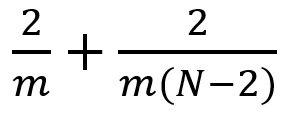
对于图像大小 N 大于过滤器大小(N >> m),这个比率就变成了 2 / m,这就意味着在这种渐进情况(N >> m)下,对于一个 3x3 的过滤器,空间可分离卷积与标准的卷积之间的计算成本比率为 2/3;对于一个 5x5 的过滤器,比率为 2/5;对于一个 7x7 的过滤器,比如为 2/7,以此类推。
虽然空间可分离卷积节省了计算成本,但是它很少应用于深度学习中。一个主要的原因是,并不是所有的卷积核都能被拆分为 2 个更小的卷积核。如果我们用这种空间可分离卷积来取代所有传统的卷积,就会束缚我们去搜寻训练期间所有可能存在的卷积核,因为这个训练结果可能是还只是次优的。
8.2 深度可分离卷积
现在,让我们移步到深度可分离卷积,它在深度学习中的应用要更普遍得多(例如在 MobileNet 和 Xception 中)。深度可分离卷积由两步组成:深度卷积以及 1x1 卷积。
在介绍这些步骤前,值得回顾一下前面部分所提到的 2D 卷积核 1x1 卷积。让我们先快速过一下标准的 2D 卷积。举一个具体的案例,假设输入层的大小为 7 x 7 x 3(高 x 宽 x 通道),过滤器大小为 3 x 3 x 3,经过一个过滤器的 2D 卷积后,输出层的大小为 5 x 5 x 1(仅有 1 个通道)。
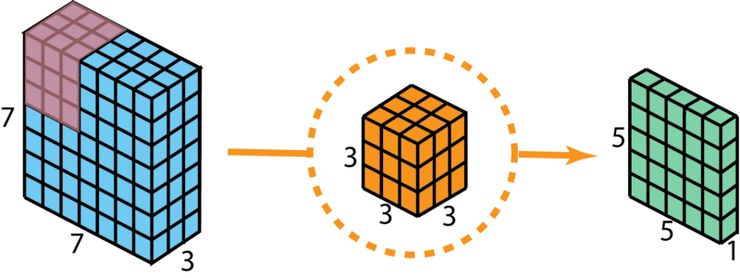
使用 1 个过滤器做标准的 2D 卷积来创建一个 1 层的输出
一般来说,两个神经网络层间应用了多个过滤器,现在假设过滤器个数为 128。128 次 2D 卷积得到了 128 个 5 x 5 x 1 的输出映射。然后将这些映射堆叠为一个大小为 5 x 5 x 128 的单个层。空间维度如高和宽缩小了,而深度则扩大了。
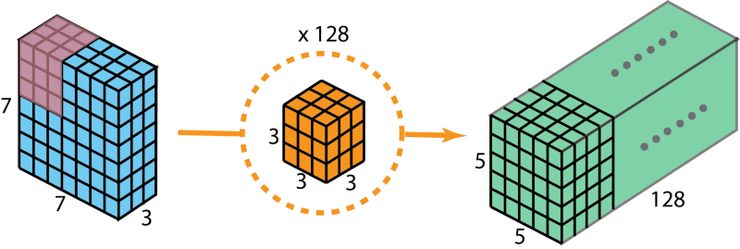
使用 128 个过滤器做标准的 2D 卷积来创建一个 128 层的输出
接下来看看使用深度可分离卷积如何实现同样的转换。
首先,我们在输入层上应用深度卷积。我们在 2D 卷积中分别使用 3 个卷积核(每个过滤器的大小为 3 x 3 x 1),而不使用大小为 3 x 3 x 3 的单个过滤器。每个卷积核仅对输入层的 1 个通道做卷积,这样的卷积每次都得出大小为 5 x 5 x 1 的映射,之后再将这些映射堆叠在一起创建一个 5 x 5 x 3 的图像,最终得出一个大小为 5 x 5 x 3 的输出图像。这样的话,图像的空间维度缩小了吗,但是深度保持与原来的一样。
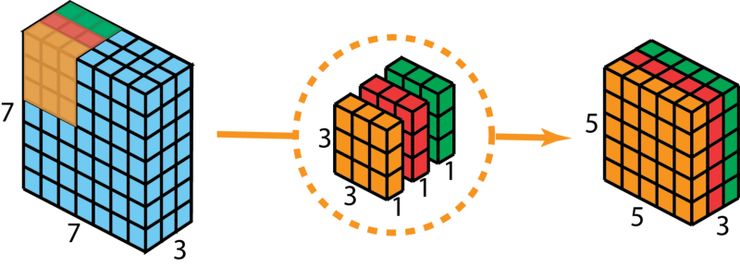
深度可分离卷积—第一步:在 2D 卷积中分别使用 3 个卷积核(每个过滤器的大小为 3 x 3 x 1),而不使用大小为 3 x 3 x 3 的单个过滤器。每个卷积核仅对输入层的 1 个通道做卷积,这样的卷积每次都得出大小为 5 x 5 x 1 的映射,之后再将这些映射堆叠在一起创建一个 5 x 5 x 3 的图像,最终得出一个大小为 5 x 5 x 3 的输出图像。
深度可分离卷积的第二步是扩大深度,我们用大小为 1x1x3 的卷积核做 1x1 卷积。每个 1x1x3 卷积核对 5 x 5 x 3 输入图像做卷积后都得出一个大小为 5 x 5 x1 的映射。
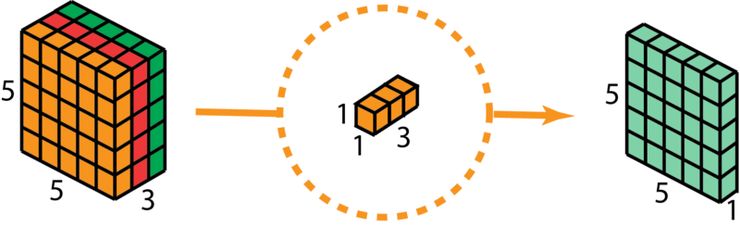
这样的话,做 128 次 1x1 卷积后,就可以得出一个大小为 5 x 5 x 128 的层。
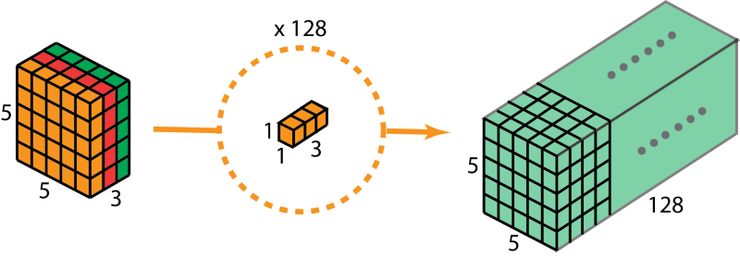
深度可分离卷积完成这两步后,同样可以将一个 7 x 7 x 3 的输入层转换为 5 x 5 x 128 的输出层。
深度可分离卷积的完整过程如下图所示:
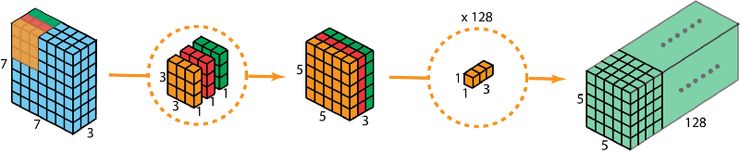
深度可分离卷积的完整过程
因此,做深度可分离卷积的优势是什么?高效!相比于 2D 卷积,深度可分离卷积的执行次数要少得多。
让我们回忆一下 2D 卷积案例中的计算成本:128 个 3x3x3 的卷积核移动 5x5 次,总共需要进行的乘法运算总数为 128 x 3 x 3 x 3 x 5 x 5 = 86,400 次。
那可分离卷积呢?在深度卷积这一步,有 3 个 3x3x3 的卷积核移动 5x5 次,总共需要进行的乘法运算次数为 3x3x3x1x5x5 = 675 次;在第二步的 1x1 卷积中,有 128 个 3x3x3 的卷积核移动 5x5 次,总共需要进行的乘法运算次数为 128 x 1 x 1 x 3 x 5 x 5 = 9,600 次。因此,深度可分离卷积共需要进行的乘法运算总数为 675 + 9600 = 10,275 次,花费的计算成本仅为 2D 卷积的 12%。
因此对于任意大小的图像来说,应用深度可分离卷积能节省多少次计算呢?我们稍微概括一下上面的案例。假设输入图像大小为 H x W x D,2D 卷积的卷积步长为 1,填充为 0,卷积核大小为 h x h x D(两个 h 相等)、个数为 Nc。2D 卷积后,大小为 H x W x D 的输入层最终转换为大小为(H-h+1)x(W-h+1)x Nc 的输出层,总共需要进行的乘法运算次数为:Nc x h x h x D x (H-h+1) x (W-h+1)。
针对同样的转换,深度可分离卷积总共需要进行的乘法运算次数为:D x h x h x 1 x (H-h+1) x (W-h+1) + Nc x 1 x 1 x D x (H-h+1) x (W-h+1) = (h x h + Nc) x D x (H-h+1) x (W-h+1)。
深度可分离卷积与 2D 卷积之间的乘法运算次数之比为:
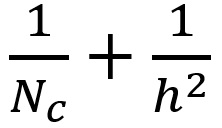
对于大部分现代框架而言,输出层往往都有许多个通道,例如几百甚至几千个通道。对于 Nc >> h 的层,上面的表达式会缩短为 1/h/h,这就意味着对于这个渐进的表达式而言,如果使用的过滤器大小为 3 x 3,2D 卷积需要进行的乘法运算次数比深度可分离卷积多出 9 次;使用大小为 5 x5 的过滤器,则要多出 25 次。
使用深度可分离卷积有什么缺点吗?当然有。深度可分离卷积会减少卷积中的参数个数,这样的话,对于一个小的模型,如果采用深度可分离模型来踢打 2D 模型,该模型的能力就会被大为削弱。结果,该模型也会变成次优的模型。然而,如果恰当使用,深度可分离卷积可以提高效率而不会明显损害模型的性能。
9. 扁平化卷积
《将扁平化卷积神经网络应用于前馈加速》(Flattened convolutional neural networks for feedforward acceleration,https://arxiv.org/abs/1412.5474)这篇论文对扁平化卷积(Flattened convolutions)进行了介绍。直观上,这种卷积的思路就是应用过滤器分离,即将标准的分离器拆分为 3 个 1D 分离器,而不是直接应用一个标准的卷积过滤器来将输入层映射为输出层。这个思路类似于前部分所提到的空间可分离卷积,其中的一个空间过滤器近似于两个 rank-1 过滤器。
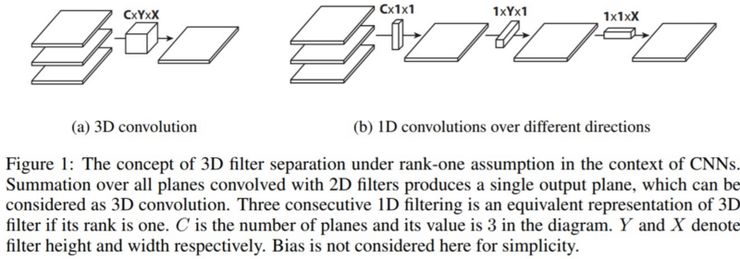
图片源自:https://arxiv.org/abs/1412.5474
需要注意的一点事,如果标准卷积的过滤器是 rank-1 过滤器,这样的过滤器可以被拆分为 3 个 1D 过滤器的交叉乘积,但是这是一个前提条件并且标准过滤器的固有 rank 往往比现实应用中的更高。正如论文中所指出的:「随着分类问题的难度增加,解决该问题还需要更多的关键部分... 深度网络中学习过滤器具有分布的特征值,并且将分离直接用于过滤器会导致明显的信息丢失。」
为了减轻这类问题,论文限制了感受野的关系从而让模型可以根据训练学习 1D 分离的过滤器。这篇论文声称,通过使用由连续的 1D 过滤器组成的扁平化网络在 3D 空间的所有方向上训练模型,能够提供的性能与标准卷积网络相当,不过由于学习参数的显著减少,其计算成本要更低得多。
10. 分组卷积
2012 年的一篇 AlexNet 论文(ImageNet Classification with Deep Convolutional Neural Networks,https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf)对分组卷积(Grouped convolution)进行了介绍。采用这种卷积的主要原因是为了让网络用有限的记忆(1.5GB 记忆/GPU)在两个 GPU 上进行训练。下图的 AlexNet 现实了大部分层的两条分离的卷积路线,正在进行两个 GPU 的模型并行化计算。
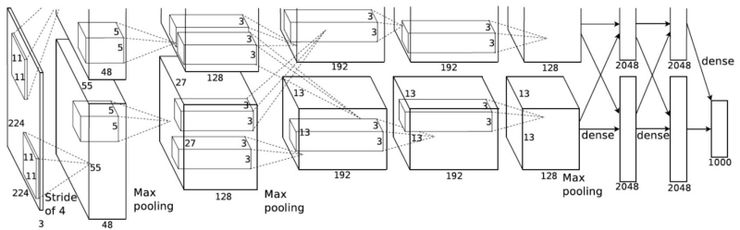
图片源自:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
这里我描述的是分组卷积是如何实现的。首先,传统的 2D 卷积步骤如下图所示。在这个案例中,通过应用 128 个过滤器(每个过滤器的大小为 3 x 3 x 3),大小为 7 x 7 x 3 的输入层被转换为大小为 5 x 5 x 128 的输出层。针对通用情况,可概括为:通过应用 Dout 个卷积核(每个卷积核的大小为 h x w x Din),可将大小为 Hin x Win x Din 的输入层转换为大小为 Hout x Wout x Dout 的输出层。
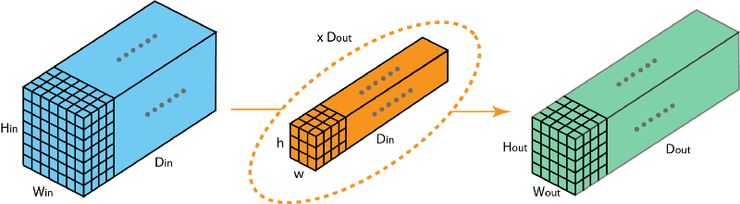
标准 2D 卷积
在分组卷积中,过滤器被拆分为不同的组,每一个组都负责具有一定深度的传统 2D 卷积的工作。下图的案例表示得更清晰一些。
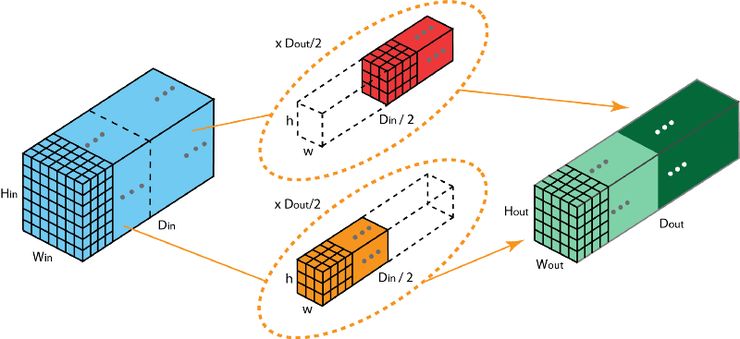
拆分为 2 个过滤组的分组卷积
上图表示的是被拆分为 2 个过滤器组的分组卷积。在每个过滤器组中,其深度仅为名义上的 2D 卷积的一半(Din / 2),而每个过滤器组都包含 Dout /2 个过滤器。第一个过滤器组(红色)对输入层的前半部分做卷积([:, :, 0:Din/2]),第二个过滤器组(蓝色)对输入层的后半部分做卷积([:, :, Din/2:Din])。最终,每个过滤器组都输出了 Dout/2 个通道。整体上,两个组输出的通道数为 2 x Dout/2 = Dout。之后,我们再将这些通道堆叠到输出层中,输出层就有了 Dout 个通道。
10.1 分组卷积 VS 深度卷积
你可能已经观察到了分组卷积和深度可分离卷积中用到的深度卷积之间的某些联系和区别。如果过滤器组的数量与输入层的通道数相同,每个过滤器的深度就是 Din / Din = 1,其与深度卷积中的过滤器深度相同。
从另一个角度来说,每个过滤器组现在包含 Dout / Din 个过滤器。总体而言,其输出层的深度就是 Dout,这就与深度卷积的输出层深度不同,深度卷积不改变层的深度,但随后深度可分离卷积中的 1 x 1 卷积会加大层的深度。
执行分组卷积有如下几个优势:
第一个优势是训练的高效性。由于卷积被拆分到几条路线中,每条路线都由不同的 GPU 分别进行处理。这一过程就允许模型以平行的方式在多个 GPU 上进行训练。比起在一个 GPU 上一个一个地训练模型,这种在多个 GPU 上的模型并行化训练方式每一步都可以给网络喂养更多的图像。模型并行化被认为比数据并行化更佳,后者将数据集进行拆分,然后对每一批数据进行训练。不过,当每批数据的大小过小时,我们执行的工作基本上是随机的,而不是批量梯度下降。这就会造成训练速度变慢或聚合效果变差的结果。
对于训练非常深度的神经网络,分组卷积变得很重要,如下图中 ResNeXt 所示。
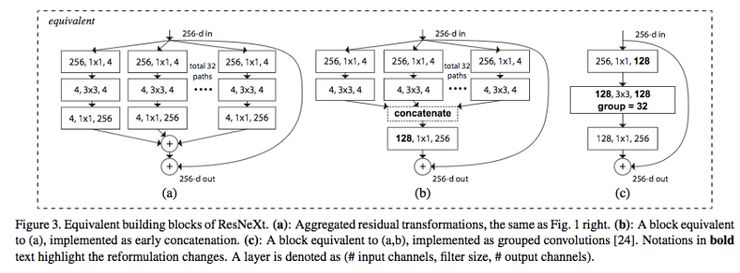
图片源自:https://arxiv.org/abs/1611.05431
第二个优势是模型更加高效,例如,当过滤器组数增加时,模型参数就会减少。在前一个案例中,在标准的 2D 卷积中,过滤器有 h x w x Din x Dout 个参数,而在拆分为 2 个过滤器组的分组卷积中,过滤器仅有 (h x w x Din/2 x Dout/2) x 2 个参数:参数数量减少了一半。
第三个优势是给人带来了些惊喜的。分组卷积能提供比标准 2D 卷积更好的模型。另一篇很棒的博客「A Tutorial on Filter Groups (Grouped Convolution)」也阐述了这一点。这里仅提取了文章的部分内容,大家可前往 https://blog.yani.io/filter-group-tutorial/ 阅读全文。
其原因与稀疏的过滤器有关。下面的图像就是相邻层的过滤器之间的相互关系,这个关系是稀疏的。

在 CIFAR10 训练的 Network-in-Network 模型中相邻层的过滤器之间的相关性矩阵。高相关的过滤器对更亮,而低相关过滤器对更暗。图片源自:https://blog.yani.io/filter-group-tutorial/
那面向分组卷积的相关性映射是怎么样的呢?

当采用 1、2、4、8 和 16 个过滤器组训练时,在 CIFAR10 训练的 Network-in-Network 模型中相邻层的过滤器之间的相关性。图片源自:https://blog.yani.io/filter-group-tutorial/
上图表示的就是模型采用 1、2、4、8 和 16 个过滤器组训练时,相邻层的过滤器的相互关系。这篇文章提出了一个推论:「过滤器组的作用就是学习通道维度上的块对角结构的稀疏性... 在对过滤器进行了分组的网络中,高相关性的过滤器以更结构化的方式学习。结果,不要求学习的过滤器关系也不再需要用参数进行表示,这就显著减少了网络中的参数数量,并且在减少参数的过程中不容易过度拟合,因此这种类似正则化的效果可以让优化器学习更准确、更有效的深度网络。」

过滤器分离:正如论文作者所指出的,过滤器组似乎将学习的过滤器拆分成了两个不同的组:黑白过滤器和彩色过滤器。图片源自:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
此外,每个过滤器组都学习数据独一无二的表示。正如 AlexaNet 这篇论文的作者所提到的,过滤器组似乎将学习的过滤器拆分成了两个不同的组:黑白滤镜和彩色滤镜。
11. 混洗分组卷积
旷视研究院的 ShuffleNet 论文(ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices,https://arxiv.org/abs/1707.01083)对混洗分组卷积(Shuffled grouped convolution)进行了介绍。ShuffleNet 是一种计算高效的卷积架构,专为计算能力十分有限的移动设备(如 10–150 MFLOPs)设计。
混洗分组卷积背后的思路与分组卷积(应用于 MobileNet 、ResNeXt 等网络)以及深度可分离卷积(应用于 Xception)背后的思路相关。
总的来说,混洗分组卷积包括分组卷积和通道混洗(channel shuffling)。
在分组卷积部分,我们了解到了过滤器被拆分为不同的组,每个组都负责拥有一定深度的传统 2D 卷积的工作,显著减少了整个操作步骤。在下图这个案例中,假设过滤器分成了 3 组。第一个过滤器组对输入层的红色部分做卷积;第二个和第三个过滤器组分别对输入层的绿色和蓝色部分做卷积。每个过滤器组中的卷积核深度仅为输入层整个通道的 1/3。在这个案例中,进行第一个分组卷积 GConv1 后,输入层被映射到中间的特征映射上,之后特征映射又通过第一个分组卷积 GConv2 被映射到输出层上。
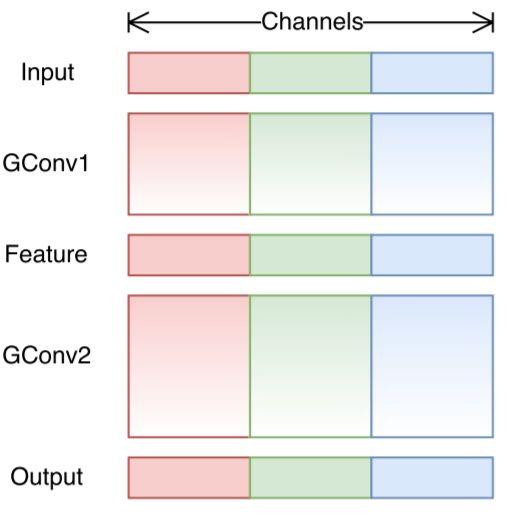
分组卷积虽然计算高效,但它也存在问题,即每个过滤器分组仅对从前面层的固定部分向后传递的信息进行处理。在上面这个图像的案例中,第一个过滤器组(红色)仅处理从输入通道的前 1/3 部分向后传递的信息;蓝色过滤器组仅处理从输入通道的后 1/3 部分向后传递的信息。这样的话,每个过滤器组就仅限于学习一些特定的特征,这种属性就阻碍了训练期间信息在通道组之间流动,并且还削弱了特征表示。为了克服这一问题,我们可以应用通道混洗。
通道混洗的思路就是混合来自不同过滤器组的信息。下图中,显示了应用有 3 个过滤器组的第一个分组卷积 GConv1 后所得到的特征映射。在将这些特征映射喂养到第二个分组卷积之前,先将每个组中的通道拆分为几个小组,然后再混合这些小组。
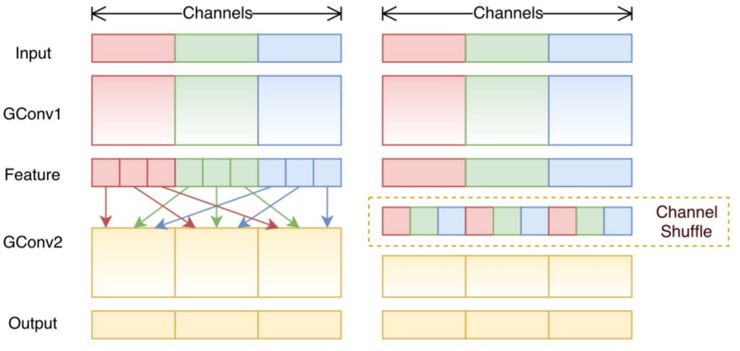
通道混洗
经过这种混洗,我们再接着如常执行第二个分组卷积 GConv2。但是现在,由于经过混洗的层中的信息已经被混合了,我们本质上是将特征映射层的不同小组喂养给了 GConv2 中的每个组。结果,不仅信息可以在通道组间进行流动,特征表示也得到增强。
12. 逐点分组卷积
ShuffleNet 论文(ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices,https://arxiv.org/abs/1707.01083)同样也对逐点分组卷积(Pointwise grouped convolution)进行了介绍。一般针对 MobileNet 或 ResNeXt 中的分组卷积,分组在 3x3 的空间卷积而不是 1x1 卷积上执行。
ShuffleNet 这篇论文认为 1x1 卷积的计算成本也很高,提议也对 1x1 卷积进行分组。逐点分组卷积,顾名思义,就是针对 1x1 卷积进行分组操作,这项操作与分组卷积的相同,仅有一项更改——就是在 1x1 过滤器而非 NxN 过滤器 (N>1) 执行。
在该论文中,作者使用了我们都有所了解的 3 种卷积: (1) 混洗分组卷积; (2) 逐点分组卷积; 以及 (3) 深度可分离卷积。这种架构设计能明显地减少计算量同时还能保持准确性。在实际的移动设备上,ShuffleNet 的分类错误与 AlexNet 的相当。然而,从使用 AlexNe 的 720 MFLOPs 到使用 ShuffleNet 的 40–140 MFLOPs,计算成本明显下降。在面向移动设备的卷积神经网络领域,ShuffleNe 以相对较小的计算成本以及良好的模型性能广受欢迎。
参考博文&文章
「An Introduction to different Types of Convolutions in Deep Learning」:https://towardsdatascience.com/types-of-convolutions-in-deep-learning-717013397f4d
「Review: DilatedNet — Dilated Convolution (Semantic Segmentation)」:https://towardsdatascience.com/review-dilated-convolution-semantic-segmentation-9d5a5bd768f5
「ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices」:https://medium.com/syncedreview/shufflenet-an-extremely-efficient-convolutional-neural-network-for-mobile-devices-72c6f5b01651
「Separable convolutions「A Basic Introduction to Separable Convolutions」:https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
Inception network「A Simple Guide to the Versions of the Inception Network」:https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202
「A Tutorial on Filter Groups (Grouped Convolution)」:https://blog.yani.io/filter-group-tutorial/
「Convolution arithmetic animation」:https://github.com/vdumoulin/conv_arithmetic
「Up-sampling with Transposed Convolution」:https://towardsdatascience.com/up-sampling-with-transposed-convolution-9ae4f2df52d0
「Intuitively Understanding Convolutions for Deep Learning」:https://towardsdatascience.com/intuitively-understanding-convolutions-for-deep-learning-1f6f42faee1
论文
Network in Network:https://arxiv.org/abs/1312.4400
Multi-Scale Context Aggregation by Dilated Convolutions:https://arxiv.org/abs/1511.07122
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs:https://arxiv.org/abs/1412.7062
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices:https://arxiv.org/abs/1707.01083
A guide to convolution arithmetic for deep learning :https://arxiv.org/abs/1603.07285
Going deeper with convolutions:https://arxiv.org/abs/1409.4842
Rethinking the Inception Architecture for Computer Vision :https://arxiv.org/pdf/1512.00567v3.pdf
Flattened convolutional neural networks for feedforward acceleration :https://arxiv.org/abs/1412.5474
Xception: Deep Learning with Depthwise Separable Convolutions:https://arxiv.org/abs/1610.02357
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications :https://arxiv.org/abs/1704.04861
Deconvolution and Checkerboard Artifacts:https://distill.pub/2016/deconv-checkerboard/
ResNeXt: Aggregated Residual Transformations for Deep Neural Networks:https://arxiv.org/abs/1611.05431
via:
https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215


