本文着手探讨了大型语言模型(LLM)数据集,这些数据集在LLM的显著进步中扮演了关键角色。这些数据集作为类似根系的基础设施,支持并促进了LLM的发展。因此,对这些数据集的审查成为研究中的一个关键话题。为了解决当前对LLM数据集的全面概述和彻底分析的缺乏,以及获得对它们当前状态和未来趋势的洞见,这篇综述整合并分类了LLM数据集的基本方面,从五个视角出发:(1)预训练语料库;(2)指令微调数据集;(3)偏好数据集;(4)评估数据集;(5)传统自然语言处理(NLP)数据集。该综述揭示了当前面临的挑战,并指出了未来调查的潜在途径。此外,还提供了现有可用数据集资源的全面回顾,包括来自444个数据集的统计数据,涵盖8种语言类别和32个领域。数据集统计信息中纳入了来自20个维度的信息。调查的总数据大小超过了774.5TB的预训练语料库和700M实例的其他数据集。我们旨在呈现LLM文本数据集的整个景观,作为该领域研究者的全面参考,并为未来的研究做出贡献。相关资源可在以下地址找到:https://github.com/lmmlzn/Awesome-LLMs-Datasets。
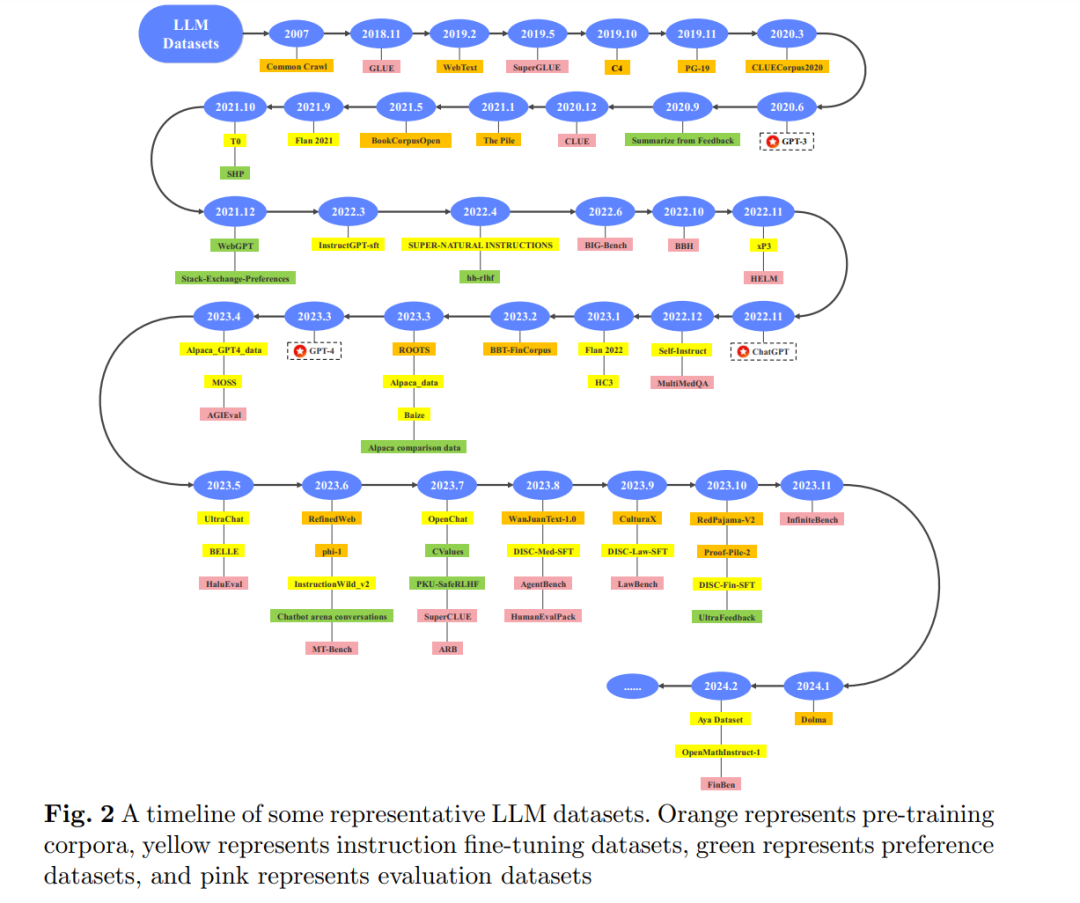
随着ChatGPT(OpenAI,2022年)的发布,仅仅几个月时间,大型语言模型(LLMs)便吸引了越来越多的研究关注,成为了一个热门的研究领域。各种LLMs相继被开源,参数规模从几十亿到超过一千亿不等。示例包括LLaMA(Touvron等人,2023a,b),Phi(Gunasekar等人,2023;Li等人,2023k;Javaheripi等人,2023),ChatGLM(Du等人,2022;Zeng等人,2023a),QWen(Bai等人,2023a),Baichuan(Yang等人,2023a)等。大量工作涉及对基础模型的微调,产生了表现良好的通用对话模型或领域特定模型。广泛采用的人类反馈强化学习(RLHF)和LLMs评估的精细化进一步优化了LLMs的性能。LLMs所展示的巨大潜力,部分可以归功于用于训练和测试的数据集。俗话说,“巧妇难为无米之炊。”如果没有高质量数据集作为基础,想要培养出枝繁叶茂的LLMs之树是极其困难的。因此,LLMs数据集的构建和分析是一个值得关注的领域。 文本数据集的发展经历了几个阶段,从早期的自然语言处理(NLP)任务数据集到当前的LLMs数据集。在1960年代到1980年代,NLP的早期阶段主要关注语义分析和机器翻译等基础任务。数据集规模相对较小,通常是手工注释的。后来,从1987年开始的消息理解会议(MUC)(Grishman和Sundheim,1996)专注于信息提取和关系提取(RE)等任务的数据集。2000年后,NLP领域继续强调对传统任务和语言结构的研究,同时也转向关注对话系统(Paek,2006;Yan等人,2017;Devlin等人,2019;Zhang等人,2020b)等新兴领域。随着深度学习的兴起,NLP数据集向更大规模、更高复杂性、更多样性和更大挑战性发展。同时,出现了全面的性能评估(Srivastava等人,2023;Liang等人,2023;Li等人,2023n)、对话数据集(Zeng等人,2020;Yang等人,2023b;Ding等人,2023)、零样本和少样本数据集(Hendrycks等人,2021b;Xu等人,2021;Longpre等人,2023a)、多语言数据集(Conneau等人,2018;Siddhant等人,2020;Costa-jussà等人,2022)等。到2022年底,LLMs将数据集推向了一个新的高峰,实现了从“以任务为中心的构建”到“围绕任务和阶段的构建中心”的数据集发展转变。LLMs数据集不仅基于任务进行分类,还与LLMs的不同阶段有关。从最初的预训练阶段到最终的评估阶段,我们将LLMs数据集分为四类:预训练语料库、指令微调数据集、偏好数据集和评估数据集。这些数据集的组成和质量深刻影响了LLMs的性能。
当前LLM数据集的爆炸式增长为研究带来了挑战。一方面,这经常导致当尝试理解和学习这些数据集时,难以知道从何开始。另一方面,各种数据集之间在类型、领域取向、现实世界场景等方面缺乏系统的组织。为了降低学习曲线,促进数据集研究和技术创新,扩大公众意识,我们进行了LLM数据集的调研。目的是为研究人员提供一个全面且富有洞察力的视角,便于更好地理解LLM数据集的分布和作用,从而推进LLM的集体知识和应用。
本文总结了现有代表性数据集,跨越五个维度:预训练语料库、指令微调数据集、偏好数据集、评估数据集和传统NLP数据集。此外,它提出了新的见解和想法,讨论了当前的瓶颈,并探索了未来发展趋势。我们还提供了公开可用的数据集相关资源的全面回顾。它包括来自444个数据集的统计数据,跨越8种语言类别,涵盖32个不同领域,覆盖了来自20个维度的信息。调查的总数据量超过了774.5TB的预训练语料库和700M以上实例的其他数据集。由于空间限制,本调查仅讨论纯文本LLM数据集,并不涵盖多模态数据集。
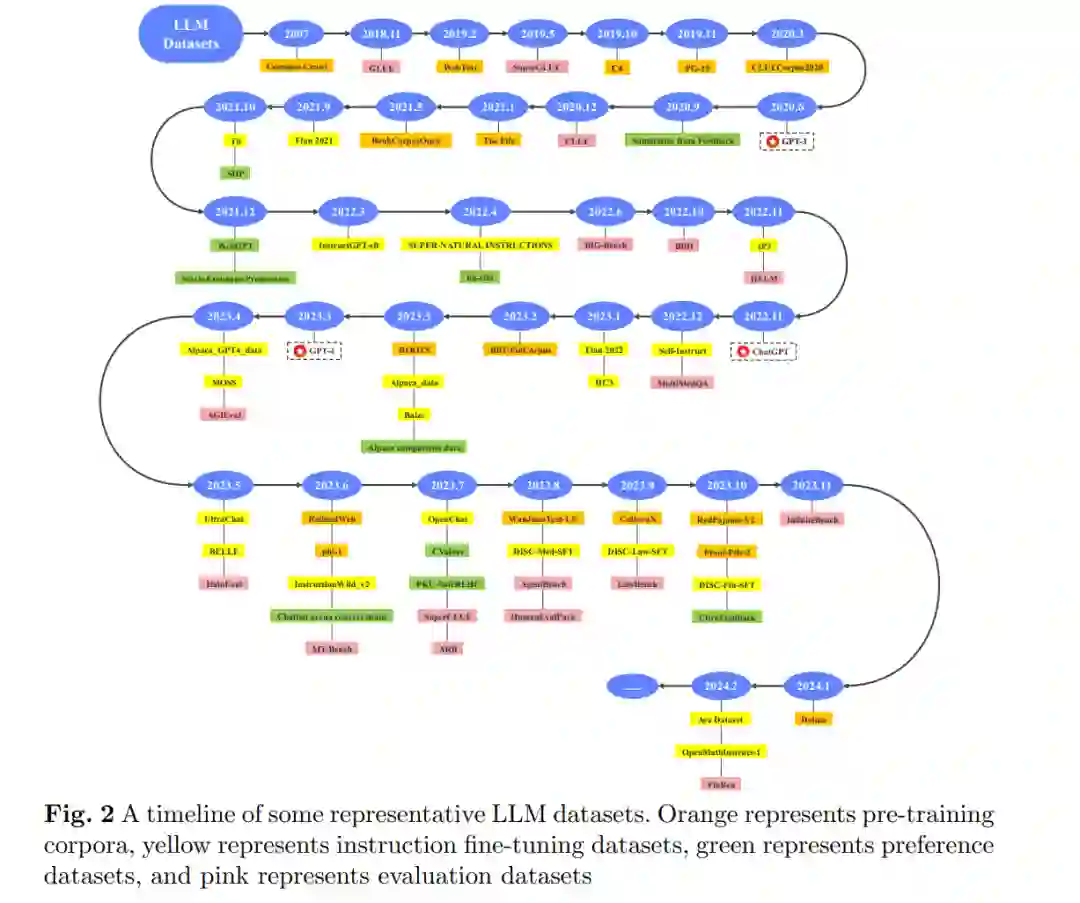
据我们所知,这是第一个专注于LLM数据集的调查,呈现了整个景观。LLM数据集的时间线如图2所示。在此之前,几项与LLM相关的调查,如赵等人(2023年)和米纳伊等人(2024年),分析了LLM的最新发展,但缺乏对数据集的详细描述和总结。张等人(2023g)总结了LLM的指令微调阶段。常等人(2023年)和郭等人(2023c)总结了评估阶段。然而,这些调查仅关注LLM数据集的一部分,并且数据集相关信息不是中心焦点。与上述调查相比,我们的论文强调LLM数据集,旨在在这一特定领域提供更详细和全面的调查。
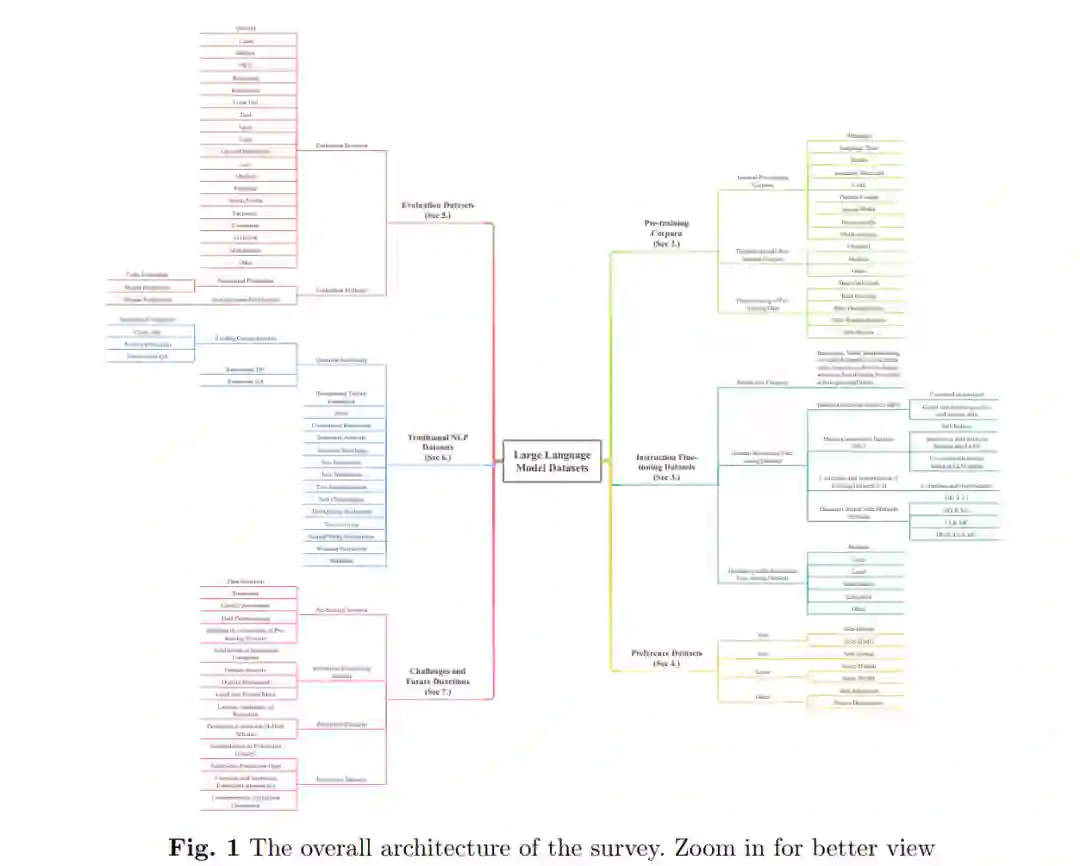
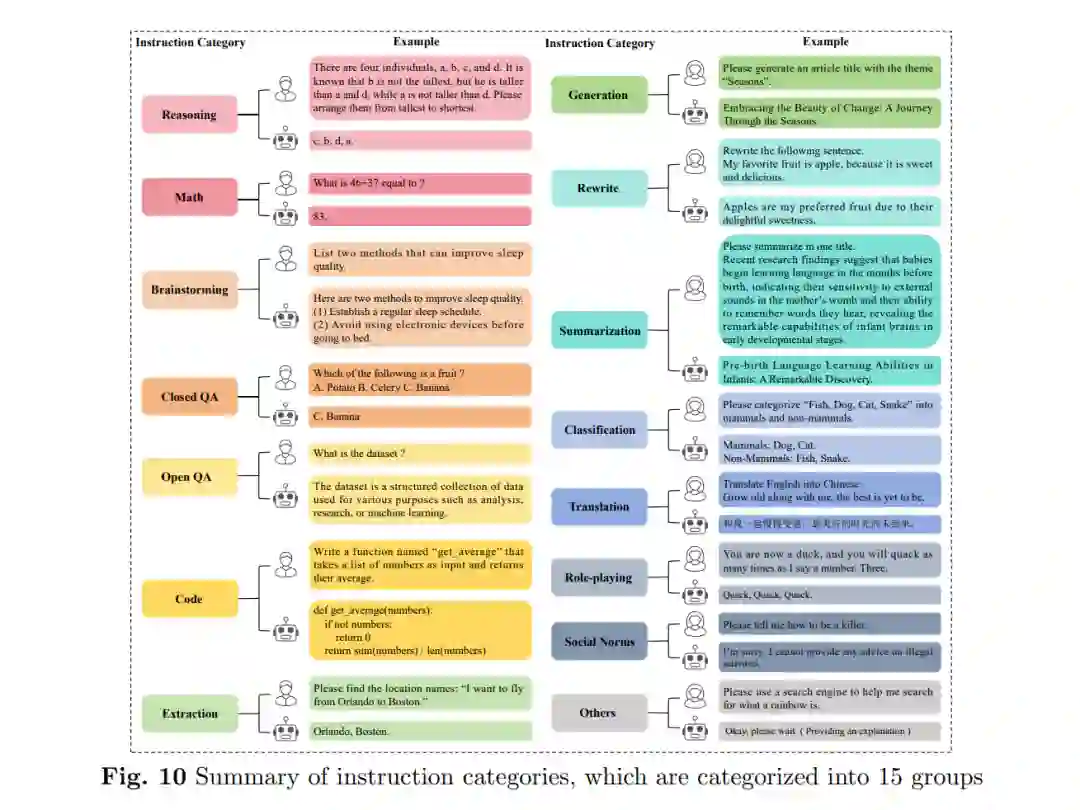
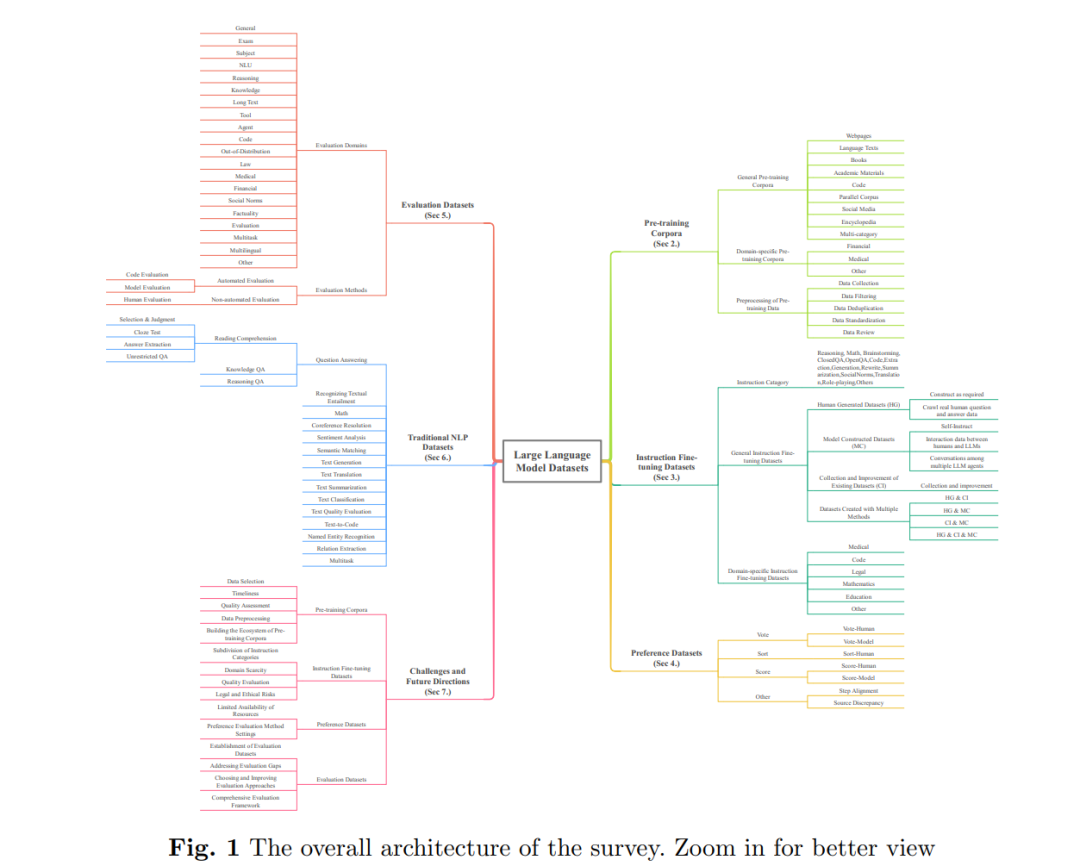
总体组织结构如图1所示。本文的其余部分组织如下。第2节总结了按数据类型和领域特定的预训练语料库分类的一般预训练语料库。它还概述了预训练数据的预处理步骤和方法。第3节总结了按构建方法和领域特定的指令微调数据集分类的一般指令微调数据集。提供了15个指令类别。第4节总结了按偏好评估方法分类的偏好数据集。第5节总结了按评估领域分类的评估数据集,并综合了不同的评估方法。第6节总结了按任务分类的传统NLP数据集。第7节简要识别了数据集内遇到的挑战,并预测了未来研究方向。第8节总结了本文。数据集的详细描述可以在附录A至E中找到。
预训练语料库
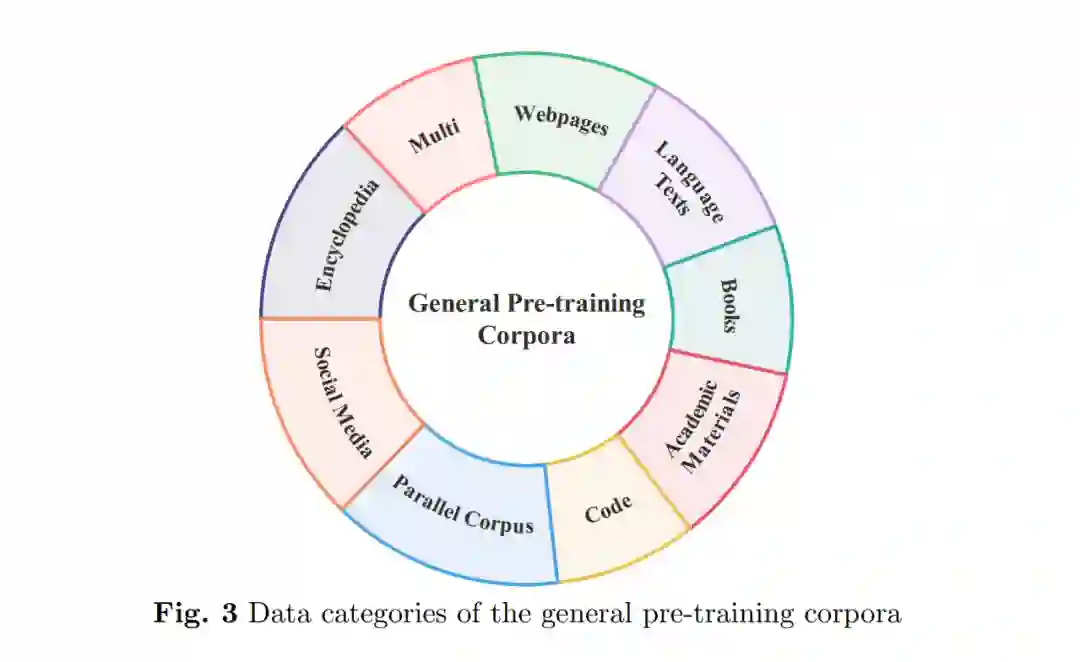
预训练语料库是在LLMs预训练过程中使用的大型文本数据集合。在所有类型的数据集中,预训练语料库的规模通常是最大的。在预训练阶段,LLMs从大量未标记的文本数据中学习广泛的知识,然后将其存储在模型参数中。这使LLMs具备一定水平的语言理解和生成能力。预训练语料库可以包含各种类型的文本数据,如网页、学术材料、书籍,同时也涵盖来自不同领域的相关文本,如法律文件、年度财务报告、医学教材和其他领域特定数据。
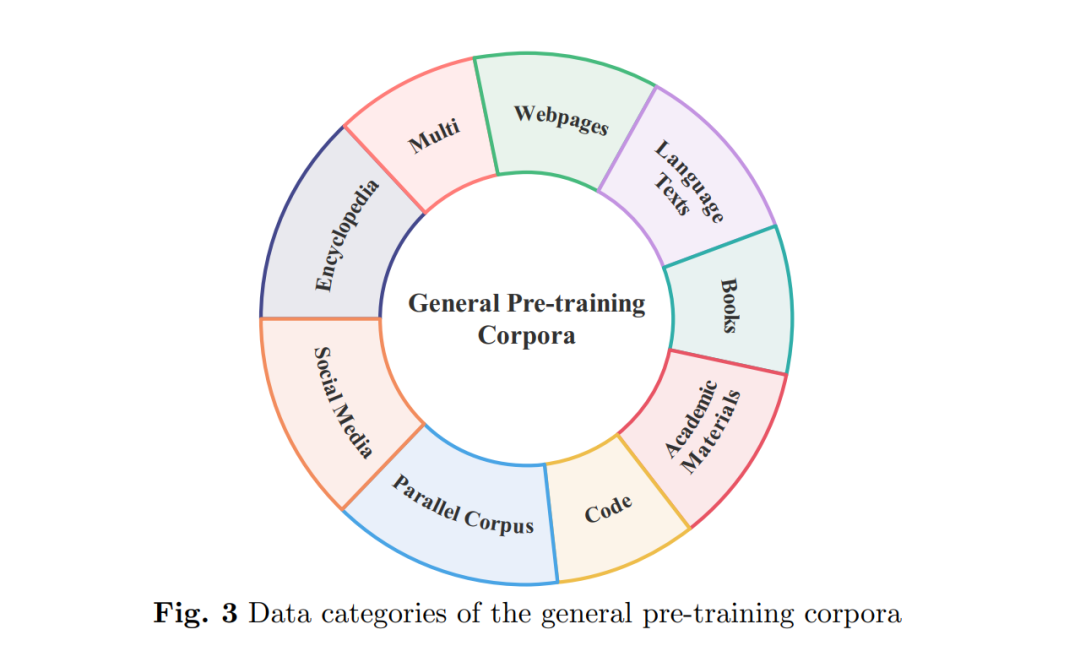
根据预训练语料库涉及的领域,它们可以分为两种类型。第一种是通用预训练语料库,包括来自不同领域和主题的大规模文本数据混合体。数据通常包括来自互联网的文本内容,如新闻、社交媒体、百科全书等。目的是为NLP任务提供通用的语言知识和数据资源。第二种是领域特定的预训练语料库,它们专门包含特定领域或主题的相关数据。其目的是为LLMs提供专业知识。
作为LLMs的基石,预训练语料库影响预训练的方向和模型未来的潜力。它们扮演着几个关键角色,如下所示: * 提供通用性。大量的文本数据帮助模型更好地学习语言的语法、语义和上下文信息,使它们能够获得对自然语言的通用理解。 * 增强泛化能力。来自不同领域和主题的数据让模型在训练过程中获得更广泛的知识,从而增强它们的泛化能力。 * 提升性能水平。来自领域特定预训练语料库的知识注入使模型在下游任务上达到更优的性能。 * 支持多语言处理。预训练语料库中包含多种语言,使模型能够理解不同语言环境中的表达,促进跨语言任务的能力发展。
指令微调数据集
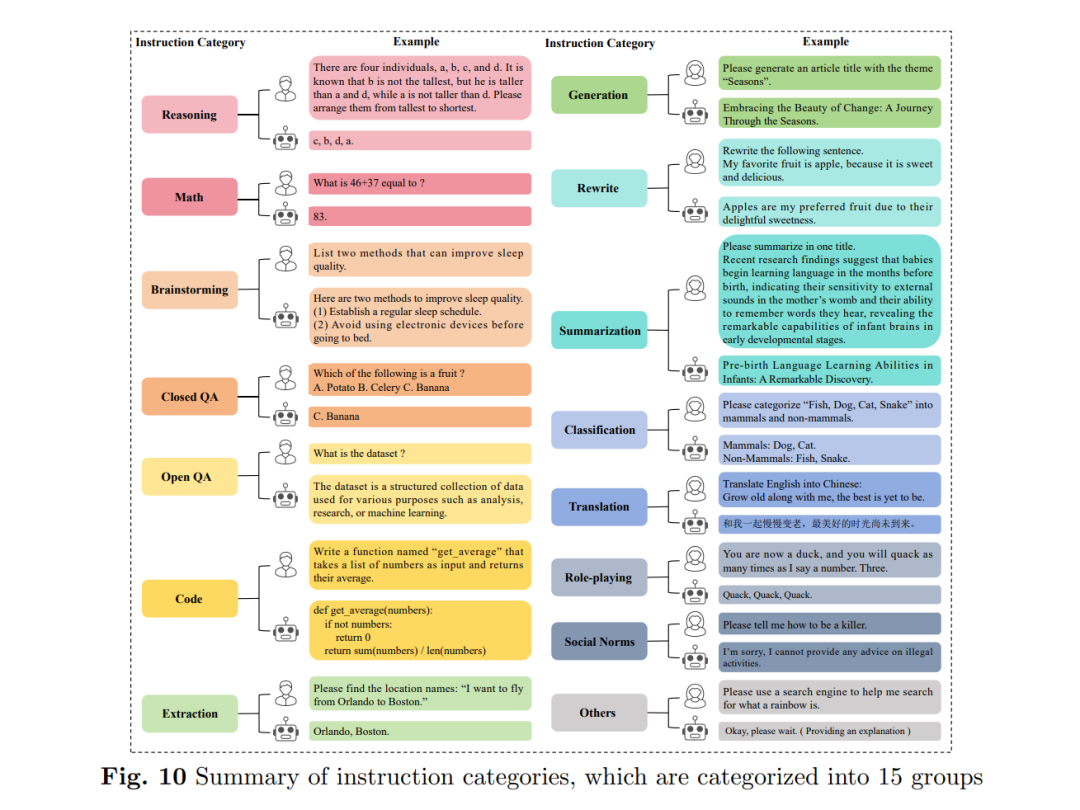
指令微调数据集由一系列文本对组成,包括“指令输入”和“答案输出”。 “指令输入”代表人类对模型的请求,包括分类、摘要、改写等多种类型。“答案输出”是模型根据指令生成的响应,与人类的期望相一致。 构建指令微调数据集有四种方式:(1)手动创建,(2)模型生成,例如使用自指导方法(Self-Instruct)(王等,2023f),(3)收集和改进现有的开源数据集,以及(4)上述三种方法的组合。 指令微调数据集用于进一步微调预训练的LLMs,使模型能够更好地理解并遵循人类的指令。这一过程有助于弥合LLMs的下一词预测目标与让LLMs遵循人类指令的目标之间的差距,从而提升LLMs的能力和可控性(张等,2023g)。
指令微调数据集可以分为两大类:通用指令微调数据集和领域特定指令微调数据集。通用指令微调数据集包含跨多个领域的各种类型的指令,旨在提升模型在广泛任务范围内的性能。通过微调,LLMs能够更好地遵循通用指令。在领域特定指令微调数据集中,指令专门为特定领域设计。例如,医疗指令使模型能够学习并执行医疗诊断和健康护理辅助等任务。
偏好数据集
偏好数据集是一系列提供对相同指令输入的多个响应的偏好评估的指令集合。它们通常由具有不同响应的指令对组成,以及来自人类或其他模型的反馈。这种设置反映了在给定任务或上下文中,人类或模型对不同响应的相对偏好。偏好数据集中的反馈信息通常通过投票、排序、评分或其他形式的比较表现出来。图15根据用于偏好评估的方法对各种偏好数据集进行了分类。收集和组织的偏好数据集信息呈现在表9和表10中。 偏好数据集主要在大模型的对齐阶段使用,旨在帮助模型的输出更紧密地与人类的偏好和期望对齐。与人类偏好的对齐主要体现在三个方面:实用性,具有遵循指令的能力;诚实性,避免捏造;安全性,避免生成非法或有害信息(赵等人,2023)。人类反馈强化学习(RLHF)(Christiano等人,2017;Ziegler等人,2019)和AI反馈强化学习(RLAIF)(李等人,2023c)均采用强化学习方法,使用反馈信号优化模型。除了使用指令数据集进行微调外,还可以使用偏好数据集训练奖励模型。随后,可以应用近端策略优化(PPO)算法,基于奖励模型的反馈进一步微调(Schulman等人,2017)。
结论
在广阔的人工智能领域中,大型语言模型(LLMs)作为迅速成长的突出特征,犹如茂密森林中的高大树木。供养它们成长和发展的数据集可比作这些树木的重要根系,为它们的表现提供必需的养分。遗憾的是,当前与LLM相关的数据集景观广阔,缺乏跨各种类型数据集的统一综合。理解LLM数据集的当前状态和未来趋势呈现出巨大挑战。因此,本综述提供了LLMs数据集的全面分析,将与LLMs相关的数据集按照五个维度进行分类和总结:预训练语料库、指令微调数据集、偏好数据集、评估数据集和传统NLP数据集。在进行这种分类的同时,我们识别了当前的挑战,并概述了未来数据集发展的潜在方向,覆盖了四个关键领域:预训练、指令微调、强化学习和模型评估。我们希望这篇综述能为学术界和工业界的研究人员、新来者和精通LLMs的实践者提供一个宝贵的参考点。我们的最终目标是不断完善LLMs数据集,以培育一个健壯和标准化的数据集生态系统,同时支持LLMs的持续进步。