综述|重邮高新波等最新《少样本目标检测算法》

极市导读
近年来,一些研究探讨了如何在不需要目标域监督的情况下,在额外数据集中使用隐式线索来帮助少样本检测器完善鲁棒任务概念。本综述从当前的经典和最新研究成果,以及未来的研究展望,从多方面进行了综述。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2111.00201
公众号后台回复“重邮”获取本文PDF
摘要
由于现实世界数据的长尾分布和削减数据收集和注释成本的迫切需求,学习适应具有少量标记数据的新类的少样本目标检测是一个迫切和长期的问题。近年来,一些研究探讨了如何在不需要目标域监督的情况下,在额外数据集中使用隐式线索来帮助少样本检测器完善鲁棒任务概念。本综述从当前的经典和最新研究成果,以及未来的研究展望,从多方面进行了综述。特别地,我们首先提出了基于数据的训练数据分类和在训练阶段访问的相应监督形式。按照这种分类法,我们对正式定义、主要挑战、基准数据集、评估指标和学习策略进行了重要的回顾。此外,我们还详细研究了如何相互作用的目标检测方法,以系统地发展这一问题。最后,总结了少样本目标检测的研究现状及未来的研究方向。
引言
给定一组类别,目标检测旨在检测图像或视频中这些类的所有实例。目标检测作为计算机视觉的基础任务,得到了广泛的关注,并被应用到众多的下游应用中,如智能监控[1]、增强现实[2]、自动驾驶[3]等。
此前,传统方法试图利用手工特征来穷尽地搜索[4]-[7]目标,需要大量的先验知识来手工设计适合特殊目标检测的特征(如人脸、行人和交通标志)。由于Alexnet在2012年[8]在ImageNet上的出色表现,深度学习在计算机视觉界开始受到越来越多的关注,它可以自动从训练数据中挖掘隐含任务概念,与传统方法相比,获得巨大的性能收益。特别是近年来,深度学习方法在目标检测[9]-[12]方面取得了重大突破。为了提取鲁棒概念,深度学习模型倾向于获取丰富的标记数据进行训练。然而,对于一个特定的任务,收集大量标记良好的数据并不总是容易的:(1)数据准备相当耗时和费力,标记一个实例[13]大约需要10秒;(2)由于真实世界数据的固有长尾分布,一些罕见的实例出现的频率非常低,例如濒危动物。具体来说,日常应用迫切需要通过“少样本学习”来削减成本,而通用技术和策略可能容易在少样本场景下将噪音捕捉为普通概念(如过拟合)或分歧(如不拟合)。然而,当显示小数据和相关标签时,即使是孩子也可以快速提取特定于任务的概念。因此,它鼓励我们发展少样本目标检测(FSOD),不仅需要尽可能少的监督,而且应该优于/接近多样本探测器,如图1所示。特别是严格限制监督总量,不限制监督形式。在这里,我们主要讨论三种主要的少样本头设置,如Section I-B所示。
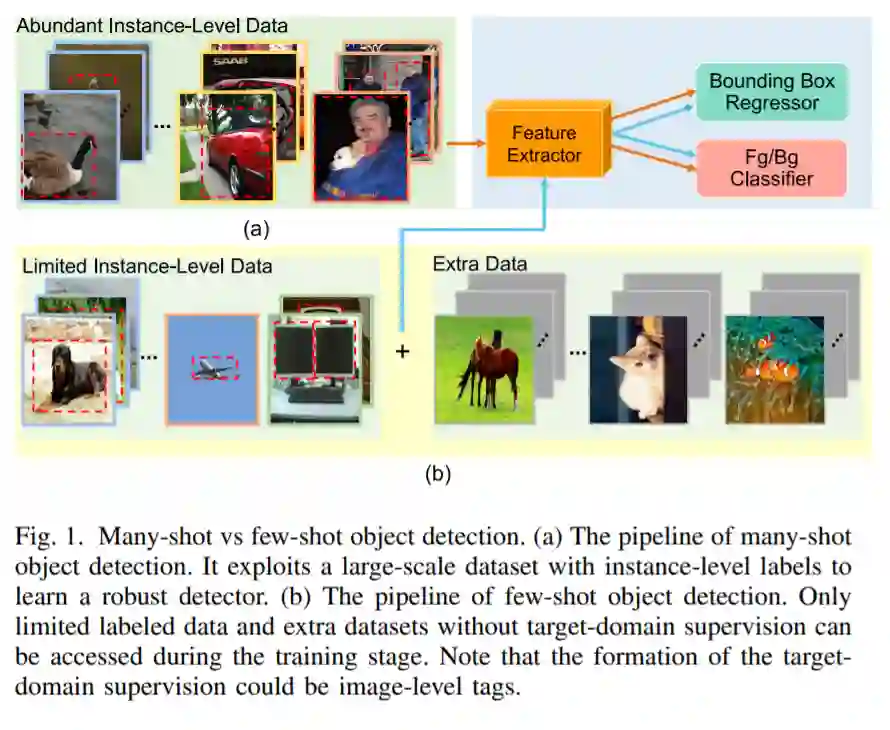
近年来,少样本学习取得了几个关键性的突破,特别是在少样本分类(FSC)[14] -[27]。受FSC近期进展的启发,早期的工作将FSOD视为FSC问题,首先利用区域提议算法(如SS[28])来生成初步感兴趣区域(RoI),并对每个RoI进行分类,无论是否包含目标。但是,与FSC不同的是,FSOD更加复杂,不仅需要对每个RoI进行分类,还需要对每个RoI进行精确的定位。孤立地看待两个互补的子任务是不可行的。由于过多的低质量和模糊的建议可能会混淆元分类器,早期的工作相对来说精度较低。后续工作开始采用一种新的方案,同时对两个子任务的少样本检测器进行优化,以获得高质量的方案。特别是,[29]几种基于度量的方法为边界框回归器提供了特定于类别的概念(例如,宽高比和目标的大小)。此外,现有的方法仍然依赖于现有的检测器,如R-CNN、YOLO和SSD变体[9]-[12]、[30]、[31],它们最初是为了处理多样本问题而设计的,没有特别考虑到少样本问题。经典架构不仅要穷尽所有的位置搜索是否覆盖目标,还需要将特征与目标形状相关联,这也要求主干要高效地将形状和类的概念编码成新类目标的语义。然而,在低资源头场景中,过大和过低的类内变化是非常常见的,类内变化往往带来低的类间差异,而低的类内变化通常导致低数据多样性(例如,宽高比)。利用有限的数据来学习鲁棒编码器是很困难的,因此少样本检测器无法从非鲁棒特征中提取高质量的建议。因此,许多FSOD方法利用额外的数据集[32],[33]来获取这些重量级框架的通用概念(例如,预训练的骨干[8],[34]-[36]),这有利于解决少样本挑战,而不是从头开始训练。为了获得高性能,一些作品假设一个新类别与基类别有密切的关系,例如共享的视觉组件(颜色/形状/纹理),添加额外的约束(KL发散)来有效地将共享的概念转移到新类别。但也带来了一些新的问题,如领域转移[37]、[38]等,源领域知识不能很好地适应目标领域。在这种情况下,这种训练前阶段对新任务的影响很小,FSOD方法很容易混淆高度相似的类,并且由于域间和域内的噪声支持很少,在定位新类[38]-[41]的目标时存在不确定性(章节I-C)。此外,大多数FSOD方法都集中在经典的N-way K-shot设置上,因为它不需要考虑不平衡问题,与其他经典设置相比,在Section I-B中,它不需要从从目标域收集的额外未标记数据中获取隐含信息。总之,FSOD还有很长的路要走。
在这里,我们将本文的范围限制在如何在少样本/有限监督设置下学习一个合格的检测器。为了内容的完整性,我们还简要回顾了目标检测、少样本学习、半监督学习和弱监督学习的进展。主要贡献总结如下:
我们识别了少样本学习问题,并提出了一种新的基于数据的分类方法,以研究FSOD的主要挑战和现有解决方案。
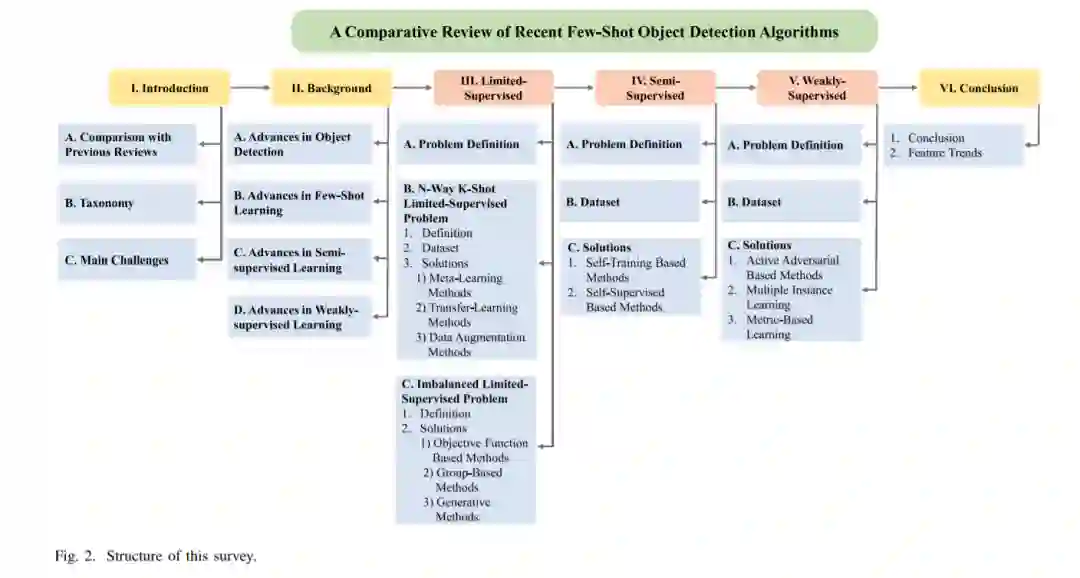
系统总结现有解决方案。我们的综述的概要包括少样本目标检测问题的定义,基准数据集,评估指标,主要方法的总结。特别地,对于这些方法,我们提供了详细的分析,这些方法如何相互作用,以促进这个有前景的领域的发展。
提出并讨论了本课题潜在的研究方向。
公众号后台回复“重邮”获取本文PDF
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“重邮”获取最新目标检测算法综述PDF~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



