

近年来,深度学习快速发展,在广泛的应用中取得了最先进的性能。然而,训练模型通常需要昂贵且耗时的收集大量标记数据。在医学影像分析(MIA)的范围内尤其如此,其中数据有限,获得标签的成本很高。因此,标记高效的深度学习方法能够综合利用已标记数据以及丰富的无标记和弱标记数据。**在本综述中,广泛调研了最近的300多篇论文,对MIA中的标记有效学习策略的最新进展进行了全面的概述。**首先介绍了标记有效学习的背景,并将这些方法分为不同的方案。接着,分别从各个方案出发,详细介绍了当前最先进的方法;进行了深入的研究,不仅涵盖了规范的半监督、自监督和多示例学习方案,还包括最近出现的主动和标注高效的学习策略。此外,作为对该领域的全面贡献,本综述不仅阐明了所调研方法的共同点和独特之处,还详细分析了该领域当前的挑战,并提出了未来研究的潜在途径。 1. 引言
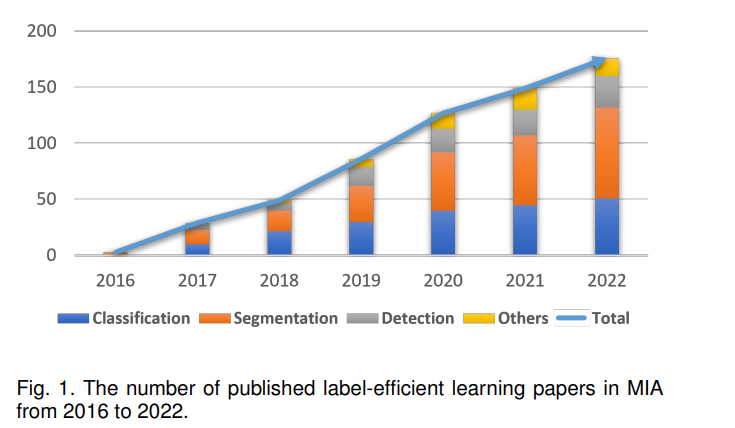
**计算机辅助医学图像分析(MIA)在实现疾病的早期发现、诊断和治疗的高效性和准确性方面起着越来越重要的作用。**近年来,由深度学习(DL)驱动的MIA系统为从大型异构医学图像数据集中学习提供了更客观的方法,提高了疾病诊断的准确性。然而,由于深度学习模型的数据驱动性质,需要丰富的精确标注数据来有效捕捉解剖异质性和疾病特异性特征[1]。不幸的是,由于可用的注释器[2]的短缺,注释的需求和可用的注释数据集之间存在着显著的差距。因此,最小化标注成本、加速标注过程、减轻标注者的负担成为基于DL的MIA任务的关键挑战。而传统的全监督深度学习方法只依赖于完全标注的数据集。近年来,基于半监督、自监督和多示例学习的策略被广泛应用于最大化现有医疗数据的效用,这些数据可能仅由点、涂鸦、盒、像素等部分标注,甚至完全没有标注。本文将这些方法称为标记有效学习。如图1所示,近年来标签有效的学习方法显著增加。与此同时,在其他MIA任务(如去噪、图像配准和超分辨率)中表现出色的标记有效学习方法也已经超越了常见的分类、分割和检测。
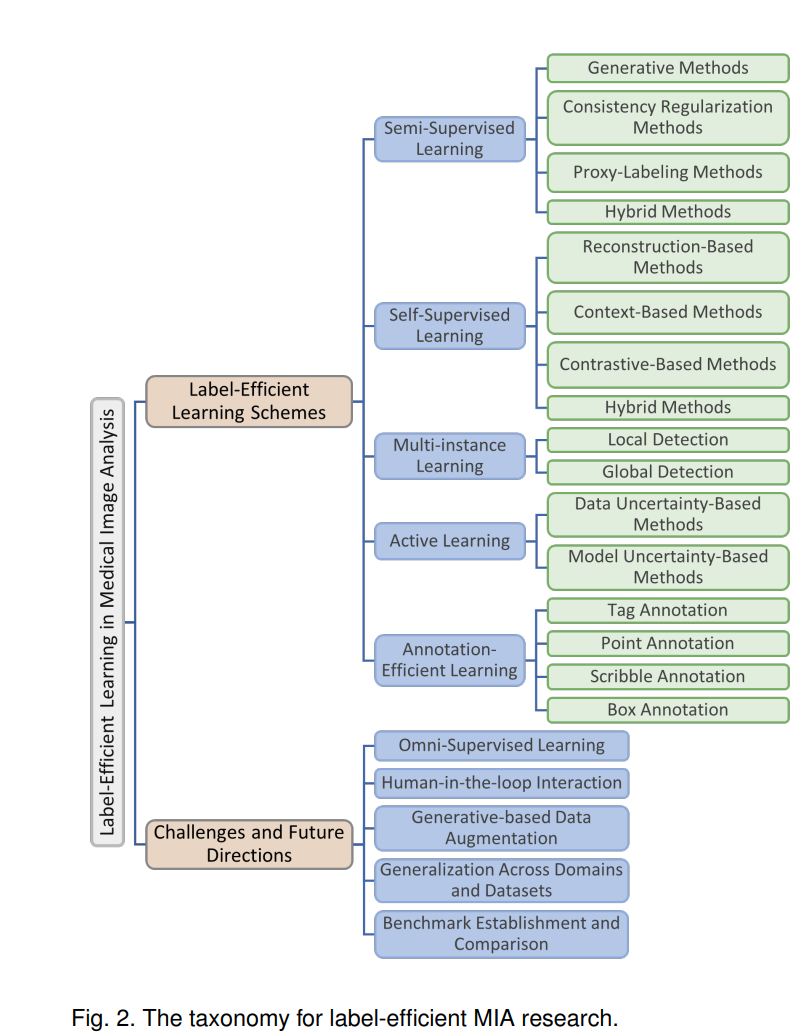
**近年来,一些关于医学图像分析中标签有效学习的研究发表。Cheplygina et al.[3]将方法分为监督、半监督、多示例和迁移学习,并将其命名为“无监督”学习,Budd et al.[4]调查了MIA任务的人在环策略。**然而,这些调查中的方法要么范围有限,要么落后于当前的趋势。为解决这个问题,本文对当前的标签有效方法进行了系统的回顾,其大纲如图2所示。为了提供MIA中标记高效学习方法的全面概述和未来挑战,回顾了300多种基于半监督、多实例、自监督、主动和标注高效学习策略的质量保证和最近的标记高效学习方法。据我们所知,这是标签高效MIA领域的第一个全面综述。在每个学习方案中,制定基本问题,提供必要的背景,并一个案例一个案例地展示评估结果。结合调查最后提出的挑战,在几个分支中探索了可行的未来方向,为标记高效学习的后续研究提供了潜在的启发。 **本文的其余部分组织如下。**在第2节中,介绍了必要的背景和分类。在第3 - 7节中,我们介绍了MIA中主要的标记高效学习方案,包括第3节的半监督学习,第4节的自监督学习,第5节的多示例学习,第6节的主动学习,以及第7节的标注高效学习。讨论了标签高效学习中存在的挑战,并在第8节中为这些开放问题提出了几种启发式解决方案,并提出了有希望的未来研究方向。最后,在第9节对本文进行总结。
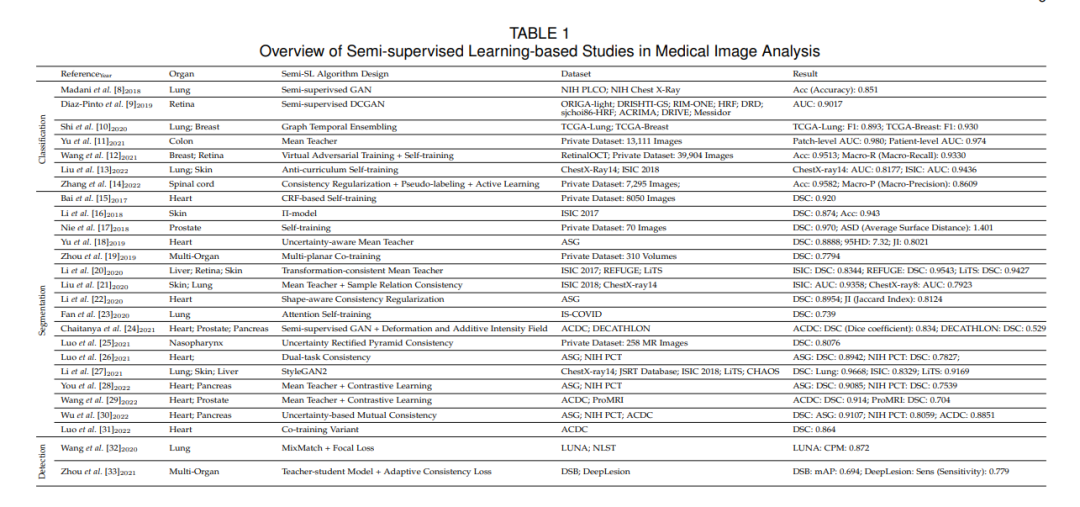
2. 半监督学习的医学影像分析
3.1 代理标记方法
代理标记方法为未标记的数据样本XU提供代理标记。它们将那些具有高置信度代理标签的数据样本包含在训练数据集中,以迭代的方式进行训练。代理标注方法主要可以分为两大类:自训练方法和多视角学习方法。 2.2 生成方法
生成式半监督假设整个数据集X是由相同的潜在分布生成的。从这个意义上说,生成方法的关键是在无标记数据的帮助下学习和模拟潜在分布。然后,具有良好学习潜在分布的模型旨在通过结合监督信息来提高性能。 2.3 一致性正则化方法
一致性正则化方法基于平滑性或流形假设,遵循数据点的扰动不会改变模型的预测的思想。同时,该过程不需要标签信息,这被证明是学习无标签数据的有效约束 2.4 混合方法
一个新兴的半监督学习研究方向是将上述类型的方法结合在一起并将其统一到一个整体框架中以获得更好的性能[12],[14],[32]。在本调研中,这些方法被称为混合方法。例如,Wang et al.[12]和Zhang et al.[14]将一致性正则化与自训练相结合来解决医学图像分类问题。此外,Mixup[61]作为一种有效的数据增强策略在混合方法中被频繁使用。在[62]中,作者在输入空间和潜空间上实现了Mixup,以基于已标记和未标记数据创建更多的样本标签对,以促进医学图像分类。Wang等人利用Mixup和focal loss改进了将一致性正则化和伪标记相结合的MixMatch[63],用于3D医学图像检测领域。通过利用多种半监督方法,该模型能够学习底层不变特征,同时具有较强的预测能力 **
**

