这个演讲概述了为什么自监督学习是医疗人工智能中一些重大转化挑战的关键解决方案,并涵盖了我的团队最近在这个领域的一些研究工作。
从有限的标记数据中学习是机器学习的一个基本问题,对医学图像进行标注费时且昂贵,因此对医学图像的分析至关重要。从有限的标记数据中学习的两种常见预训练方法包括:(1)在大型标记数据集(如ImageNet)上进行监督预训练,(2)在未标记数据上使用对比学习(如[16,8,9])进行自监督预训练。在预训练后,对感兴趣的目标标记数据集进行监督微调。虽然ImageNet预训练在医学图像分析中无处不在[46,32,31,29,15,20],但自监督方法的使用受到的关注有限。自监督方法很有吸引力,因为它们能够在预训练期间使用未标记的特定领域图像来学习更相关的表示。
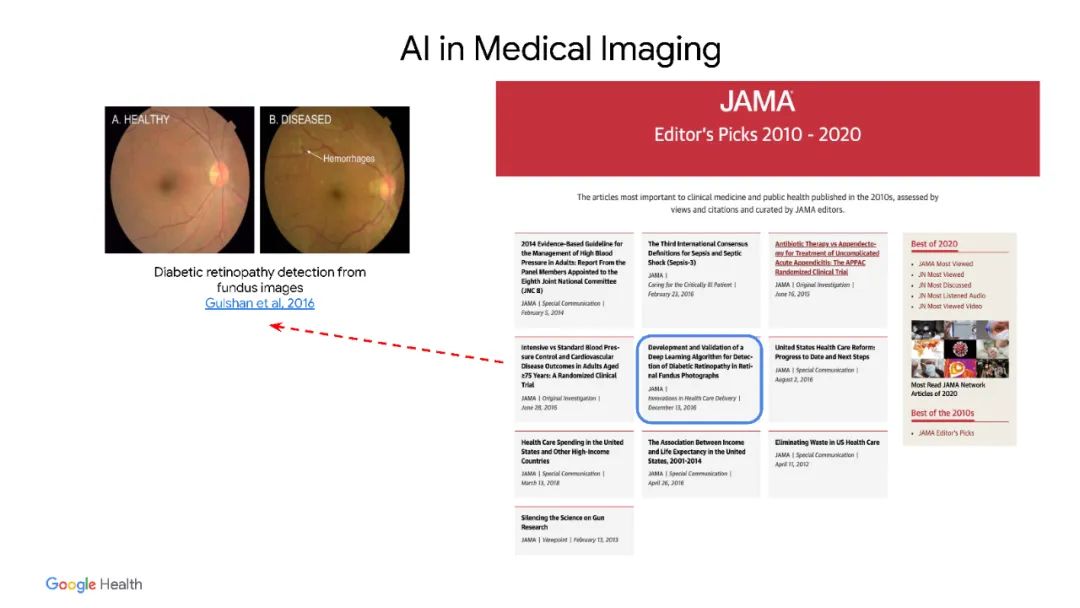
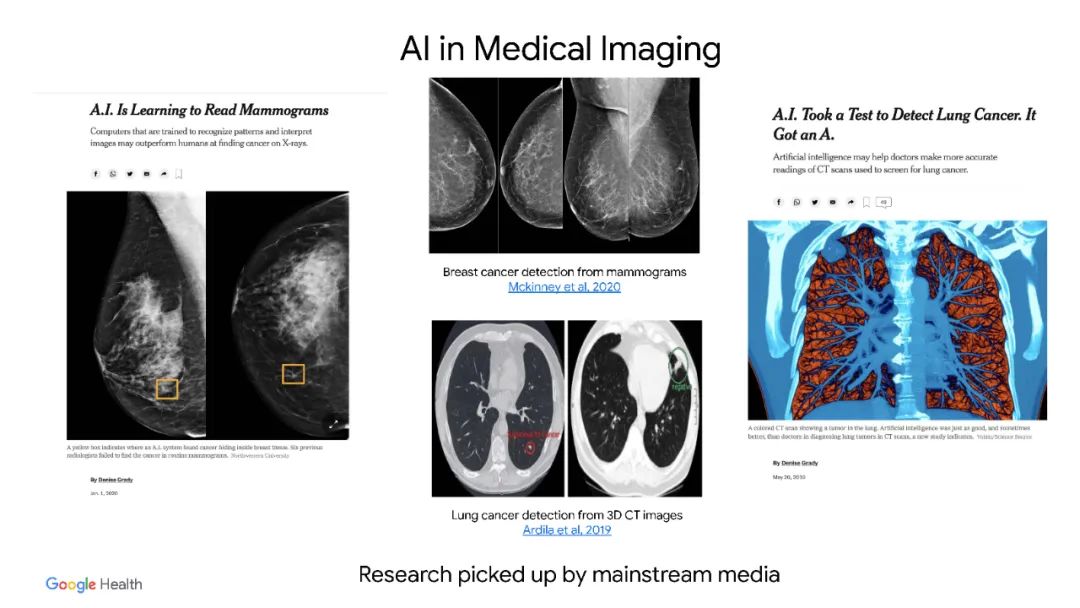
医学人工智能(AI)的最新进展已经交付了可以达到临床专家水平性能的系统。然而,当在不同于训练环境的临床环境中进行评估时,这种系统往往表现出次优的“分布外”性能。一种常见的缓解策略是使用特定位点数据[1]为每个临床环境开发单独的系统。然而,这很快就变得不切实际,因为获取医疗数据非常耗时,并且注释[2]的成本很高。因此,"数据高效泛化"问题为医疗人工智能的发展带来了持续的困难。尽管表示学习的进展显示出了希望,但其好处尚未得到严格研究,特别是在分布外的情况下。为应对这些挑战,本文提出补救策略,一种统一的表示学习策略,以提高医学成像AI的鲁棒性和数据效率。REMEDIS使用了大规模监督迁移学习与自监督学习的通用组合,几乎不需要针对特定任务的定制。研究了各种各样的医学成像任务,并使用回顾性数据模拟了三个现实的应用场景。remedy表现出显著改善的分布性能,与强监督基线相比,诊断准确性相对提高了11.5%。更重要的是,该策略实现了医学成像AI强大的数据高效泛化,使用1%到33%的跨任务再训练数据匹配强监督基线。这些结果表明,补救可以显著加快医学成像AI发展的生命周期,从而为医学成像AI带来广泛影响迈出了重要一步。