摘要——深度神经网络(Deep Neural Networks, DNNs)在计算机视觉与自然语言处理等领域取得了显著的性能表现,并广泛应用于学术界与工业界。然而,随着近年来DNN及拥有大量参数的Transformer模型的快速发展,将这些大型模型部署在边缘设备上面临诸多挑战,例如高运行时延迟与内存消耗等问题。尤其是在当前大规模基础模型(Foundation Models)、视觉-语言模型(Vision-Language Models, VLMs)和大语言模型(Large Language Models, LLMs)不断涌现的背景下,这一问题尤为突出。 知识蒸馏(Knowledge Distillation, KD)是为了解决上述问题而提出的一种重要技术,通常采用教师-学生(Teacher-Student)结构。具体而言,通过从性能强大的教师模型中提取额外知识,用以训练一个轻量级的学生模型。 本文提出了一个关于知识蒸馏方法的全面综述,涵盖多个角度的分析:蒸馏源、蒸馏策略、蒸馏算法、跨模态蒸馏、知识蒸馏的应用,以及现有方法之间的对比分析。与现有的大多数综述相比,后者往往内容过时或仅是对先前工作的简单更新,本文提供了一种全新的视角与组织结构,系统性地分类并研究了最新的知识蒸馏方法。 此外,本综述还纳入了多个关键子领域的研究进展,包括扩散模型(Diffusion Models)、三维输入(3D Inputs)、基础模型、Transformer结构与大语言模型(LLMs)中的知识蒸馏。最后,本文还探讨了当前知识蒸馏面临的挑战以及未来可能的研究方向。 项目GitHub页面: https://github.com/IPL-Sharif/KD-Survey 关键词:知识蒸馏,知识迁移,教师-学生结构
一、引言
随着深度神经网络(Deep Neural Networks, DNNs)的兴起,计算机视觉(Computer Vision, CV)和自然语言处理(Natural Language Processing, NLP)领域迎来了革命性的发展。目前,这些领域中的大多数任务均已由DNN主导完成。尽管诸如ResNet [1] 或 BERT [2] 等模型可在现有大多数GPU上轻松训练,但随着大型模型(如大语言模型LLMs和视觉基础模型)的出现,模型的训练与推理在运行时效率与内存消耗方面成为一大挑战,尤其是在部署于移动设备等边缘终端时问题更加突出。 尽管这些大型模型在性能方面表现优越,但其通常架构复杂、参数量巨大,存在过度参数化(overparameterization)的问题 [3][4]。例如,研究表明LLMs中的权重矩阵呈现低秩结构 [5]。 为了解决大模型带来的问题,研究者提出了多种方案,包括高效网络结构、模型压缩、剪枝、量化、低秩分解以及知识蒸馏(Knowledge Distillation, KD)等。其中,近年来涌现出如MobileNet [6]、ShuffleNet [7]、BiSeNet [8]等高效网络模块。剪枝作为压缩方法的一种,旨在删除冗余的层与参数,同时尽可能保持模型性能;低秩分解则通过矩阵分解来减少参数量。而与此不同,知识蒸馏并不直接改变模型结构或参数,而是通过一个轻量学生模型在性能强大、参数丰富的教师模型监督下进行训练。
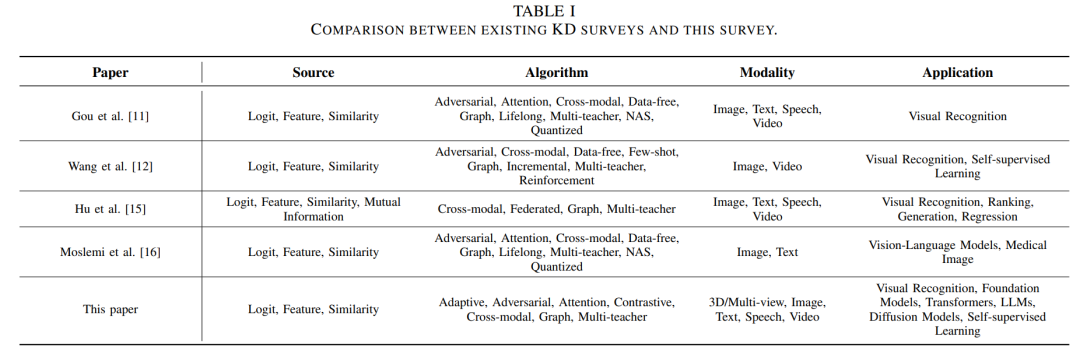
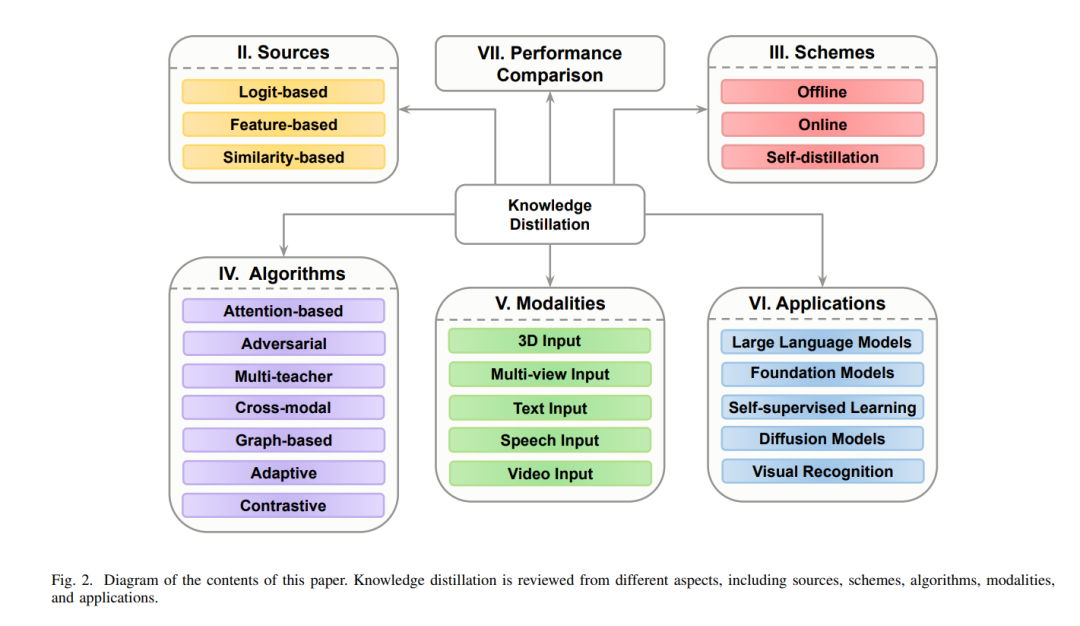
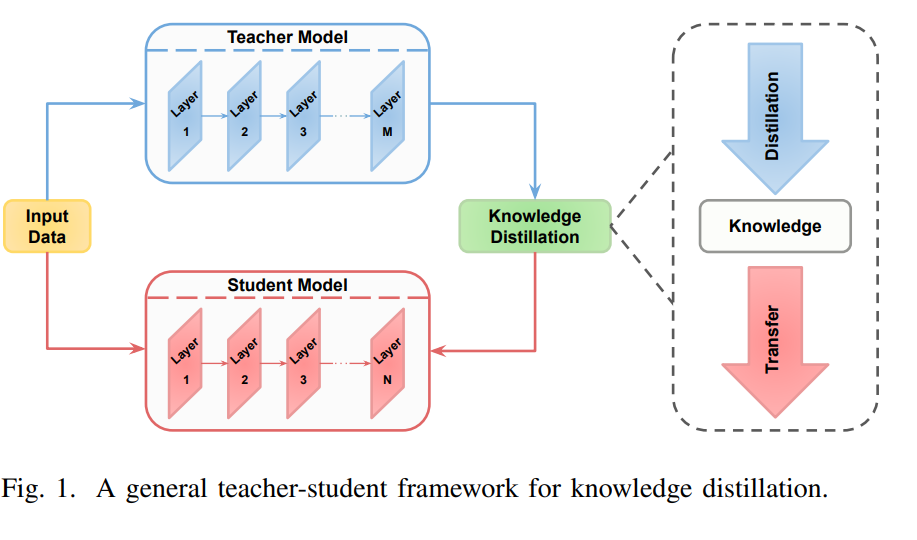
这一概念最早由 [9] 提出,并在 [10] 中被正式命名为知识蒸馏(KD),其核心思想是通过模拟教师模型的输出分布(软标签)来训练学生网络。 除了参数量庞大外,这些大型模型的训练还需要大量标注数据。KD的另一个重要用途是知识迁移,即将源任务中的知识迁移到缺乏足够标注数据的目标任务中。此外,在涉及数据隐私的场景中,数据无关的知识蒸馏(data-free KD)则通过合成数据生成,避免了存储敏感数据的需求。KD面临的主要挑战包括:如何选择要迁移的知识、采用何种蒸馏算法,以及如何设计合适的教师与学生架构。图1展示了典型的教师-学生KD结构。 随着KD研究论文数量的迅速增长及其在多任务、多领域中的广泛应用,已有若干综述工作试图从不同角度对该领域进行总结。例如,[11] 从知识类型、算法和策略等方面对KD进行了全面回顾,并对不同方法进行了比较;[12] 聚焦于视觉任务中基于教师-学生架构的模型压缩方法;[13] 通过引入新指标对KD方法进行精度与模型大小上的评估;[14] 则基于蒸馏知识源类型对现有方法进行了分类;更近期的 [15] 对不同表征形式下的知识优化目标进行了深入综述,[16] 则对以往综述进行了扩展,并简要讨论了视觉-语言模型(VLMs)中的蒸馏及数据有限情形下的挑战。 尽管上述综述涵盖了多个重要视角,但它们也存在一些明显的局限性。首先,这些工作在分析已有方法时,往往忽略了近年来在特征级蒸馏(feature-based distillation)方面的重大进展,而该方向目前已成为最主流的研究路径之一。此外,自适应蒸馏(adaptive distillation)和对比蒸馏(contrastive distillation)等新兴算法类别几乎未被提及。其次,随着基础模型与LLMs的快速发展,其在知识蒸馏中的巨大潜力并未被现有综述充分讨论。例如,[11] 作为当前最具影响力的综述之一,并未详细探讨基础模型和LLMs中KD的应用。第三,目前尚无综述研究KD在三维输入(如点云)上的应用。随着三维任务在顶级会议中受到越来越多关注,相关模型与方法的缺乏使得KD在该领域的应用显得尤为重要。表I展示了现有综述与本工作的比较。 因此,本文提出了一个对知识蒸馏方法的系统性综述,涵盖多个维度:蒸馏源、蒸馏算法、蒸馏策略、模态划分及应用领域。 本综述对三类蒸馏源进行了分类与分析:基于logits、基于特征、基于相似性的蒸馏方法,特别强调了近年来特征蒸馏方面的研究进展。 在算法层面,本文回顾了包括注意力机制、对抗式、多教师、跨模态、图结构、自适应及对比蒸馏等方法。其中,自适应与对比蒸馏作为两个尚未被系统综述的热点领域,在本工作中首次被单独归类。 在蒸馏策略方面,涵盖了离线蒸馏、在线蒸馏及自蒸馏方法。相比以往工作,本文新增了一部分内容,系统梳理了基于模态的蒸馏方法,包括视频、语音、文本、多视角(multi-view)以及三维数据。 在应用方面,本文对知识蒸馏在多个关键领域的应用进行了深入探讨,包括自监督学习、基础模型、Transformer架构、扩散模型、视觉识别任务及大语言模型。此外,还对典型方法进行了量化比较,并讨论了当前面临的挑战与未来研究方向。 图2展示了本文的组织结构。总的来说,本文的主要贡献包括: * 提出一个全面的知识蒸馏综述,从蒸馏源、算法、策略、模态及应用等多角度系统总结现有方法; * 对近年来涌现的特征蒸馏方法进行重点分类与归纳,反映其在实际应用中的重要性; * 首次引入“自适应蒸馏”和“对比蒸馏”两类新算法,尤其是在如CLIP等基础模型出现后,对比蒸馏的重要性日益突出; * 回顾了多视角与三维数据中的知识蒸馏方法,填补了该领域综述中的空白; * 深入探讨了KD在自监督学习、基础模型、Transformer、扩散模型和LLMs中的应用,特别强调在参数量巨大的LLMs中蒸馏的重要性; * 提供了典型蒸馏方法的量化对比,并总结了当前的研究挑战与未来的研究方向。