

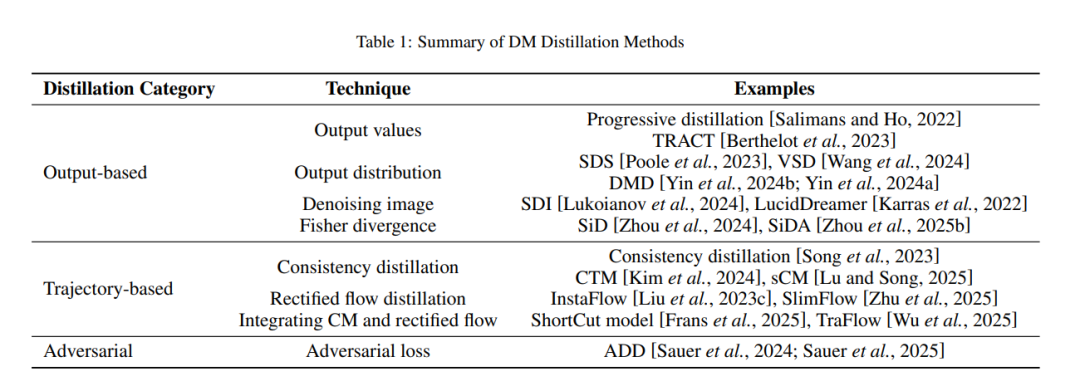
扩散模型(DMs)已成为生成性人工智能(GenAI)中的主流方法,凭借其在文本到图像合成等任务中的出色表现。然而,实际应用中的扩散模型,如稳定扩散,通常需要在庞大的数据集上进行训练,因此通常需要大量存储。同时,为了生成高质量的图像,可能需要多次步骤,即递归地评估训练过的神经网络,这在样本生成过程中导致了显著的计算成本。因此,基于预训练扩散模型的蒸馏方法已成为开发较小、效率更高的模型的广泛应用实践,这些模型能够在低资源环境中进行快速且少步骤的生成。当这些蒸馏方法从不同的角度发展时,急需进行系统性的综述,特别是从方法论的角度出发。在本综述中,我们从三个方面回顾了蒸馏方法:输出损失蒸馏、轨迹蒸馏和对抗蒸馏。我们还讨论了当前的挑战,并在结论中概述了未来的研究方向。
成为VIP会员查看完整内容
相关内容

Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日