**摘要
扩散模型(Diffusion Models, DMs)已成为强大的生成模型,在图像、视频、音频等内容生成任务中展现出卓越性能,并具有变革数字内容创作的潜力。然而,这些能力伴随着高昂的计算资源消耗和较长的生成时间,这凸显了开发高效扩散模型的必要性,以推动其实用化部署。 在本综述中,我们对高效扩散模型的研究进展进行了系统性和全面性的回顾。我们基于现有研究,提出了一种三大类别的分类体系,分别涵盖算法级优化、系统级优化以及框架级优化,以梳理不同层面上相互关联的高效扩散技术:
- 算法级优化(Algorithm-Level Efficiency):包括加速采样(如 DDIM、DPM-Solver)、自适应步长方法、潜空间扩散(LDMs)、知识蒸馏等。
- 系统级优化(System-Level Efficiency):涉及模型架构改进(轻量级 U-Net 变体、基于 Transformer 的优化)、并行计算、高效 GPU/TPU 部署策略等。
- 框架级优化(Framework-Level Efficiency):涵盖优化工具链(如 ONNX、TensorRT)、分布式训练技术,以及高效推理框架的集成。
此外,我们整理了本综述中涉及的论文,并在 GitHub 仓库 Efficient Diffusion Model Survey 中进行分类归纳,以便研究人员查阅和使用。 我们希望本综述能够成为研究者和从业者的重要资源,帮助他们系统性地理解高效扩散模型的研究进展,并激发更多人在这一重要且充满前景的领域做出贡献。
1. 引言
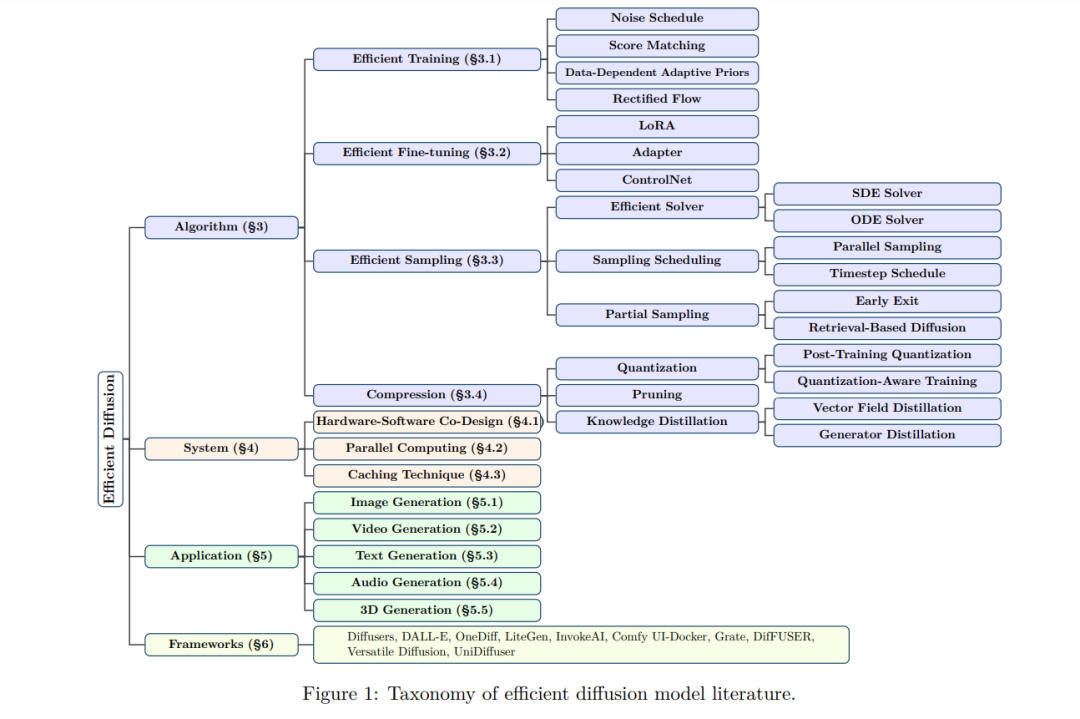
扩散模型(Diffusion Models, DMs)开启了人工智能生成内容(AIGC, Artificial Intelligence Generative Content)领域的新时代,并受到了前所未有的关注(Yang et al., 2023b; Croitoru et al., 2023b)。特别是在图像合成任务中,扩散模型展现出了强大且多样化的生成能力。此外,扩散模型的跨模态生成能力进一步推动了众多下游任务的发展(Chen et al., 2023b)。尽管扩散模型的各类变体经过多次迭代已日趋成熟(Zhang et al., 2023d; Xu et al., 2023),但生成高分辨率、复杂的自然场景仍然十分耗时,并需要大量计算资源,无论是像素级扩散方法(Ho et al., 2020)还是潜空间变体(Rombach et al., 2022)。因此,为了优化扩散模型的用户级部署,研究者们一直在探索高效扩散模型的可能性。 近年来,扩散模型的普及度持续上升,但其中一个主要问题是其多步去噪过程:模型需要经历多个时间步(timesteps)才能从随机噪声生成高质量样本。这一多步生成机制不仅耗时,而且计算密集,导致计算负担巨大。因此,提高扩散模型的计算效率至关重要。针对这一问题,已有多项研究尝试提出解决方案,例如优化训练过程中添加的噪声(Hang & Gu, 2024; Chen et al., 2023a),以及选择适当的采样时间步(Watson et al., 2021; Sabour et al., 2024)等方法。 尽管已有许多关于扩散模型的全面综述(Yang et al., 2023b; Chen et al., 2024; Croitoru et al., 2023a; Cao et al., 2024),以及针对特定领域和任务的综述(Ulhaq et al., 2022; Lin et al., 2024c; Kazerouni et al., 2023; Lin et al., 2024b; Peng et al., 2024b; Daras et al., 2024),但关于扩散模型效率优化的系统性研究仍然较为稀缺。目前唯一一篇专门讨论高效扩散模型的综述(Ma et al., 2024c)仅为该领域的初步探索。在本研究中,我们提供了更全面和详细的分类体系,涵盖更广泛、更新的研究文献,并提供更系统的技术综述。 本综述的总体目标是全面梳理高效扩散模型的技术进展,从算法级、系统级、应用级和框架级四个不同视角进行讨论,如图 1 所示。这四个类别涵盖了不同但紧密相关的研究主题,共同构成了系统化的高效扩散模型综述:
- 算法级方法(Algorithm-Level Methods):优化扩散模型的训练和推理效率,涵盖高效训练、高效微调、高效采样及模型压缩等方向(见 §3)。
- 系统级方法(System-Level Methods):优化计算基础设施和资源利用,涵盖硬件-软件协同设计、并行计算、缓存优化等(见 §4)。
- 应用(Applications):扩散模型在图像、视频、文本、音频和 3D 生成等领域的优化方法,以在不损失生成质量的前提下提升效率(见 §5)。
- 框架(Frameworks):专门针对扩散模型的高效训练、微调、推理和部署框架,涵盖**主流 AI 框架(如 TensorFlow 和 PyTorch)**的优化扩展,以及专门设计的高效扩散模型框架(见 §6)。
此外,我们创建了一个GitHub 论文资源库,汇总了本综述中涉及的相关论文,并将持续更新,以收录最新的研究进展:Efficient Diffusion Model Survey。我们希望本综述能够成为研究者和从业者的重要资源,帮助他们系统理解高效扩散模型的研究进展,并激发更多研究人员在这一重要且前沿的领域做出贡献。