

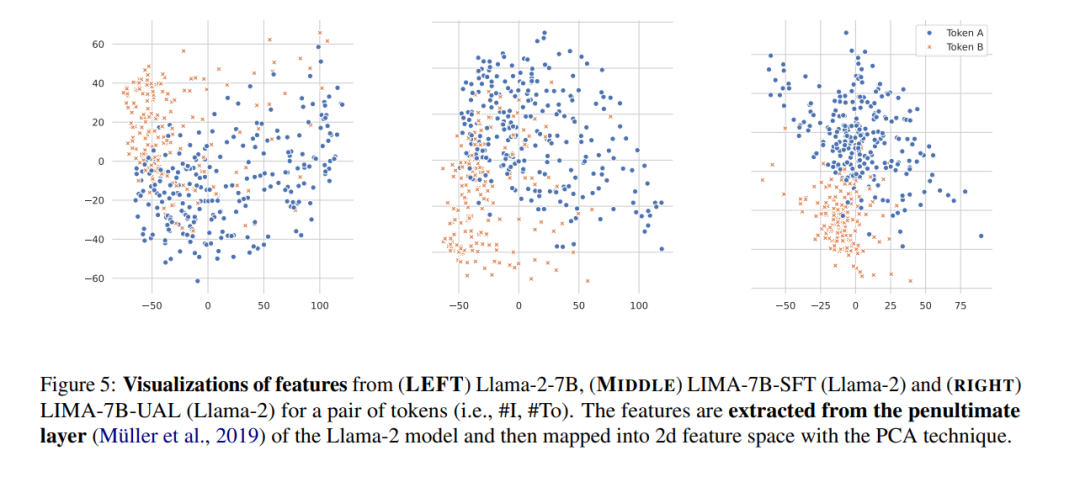
随着指令微调的大型语言模型(LLMs)的发展,对预训练基础模型的对齐带来了越来越多的挑战。现有的对齐策略通常利用多样化且高质量的数据源,但往往忽视了任务本身的内在不确定性,导致所有数据样本的学习权重相同。这可能会导致数据效率和模型性能的次优表现。为此,我们提出了不确定性感知学习(UAL),通过引入样本的不确定性(从更强大的LLMs中获得),以改进不同任务场景下的模型对齐。我们通过一种简单的方式实现UAL,即根据个别样本的不确定性自适应地设置训练的标签平滑值。分析显示,我们的UAL确实促进了特征空间中更好的token聚类,验证了我们的假设。在广泛使用的基准测试上进行的大量实验表明,我们的UAL显著且持续地优于标准的监督微调。值得注意的是,在混合场景中对齐的LLMs在高熵任务(如AlpacaEval排行榜)上平均提高了10.62%,在复杂低熵任务(如MetaMath和GSM8K)上提高了1.81%。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日