

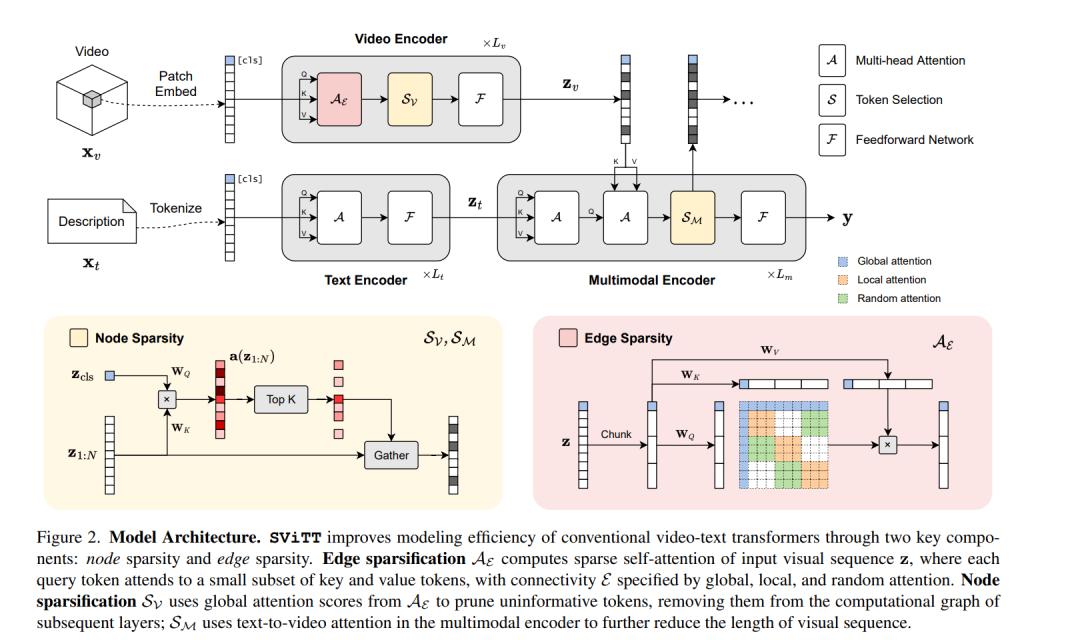
视频-文本Transformer学会跨帧建模时间关系吗?尽管具有巨大的容量和丰富的多模态训练数据,但最近的工作表明视频文本模型倾向于基于框架的空间表示,而时间推理在很大程度上仍未得到解决。本文确定了视频文本transformer时间学习中的几个关键挑战:有限网络大小的时空权衡;多帧建模中的维数灾难问题以及随着剪接长度的增加语义信息的收益递减。在这些发现的指导下,本文提出SViTT,一种稀疏视频-文本架构,执行多帧推理,成本明显低于朴素密集注意力transformer。与基于图的网络类似,SViTT采用了两种形式的稀疏性:边的稀疏性,限制了自注意力中token之间的查询键通信,以及节点的稀疏性,丢弃了没有信息的视觉token。SViTT使用随剪辑长度增加模型稀疏性的课程进行训练,在多个视频-文本检索和问答基准上优于密集transformer基线,计算成本很小。
项目页面:http://svcl.ucsd.edu/projects/svitt。
成为VIP会员查看完整内容
相关内容

CVPR 2023大会将于 6 月 18 日至 22 日在温哥华会议中心举行。CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。
CVPR 2023 共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。
Arxiv
21+阅读 · 2020年12月17日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
21+阅读 · 2020年12月17日