

生成式人工智能技术已经在许多地方得到了应用,例如(多模态)大型语言模型和视觉生成模型。它们的显著性能应归功于大量的训练数据和新兴的推理能力。然而,这些模型会记住并生成来自训练数据中的敏感、偏见或危险的信息,尤其是那些来自网络爬虫的数据。新的机器遗忘(MU)技术正在开发,以减少或消除不良知识及其对模型的影响,因为那些设计用于传统分类任务的技术无法应用于生成式AI。我们提供了一个关于生成式AI中MU的全面综述,如新的问题表述、评估方法以及对不同类型MU技术的优缺点的结构化讨论。还提出了MU研究中的一些关键挑战和有前途的方向。一个精选的阅读列表可以在以下网址找到: https://github.com/franciscoliu/GenAI-MU-Reading。
机器学习(ML)源于人工智能(AI)构建从数据集D = {(x,y)}中学习模式的模型的追求。模型使用这些模式来预测未见输入x的输出y,根据y是分类变量还是数值变量,称为分类器或回归器。一个有趣的问题是,模型构建后,如果开发人员发现数据集中包含一组不应被学习的数据点Df = {(xf, yf)} ⊂ D,例如,我们可能不希望模型泄露客户的收入,即使它可能看到了很多银行数据。机器遗忘(MU)方法旨在帮助模型“忘记”Df中的数据点(称为遗忘集),使得模型在理想情况下与仅在D \ Df上训练的新模型相同或相似,而MU将比重新训练模型节省大量开发成本。
MU已经在传统AI中得到了研究和审查。最近,基于生成式ML模型的生成式AI(GenAI)展示了其数据生成能力,这些能力可能会用于分类和回归任务。例如,大型语言模型(LLMs)可以在文章之后生成关于其情感、主题或字数的标记。如果提示正确,这意味着,可能有一个提示使得训练在银行数据上的LLM生成“[客户姓名]的收入是[值]”。在这种情况下,人们希望模型“忘记”得如此之深,以至于它在任何提示下都不会生成这个输出:提示可能是强相关的,例如“[客户姓名]的收入是多少?”,也可能是弱相关的,例如“告诉我你认识的某人的收入。”因此,遗忘集必须在GenAI中重新定义,并且许多概念如目标、评估方法和MU技术必须仔细审查。同时,GenAI不仅包括LLMs,还包括许多其他类型的模型,如视觉生成模型和多模态大型语言模型(MLLMs)。这些激励我们写这篇综述,而传统AI的MU综述已经存在。
GenAI中的遗忘集可以定义为Df = {(x,yf) |∀x}或简化为Df = {yf},其中yf可以是任何不希望的模型输出,包括泄露的隐私、有害信息、偏见和歧视、版权数据等,而x是任何提示模型生成yf的东西。由于新的定义,收集一个包含许多数据点(即yf)的大型遗忘集要便宜得多,而这些数据点是训练集D所不包含的。因此,尽管传统AI中的MU主要集中在调整模型使其与仅在D \ Df上训练的模型相同,但人们对机器遗忘的GenAI有至少三个期望,考虑到三个数据点集: * 目标遗忘集 Df = {(x,yf) ∈ D} ⊂ Df, * 保留集 Dr = D \ Df, * 未见的遗忘集 Df = Df \ Df。
假设原始GenAI模型表示为 g : X → Y,遗忘模型表示为 g*。优化(和评估)g*的三个定量目标如下(越高越好): * 准确性:遗忘模型不应生成见过的遗忘集中的数据点:
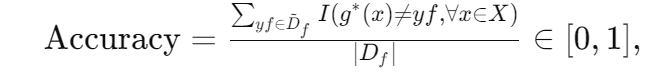
其中 I(stmt) 是一个指示函数——如果 stmt 为真则返回 1,否则返回 0。请注意,我们不期望原始模型总是在 Df 上失败,即 g(x) = yf。因此,可能存在 g 和 g* 在任何提示 x 下都不生成 yf ∈ Df 的情况。
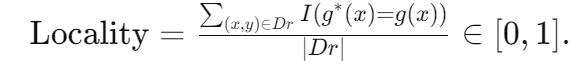
泛化性:模型应将遗忘推广到未见的遗忘集:

重要性。围绕这三个目标,已经为GenAI设计了许多MU技术,并在AI应用中发现了它们的有用性。随着GenAI变得越来越依赖数据,相关方和从业者可能会要求从训练数据集和已训练的模型中删除某些数据样本及其影响,以应对隐私问题和法规要求,如欧盟的《通用数据保护条例》(GDPR)、加利福尼亚州的《消费者隐私法》(CCPA)和《个人信息保护法》(APPI)。为了消除特定样本及其影响而重新训练模型通常是非常昂贵的。因此,MU作为解决这一挑战的方案受到了极大关注并取得了显著进展。 应用。除了保护个人数据隐私,机器遗忘还可以用于其他应用。例如,以前的研究表明,MU可以用来加速留一法交叉验证的过程,识别模型中的有意义和有价值的数据。遗忘还可以作为一种对抗灾难性遗忘的对策,这种现象是指模型在学习了太多任务后性能突然下降。此外,机器遗忘可以作为一种有效的攻击策略来评估模型的鲁棒性,类似于后门攻击。例如,攻击者可以在训练数据集中引入恶意样本,然后要求删除它们,从而影响模型的性能、公平性或遗忘效率。随着模型和任务从标准的ML模型转移到GenAI模型,GenAI机器遗忘(MU)的应用也变得更加多样化。例如,GenAI MU可以用于更好地将GenAI模型与人类指令对齐,并确保生成的内容符合人类价值观。它可以作为一种安全对齐工具,删除有害行为,如有毒、偏见或非法内容。此外,MU可以用来减轻幻觉现象,即GenAI生成看似合理的错误或不准确信息。关于GenAI MU应用的详细分析可以在第6节找到。
1.1 相关综述
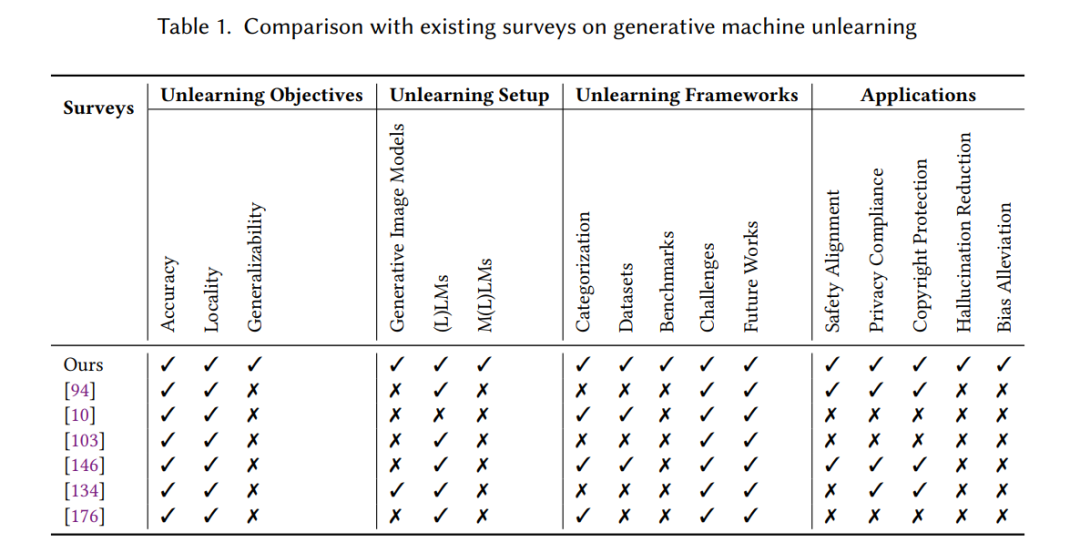
最近,几项研究提供了关于大型语言模型(LLMs)中机器遗忘技术各个方面的宝贵见解。这些研究包括关于机器遗忘的一般综述,如[10, 94, 130, 146, 176],涵盖了从基本概念到各种技术以及该领域潜在挑战的广泛主题。此外,一些研究专注于LLM MU的特定方面;例如,Zhang等人[182]探讨了在LLM MU中实现“被遗忘权”(RTBF)的挑战,并提供了设计合适方法的见解,而Lynch等人[103]则强调了在LLM MU中进行全面遗忘评估的重要性,并提供了设计稳健指标的见解。此外,Liu等人[99]强调了LLM MU中的安全和隐私问题,重点关注威胁、攻击和防御方法。最后,Ren等人[134]强调了各种技术的区别,包括生成模型中的MU和非MU方法及其在版权保护中的应用。 据我们所知,在综合调查现有文献和正在进行的GenAI领域进展的研究中,仍然存在显著的差距。尽管先前的综述主要集中在LLMs或GenAI MU的特定方面,但它们并没有将分类扩展到包括更广泛的生成模型,例如生成图像模型和多模态(大型)语言模型。此外,这些综述缺乏对GenAI MU技术细节的全面审查,包括分类、数据集和基准测试。此外,GenAI遗忘的具体目标,对于指导有效的实践至关重要,也没有得到彻底调查。我们的综述通过制定这些目标,提供了一个清晰和结构化的框架来划定有效遗忘实践的目标和期望,独特地解决了这一问题。通过将目标定义为准确性、局部性和泛化性,我们建立了一个稳健和系统的方法来评估和推进GenAI遗忘方法。 鉴于GenAI MU技术的快速发展,详细审查所有代表性方法并使其与GenAI MU的目标对齐是至关重要的。这包括总结不同类型的共性,突出每个类别和模态的独特方面,并讨论GenAI MU领域中的开放挑战和未来方向。我们的综述旨在通过提供该领域的整体概述,涵盖广泛的生成模型,并提供对最新技术、数据集和评估指标的深入分析,填补这一空白。 1.2 主要贡献
本文对GenAI MU的各个方面进行了深入分析,包括技术细节、分类、挑战和未来方向。我们首先提供了GenAI MU策略分类的概述。具体而言,我们将现有策略分为两类:参数优化和上下文遗忘。重要的是,这两类不仅全面覆盖了所有当代方法,我们还根据不同类型遗忘设计的特征将每类细分为子类。此外,我们对每个类别进行了全面分析,特别强调其有效性和潜在弱点,这可以作为未来研究和开发的基础。具体而言,我们的贡献可以总结如下: * 新颖的问题目标:我们将GenAI MU的任务表述为选择性遗忘过程,不同类别的方法可以看作是去除不同类型知识的各种途径。我们强调,GenAI MU与传统MU的最大区别在于关注遗忘特定输出而非特定输入-输出映射。我们独特地指出,一个有效的GenAI MU方法应基于三个重要目标进行评估:准确性、局部性和泛化性。这个结构化框架为生成模型中的遗忘实践提供了明确和可测量的目标。 * 更广泛的分类:我们涵盖了现有生成模型遗忘技术的全谱,包括生成图像模型、大型语言模型(LLMs)和多模态(大型)语言模型(MLLMs)。具体而言,我们的分类基于如何从预训练生成模型中去除目标知识,结合了两个不同的类别:参数优化和上下文遗忘。综述中全面讨论了每种方法的优点和缺点。 * 未来方向:我们调查了当代GenAI MU技术在各种下游应用中的实用性。此外,我们全面讨论了现有文献中存在的挑战,并突出了该领域未来的潜在方向。
综述的其余部分结构如下:第2节介绍了GenAI MU策略评估指标的全面总结,符合新制定的目标。第3节介绍了机器遗忘和生成模型的背景知识。第4节对不同类型生成模型的现有遗忘策略进行了全面分类,详细强调了它们的关系和区别。第5节介绍了GenAI MU在各种下游应用中常用的数据集和常用的评估基准。第6节全面概述了遗忘技术的实际应用。第7节讨论了GenAI MU中潜在的挑战,并提供了一些可能激发未来研究的机会。最后,第8节总结了这篇综述。

