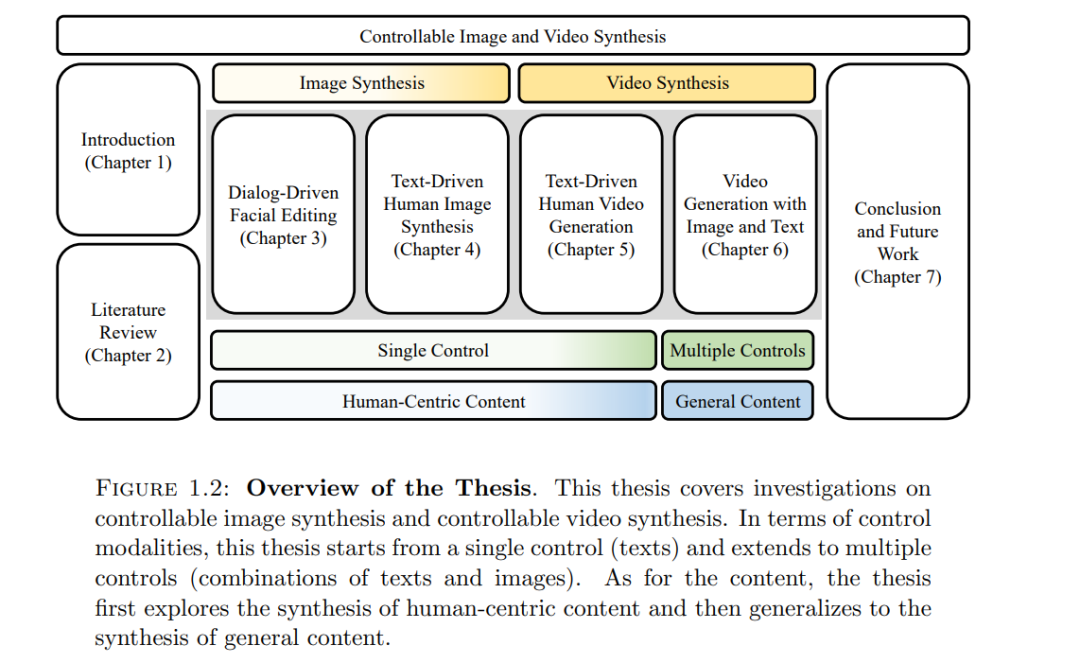
近年来,生成模型取得了显著进展,大大提升了合成图像和视频的质量。本论文在此基础上进一步研究了生成模型的可控性。在提高合成质量的同时,使生成模型具备控制合成内容的能力也至关重要,因为可控性为用户交互和定制内容创作铺平了道路。本论文研究了可控的图像和视频合成,内容包括基于对话驱动的人脸图像操控、文本引导的人体图像与视频生成,以及从文本和图像生成视频。
本论文首先探讨了人脸的操控。为了使人脸编辑更加可控,提出了一种名为“Talk-to-Edit”的方法,该方法通过用户与机器之间的对话逐轮编辑人脸图像。对话由自然语言组成,但比自然语言更具表现力。编辑需求可以通过多轮对话得到澄清。基于对话的编辑要求模型能够执行细粒度的编辑。为了支持细粒度的人脸编辑,在预训练的StyleGAN的潜在空间中建模了一个连续的“语义场”,该语义场考虑了潜在空间的非线性特性。编辑通过沿着语义场遍历潜在空间来实现,轨迹由语言控制引导。
在人脸之外,本论文还探讨了另一类与人相关的媒体——人体全身图像的可控生成。相比人脸,全身图像合成更为复杂,因为涉及许多因素,例如人脸和人体姿态。为了实现更可控的合成,人体全身图像的生成由文本驱动。文本指定了期望服装的长度和外观。为此,提出了一个名为Text2Human的新框架,用于高保真和多样化的人体全身图像生成。该框架构建了一个分层的纹理感知码本,用于存储不同尺度下不同纹理的多种表示。图像生成通过从该码本中采样并使用基于扩散的混合专家Transformer来完成,根据输入的文本进行采样生成。生成的图像进一步通过前馈索引预测网络进行细化。
基于文本驱动的人体图像生成的探索,本论文接着研究了文本驱动的人体视频生成,其中视频序列是根据描述目标人物外观和动作的文本生成的。这要求在执行复杂动作的同时保持生成人物的外观一致性。为此,提出了Text2Performer方法,该方法通过文本生成具有生动动作的人体视频。具体而言,人体表示被分解为外观表示和姿态表示。通过固定外观表示同时采样姿态表示,可以很好地保持外观一致性。姿态表示的采样通过一种新颖的连续VQ扩散模型(VQ-diffuser)实现,该模型直接输出连续的姿态嵌入,以更好地进行动作建模。 最后,除了生成以人为中心的内容外,生成通用视频对于视觉合成系统也非常重要。本论文还旨在提高包含通用物体的视频合成的可控性。合成视频的内容通过文本提示和图像提示进行控制。引入图像提示到文本生成视频模型中的动机是,仅依靠文本提示不足以准确描述与用户意图对齐的期望主体外观,尤其是在定制内容创作中。文本提示通过交叉注意力模块进行嵌入,这是文本生成视频方法中的常见做法。为了有效注入图像提示信息,提出的方法VideoBooth以粗到细的方式注入图像提示。图像编码器的粗略视觉嵌入提供图像提示的高层次编码,而提出的注意力注入模块中的细粒度视觉嵌入则提供图像提示的多尺度和详细编码。这两种互补的嵌入能够忠实地捕捉期望的外观。
总体而言,本论文在图像和视频合成领域提出了几项进展,介绍了灵活的控制方式,增强了用户交互能力,并促进了定制内容的创作。