
编译 | 陈泽慧 审稿 | 张翔 今天给大家介绍一篇最近发表在Journal of Chemical Information and Modeling 上的文章。在文章中,作者通过分子图条件变分自动编码器(MGCVAE)来生成具有指定特性的分子,并进行了多目标优化,以同时满足两个目标特性。
1 简介 药物的分子设计本质上是一个多参数的优化问题,如何生成新的分子结构以及优化分子的目标属性是影响药物设计成败的关键。分子优化在分子生成的基础上,融合了属性约束、相似性约束,使得模型最终可以生成具有指定特性的分子。目前的分子优化方法大多都基于编码器-解码器架构,这些现有的工作大多着眼于对单个属性进行优化,但在实际应用中,对生成分子的多目标优化,往往才更符合各个领域的现实需求。
为此,本文作者首先研究了分子图条件变分自动编码器 (MGCVAE)模型,它用于生成具有特定属性的分子,并在此基础上对 MGCVAE 进行了多目标优化,以同时满足两个选定的特性。在文章中,辛醇-水分配系数(ClogP)和摩尔折射率(CMR)这两个物理特性被用作分子设计的优化目标。为了验证模型的性能,作者比较了无条件的分子图变分自动编码器(MGVAE)和使用特定条件的 MGCVAE 的实验结果,并验证了该方法在大量数据的基础上,生成满足两个理想属性的分子是可行的。
2 方法 分子图 分子图使用节点来表示原子,用边来表示键,并由注释矩阵和调整矩阵来表示分子结构。注释矩阵(𝑁×𝑋,𝑁为原子的数量,𝑋为原子类型的数量)中的每一行为原子的one-hot编码,邻接矩阵(𝑁×𝑁)则用于描述每一行和每一列对应的连接键。分子的初始图矩阵由注释矩阵和邻接矩阵重构而成,以生成完整的分子图,如图1所示。初始图矩阵的尺寸是{S, [1+A+(S·B)]},其中S表示最大的原子数量(最大的图尺寸),A为原子类型的数量,B为键类型的数量。
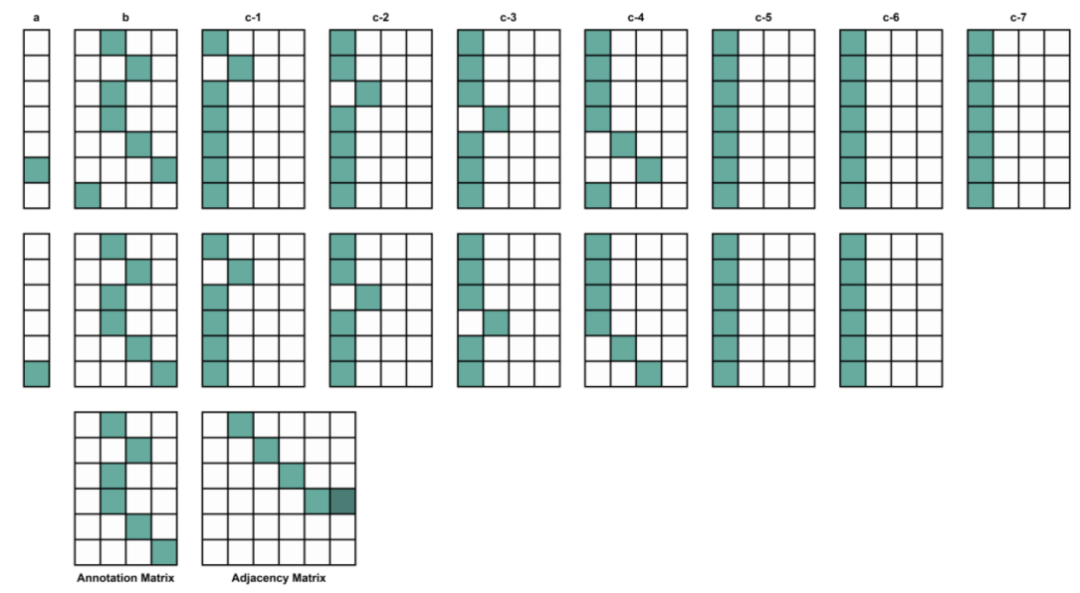
图1. 初始图矩阵的组成部分
条件变分自动编码器(CVAE) 本研究的核心是基于图(而非字符串)的多目标优化,且实现了MGVAE和MGCVAE来生成新分子,并对这两种生成方式做了性能对比。作为分子生成模型,MGVAE 生成的分子在物理上(本研究中为 ClogP 和 CMR)与给定的数据集相似。同时,MGCVAE 也会在特定条件下产生与给定数据集物理相似的分子。MGVAE 和 MGCVAE 的目标函数如下:
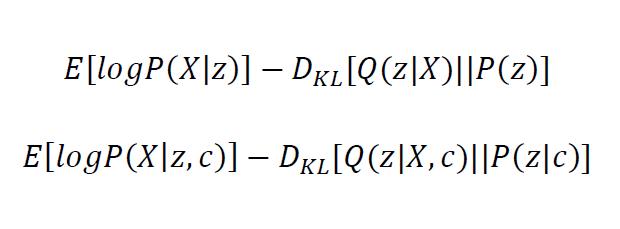
这两个模型的主要区别在于目标函数中的条件向量 𝑐 。在该研究中,要控制的分子特性对应于条件向量c(one-hot向量),解码器根据这些给定的条件向量,与潜在向量一起生成具有所需属性的分子。
MGCVAE 模型架构如图 2 所示,它会将分子图重构为初始图矩阵,并将条件向量一同输入编码器,编码器将其转换为潜在空间的向量。然后,潜在向量与条件向量经过解码器生成了新分子的初始图矩阵。由此,MGCVAE生成了具有“指定特性的新分子”。
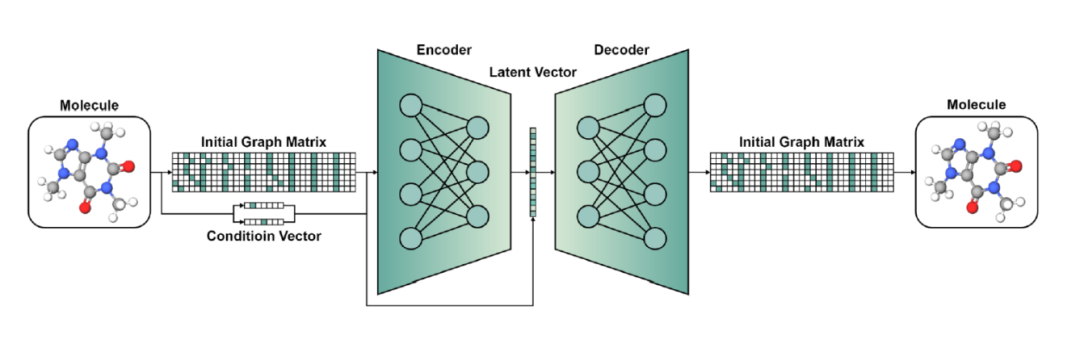
图2. MGCVAE 模型的架构
数据集 该研究从 ZINC 数据库中选择了 1363452 个具有 16 个或更少原子(节点)的分子,如图 3所示。这些分子由 12 种类型的原子(B、C、N、O、F、Si、P、S、Cl、Br、Sn 和 I)和4 种类型的键(单键、双键、三键和芳香键)组成。通过RDKit的计算方法计算后,这些分子的ClogP 介于 -6 和 5 之间,CMR在 5 到 95 之间(与分子的大小和分子量有关)。除此之外,该研究还从 ZINC 数据库中收集了适合图形生成的分子(例如,没有'+'、'-'和'.'的 SMILES)。
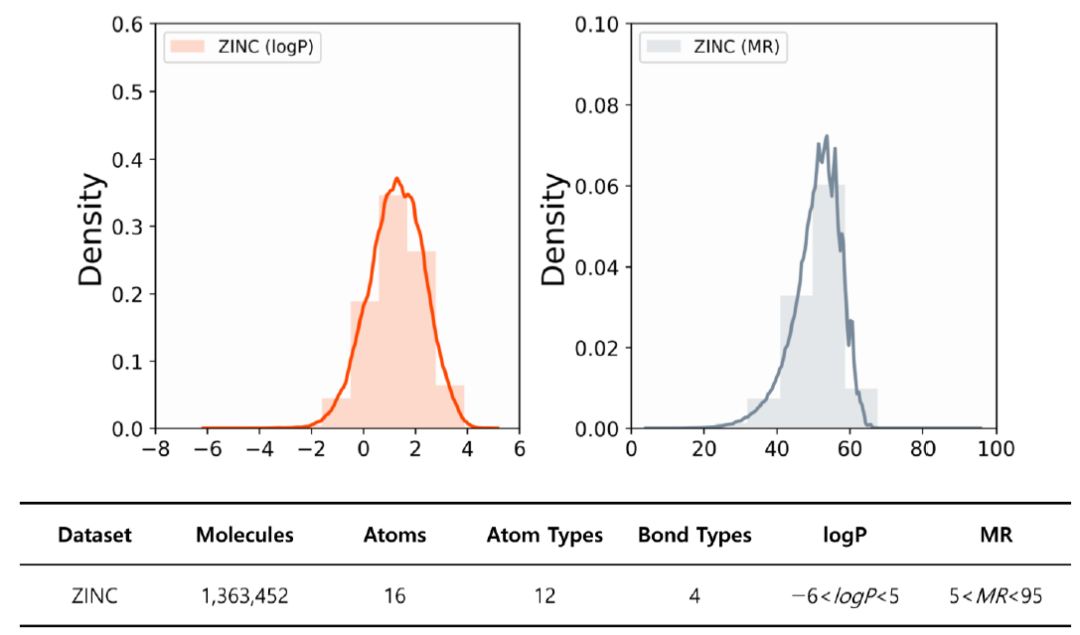
图3. ZINC 数据集中包含的分子的 ClogP 和 CMR 直方图以及分子的相关信息
根据 Lipinski's rule of five(RO5),本文将两个优化目标确认为生成ClogP 在 0-3 之间、CMR 在 20-60 之间的分子,因为这既是作为药物的有意义的范围,也是通过给定数据集的分布可以生成模型的范围。
3 结果和讨论 多目标优化 MGVAE 和 MGCVAE模型用相似的数据集进行训练,MGVAE 在没有任何约束条件的情况下生成了10000个分子,而 MGCVAE在第一个条件(ClogP, C1={0, 1, 2, 3})和第二个条件(CMR, C2={20, 30, 40, 50, 60})下,每种组合均生成10000个、共生成了200000个分子。
为了衡量多目标优化的效果,作者以“MGCVAE生成的分子中,满足两个目标特性的分子的比例”为基准对模型的性能进行评估。同时也对未应用任何条件的 MGVAE 生成的分子进行计数,以确定它们是否满足每个条件的范围。
性能的评估结果如表1所示,MGCVAE 在所有条件下均比 MGVAE 能产生更多优化的分子,MGCVAE的显著性能表明它更适用于生成具有两种所需特性药物分子。
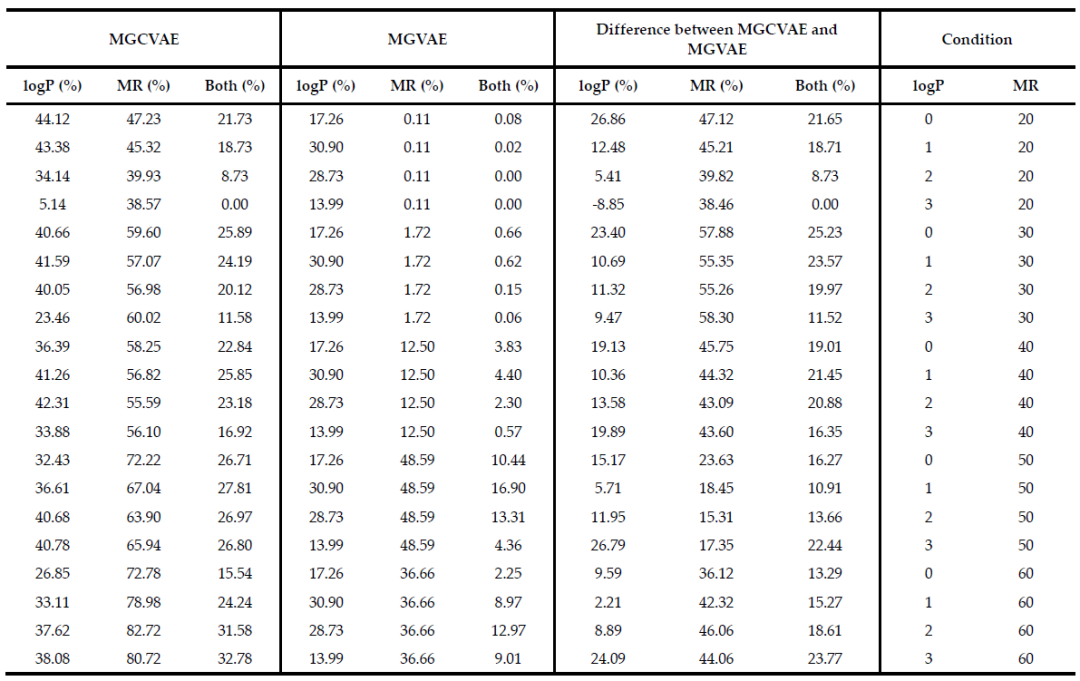
表1. 多目标优化结果。MGCVAE和MGVAE的结果与每个属性和同时满足两者的结果同时显示(每个结果都是四舍五入后与给定条件具有相同值的分子数的百分比)
分子空间的相似性 比较生成的分子和数据集中的分子的化学空间是一种直观地比较两者相似程度的方法。该研究利用了分子指纹和降维算法(PCA),对两类分子的相似性进行了可视化分析,如图 4 所示。它表明两种生成模型生成的分子都与现有的数据集相似,尤其是 MGCVAE,可以在特定位置生成更多的分子。
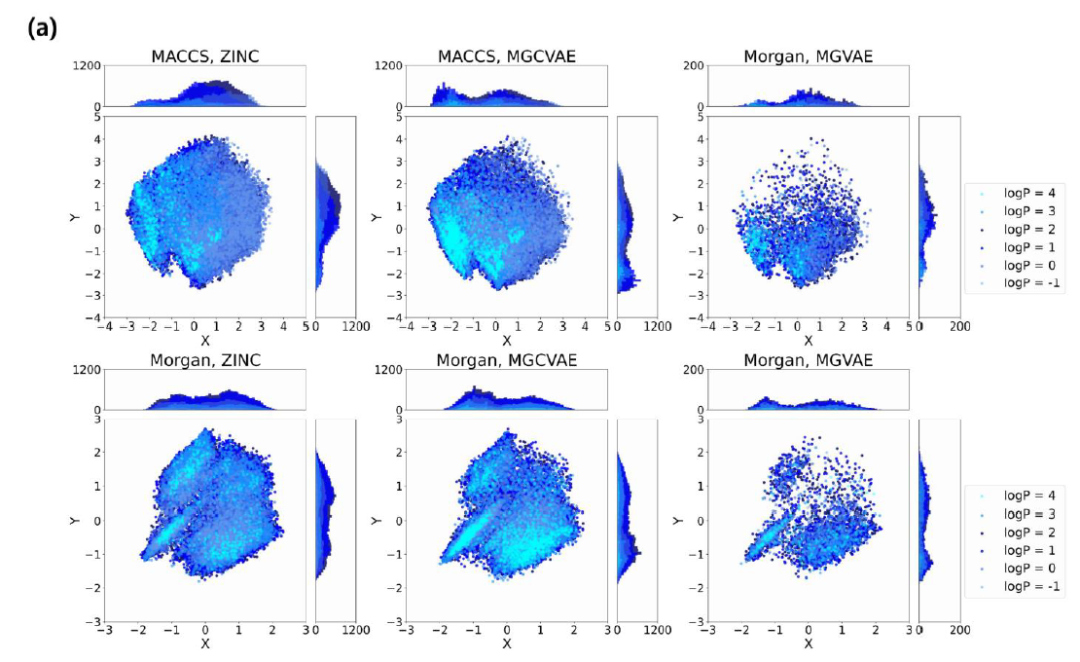
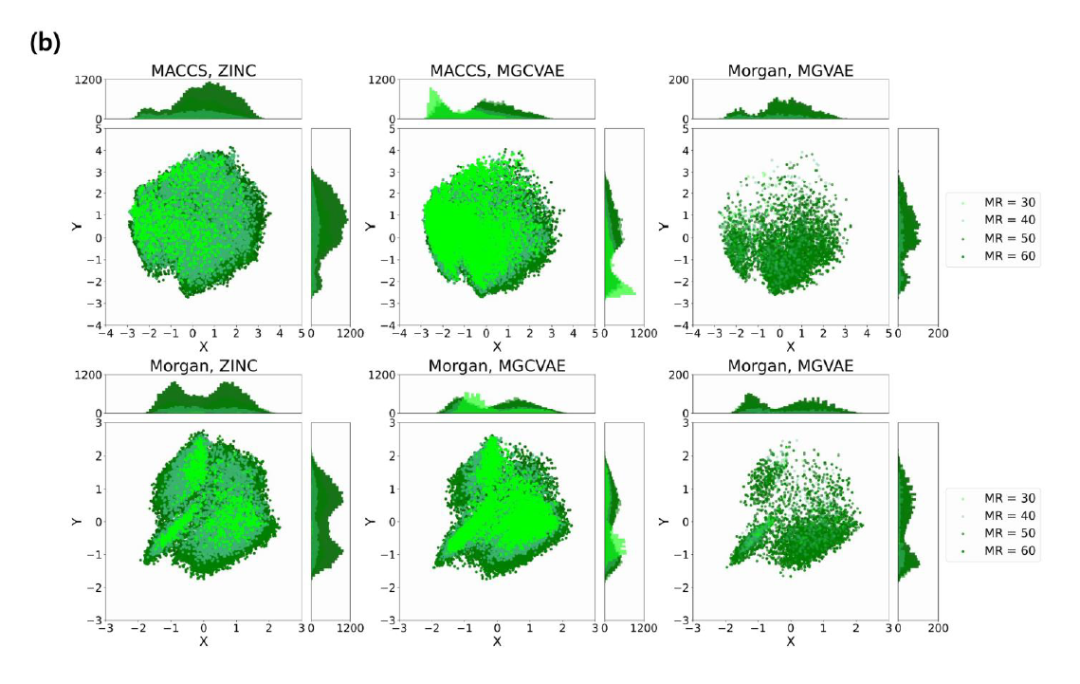
图4. 使用PCA对ZINC数据集和生成分子的MACCS和Morgan分子指纹分别进行二维可视化。以 ZINC 为基准,数据数量越大,颜色越深
模型性能评估 在特定数据集上训练的模型,其生成的分子化学空间是有限的。因此,为了准确评估 MGVAE 和MGCVAE的性能,有效性(有效分子的数量与所有生成的分子之比)、新颖性(不在数据集中的有效样本与有效样本总数之比)和独特性(独特样本数与有效样本数之比,它衡量抽样过程中的多样性程度)这三个要素都应该被衡量。如表 2所示,MGVAE的有效性、新颖性和独特性均获得满分,而MGCVAE只在独特性上略逊色于 MGVAE。
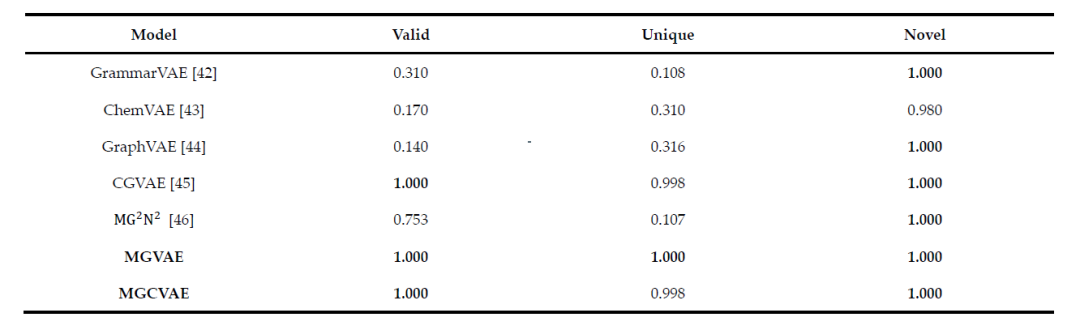
表2. 用于评估MGVAE、MGCVAE 等生成分子模型的有效性、独特性和新颖性
4 结论 在这项研究中,作者研究了MGVAE 和 MGCVAE 这两种基于图的分子生成模型,同时对MGCVAE进行了多目标优化。它通过将多个目标属性分配给该模型中的条件向量,以此来控制这些目标属性,从而让模型生成了具有所需特性(ClogP 和 CMR)的分子。将该模型的评估结果与 MGVAE 进行比较,当 ClogP 接近 3,CMR 接近 60 时, MGCVAE 生成了 32.78%的有效分子,而MGVAE 只生成了 9.01% 。因此,该研究中的模型有可能被应用于高效的从头开始的药物设计。最后,该研究的改进和未来工作包括:生成和验证适合于类药物分子的 20 个原子或更多原子的大分子,优化三个或更多的属性等。 参考资料 Lee, M. and K. Min (2022). "MGCVAE: Multi-Objective Inverse Design via Molecular Graph Conditional Variational Autoencoder." Journal of Chemical Information and Modeling 62(12): 2943-2950.
