
本周四,一年一度发布的《人工智能全景报告》(State of AI Report)发布了最新一期报告。 State of Report 至今已是第六个年头,成为了人工智能领域的风向标,它由业界和研究领域的领先人工智能从业者撰写,除了总结过去,也会对未来发展进行很多预测。
今年的报告汇总和聚焦了过去一年里 AI 行业中炙手可热的事件,援引数据来自知名科技公司和研究小组,由投资人 Nathan Benaich、Alex Chalmers、Othmane Sebbouh 和 Corina Gurau 编写。报告从研究进展、行业局势、现有政策、安全问题、未来预测五个维度出发,对最新的 AI 发展现状和未来预期进行了深度分析。

完整报告下载地址:https://docs.google.com/presentation/d/156WpBF_rGvf4Ecg19oM1fyR51g4FAmHV3Zs0WLukrLQ/edit?usp=sharing
报告称,OpenAI 的 GPT-4 在发布八个月后仍然是最强的大语言模型(LLM),「在经典基准测试和旨在评估人类的考试上都击败了所有其他大模型。」然而报告指出,随着尖端人工智能系统变得更加强大和灵活,比较它们会变得越来越困难。
与此同时,报告认为到 2023 年,人工智能公司公开分享其最先进研究的文化将结束。报告称,OpenAI 拒绝分享有关 GPT-4 系统架构的「任何有用信息」,谷歌和 Anthropic 对他们的模型也做出了类似的决定,「随着成本升高和对安全担忧的加剧,传统上开放的科技公司已经接受了对其最前沿研究不透明的文化。」
报告得出的主要结论如下:
1、研究进展
GPT-4 登场,展示了专有技术与次优开源替代方案之间的能力鸿沟,同时也验证了通过人类反馈进行强化学习的威力; * 在 LLaMa-1/2 的支持下,越来越多的人试图用更小的模型、更好的数据集、更长的上下文来克隆或击败专有模型; * 目前还不清楚人类生成的数据能维持人工智能扩展趋势多久(有人估计,到 2025 年,数据将被 LLM 耗尽),也不清楚添加合成数据会产生什么影响。企业中的视频和数据可能是下一个目标; * LLM 和扩散模型通过为分子生物学和药物发现带来新的突破,继续为生命科学界提供助力; * 多模态成为新的前沿,各种智能体热度大大增加。
2、行业局势
- 英伟达凭借各国、初创公司、大型科技公司和研究人员对其 GPU 的巨大需求,跻身市值万亿美元俱乐部;
- 主要芯片供应商开发了不受出口管制影响的替代产品;
- 在 ChatGPT 的带领下,GenAI 的应用程序在图像、视频、编码、语音或 CoPilots 等领域取得了突破性的进展,带动了 180 亿美元的风险投资和企业投资。
3、现有政策
世界已划分出明确的监管阵营,但全球治理的进展仍较为缓慢,最大的人工智能实验室正在填补这一空白; * 据预测,人工智能将影响一系列敏感领域,包括选举和就业,但我们还没有看到显著的影响。
4、安全问题
关于生存风险的讨论首次进入主流,并明显加剧; * 许多高性能的模型很容易「越狱」,为了解决 RLHF 的挑战,研究人员正在探索替代方案,例如自对齐(self-alignment)和带有人类偏好的预训练; * 随着模型性能的提升,一致地评估 SOTA 模型变得越来越困难。
以下是报告的具体内容。
研究进展
报告第一部分总结了 2023 年以来的人工智能技术突破及它们的能力。
OpenAI 推出 GPT-4,展示了专有和次优开源模型之间的能力差距,并在经典 AI 基准测试和为人类设计的考试中击败了所有其他的大型语言模型。
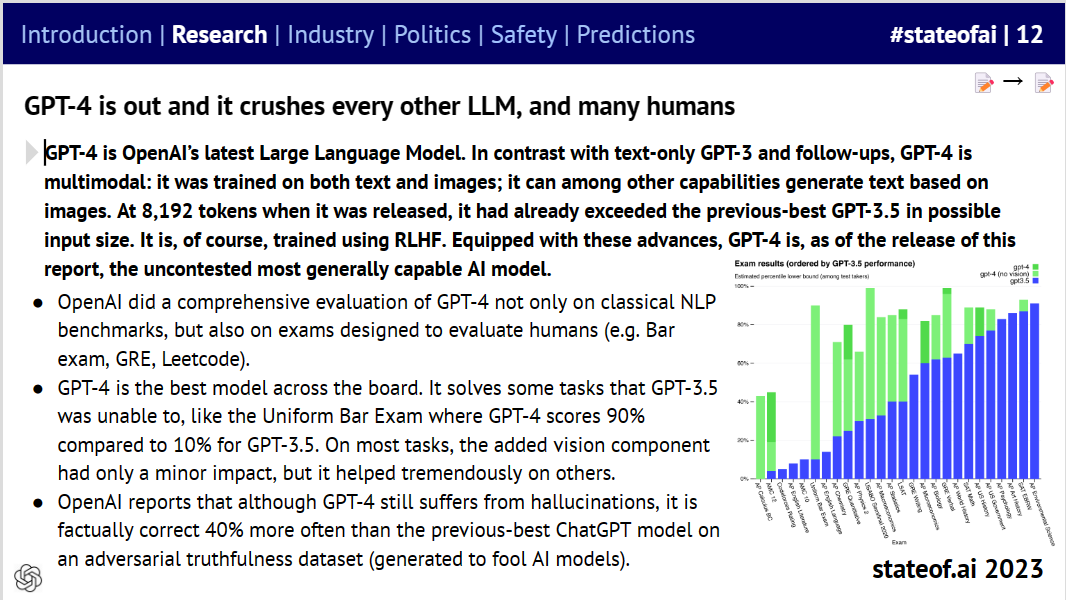
ChatGPT 等大模型的成功验证了基于人类反馈的强化学习(RLHF)的力量。业界也在积极寻找 RLHF 的可扩展替代解决方案,比如 Anthropic 提出了基于 AI 反馈的强化学习。

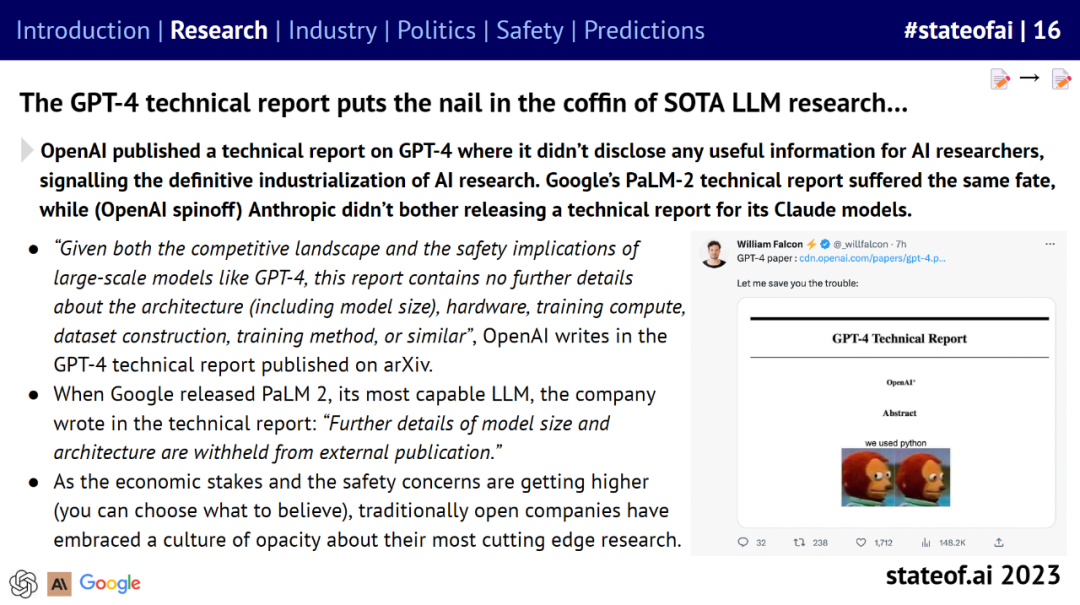
不过大模型厂商越来越趋于技术封闭。OpenAI 虽然发布了 GPT-4 的技术报告,但没有透露任何对 AI 研究人员有用的信息,这标志这 AI 研究的产业化。谷歌 PaLM-2 技术报告同样如此,Anthropic 更是选择不发布 Claude 技术报告。
直到 Meta 先后发布开源大模型 Llama、Llama2,选择向公众开放模型权重等技术细节,掀起了一场开放竞争的大语言模型竞赛,并形成了开源与专有大模型之间的抗衡。尤其是 Llama2 可以直接商用,2023 年 9 月,下载量达到了 3200 万。

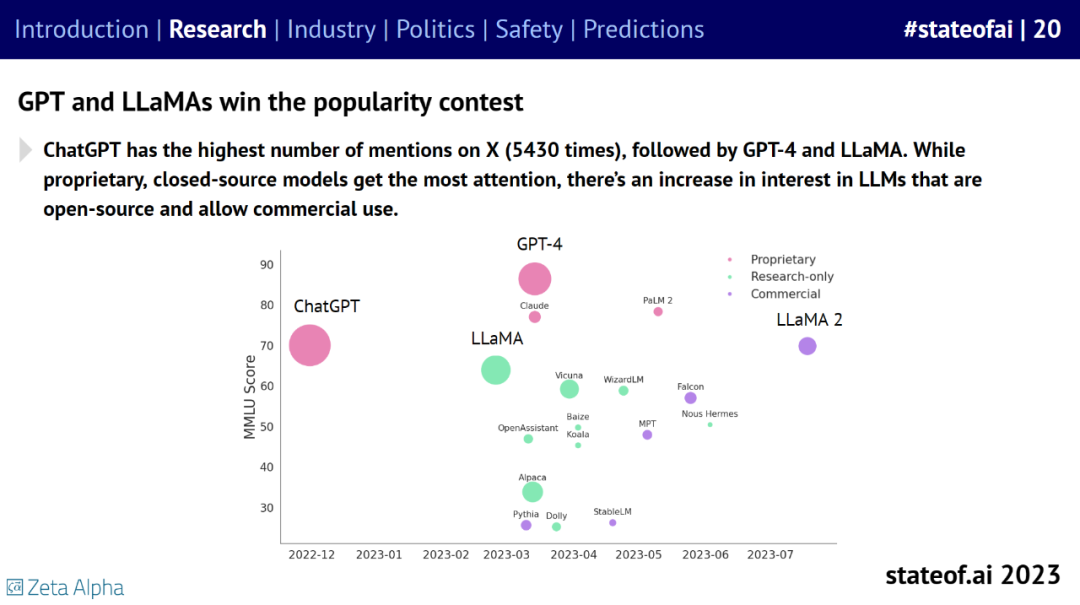
就流行度而言,ChatGPT 在 X(原推特)上被提及的次数最多,为 5430 次。其次是 GPT-4 和 LLaMA。虽然专有闭源模型最受关注,但人们对开源且允许商业用途的 LLM 的兴趣在增加。
基于 Llama 和 Llama2,业界不断努力通过开发更小的模型、更好的数据集和更长的上下文来实现媲美或超越专有模型的性能。
当使用非常专业和精心制作的数据集来训练小型语言模型时,性能可与大 50 倍的模型相当。上下文长度成为新的参数度量以及 AI 社区日益重视的研究主题。

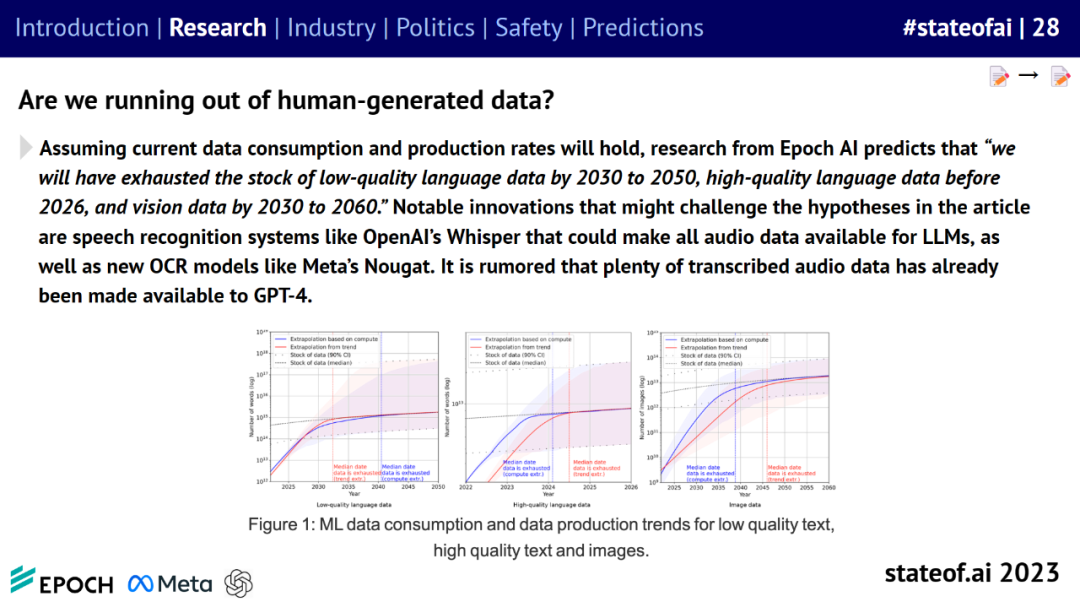
随着大语言模型的训练参数量和数据量不断增加,人们开始考虑人类产生的数据会有用完的一天吗?目前还不清楚这些数据能够维持 AI 扩展多久。
研究机构 Epoch AI 预测称,假设当前的数据消耗和生产率不变,到 2030 至 2050 年将耗尽低质量语言数据库存、2026 年前将耗尽高质量语言数据库存、到 2030 至 2060 年将耗尽视觉数据库存。
在这种情况下,AI 生成的内容可以用来扩大可用训练数据池。不过也有一些尚未明确的观点:合成数据虽然变得越来越有用,但有证据表明,在某些情况下,生成数据导致模型遗忘。
随着文本和图像生成模型变得越来越强大,识别 AI 生成的内容以及受版权保护来源的内容,这些问题将长期存在,并变得越来越难以解决。

LLM 和扩散模型为分子生物学和药物发现带来新突破。比如受到图像和语言生成模型成功的启发,扩散模型可以从头开始设计多种功能蛋白,为生命科学带来了更多可能。
此外还能做到:使用语言模型学习进化的蛋白质结构规则,无需基于细胞的实验可以预测扰动多个基因的结果、预测所有单一氨基酸变化结果等。

谷歌的 Med-PaLM 2 成为首个在 MedQA 测试集中达到专家水平的大模型,下一步将走向多模态。

AI for Science 逐渐兴起,其中,医药发展最快,但数学关注度最高。
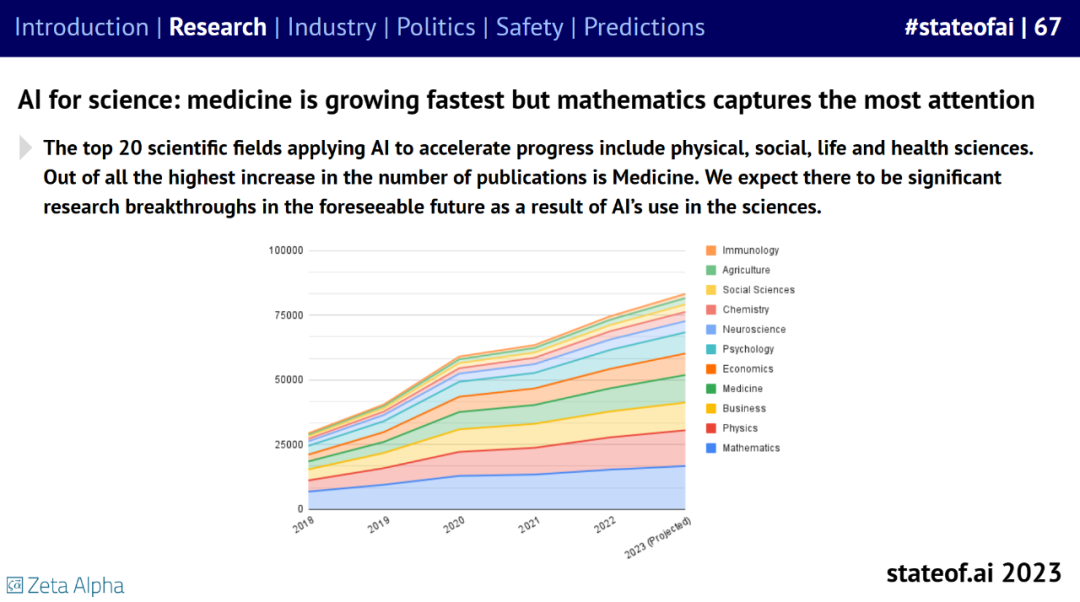
行业局势
报告第二部分总结了 AI 相关的行业发展趋势。
AI 尤其是大模型的发展意味着现在是进入硬件行业的好时机,GPU 巨大需求见证了英伟达盈利井喷,使之进入了 1T(万亿)市值俱乐部。
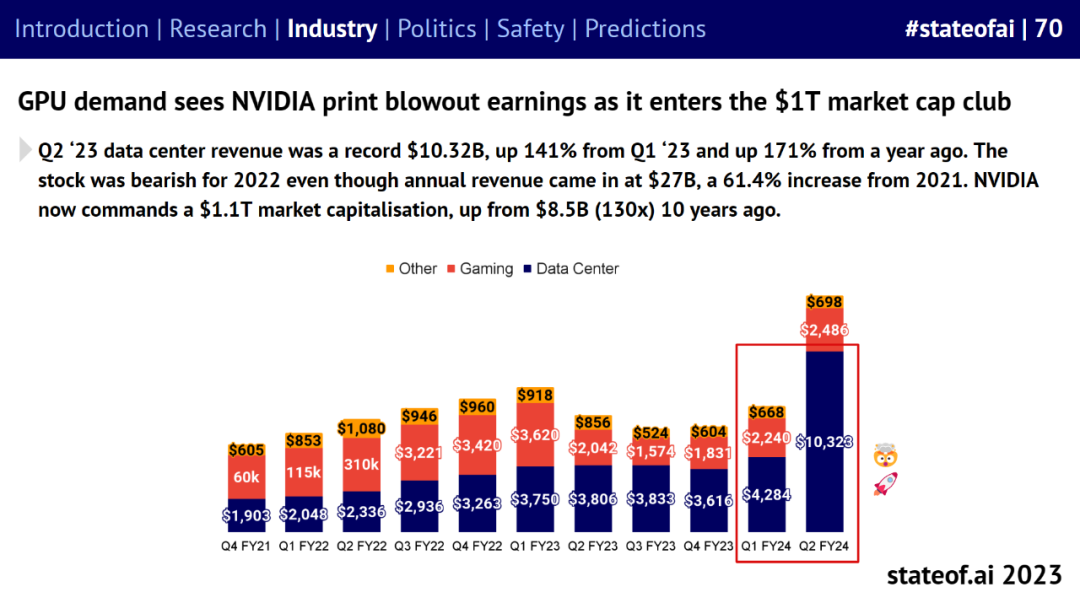
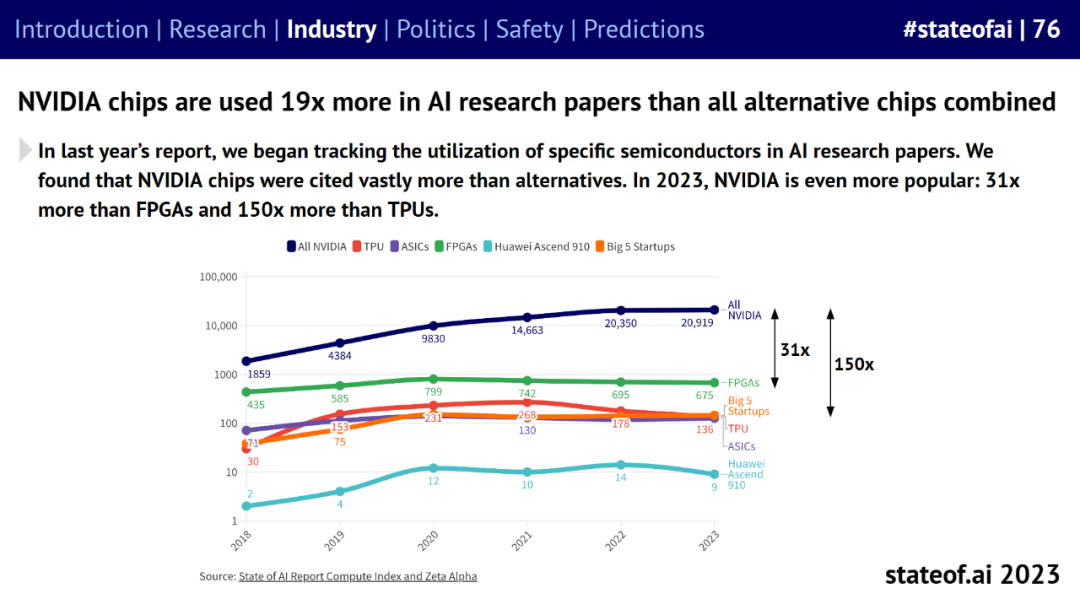
英伟达 A100、H100 GPU 集群的数量不断增加,其芯片使用量是 AI 研究论文中所有其他同类芯片总和的 19 倍。
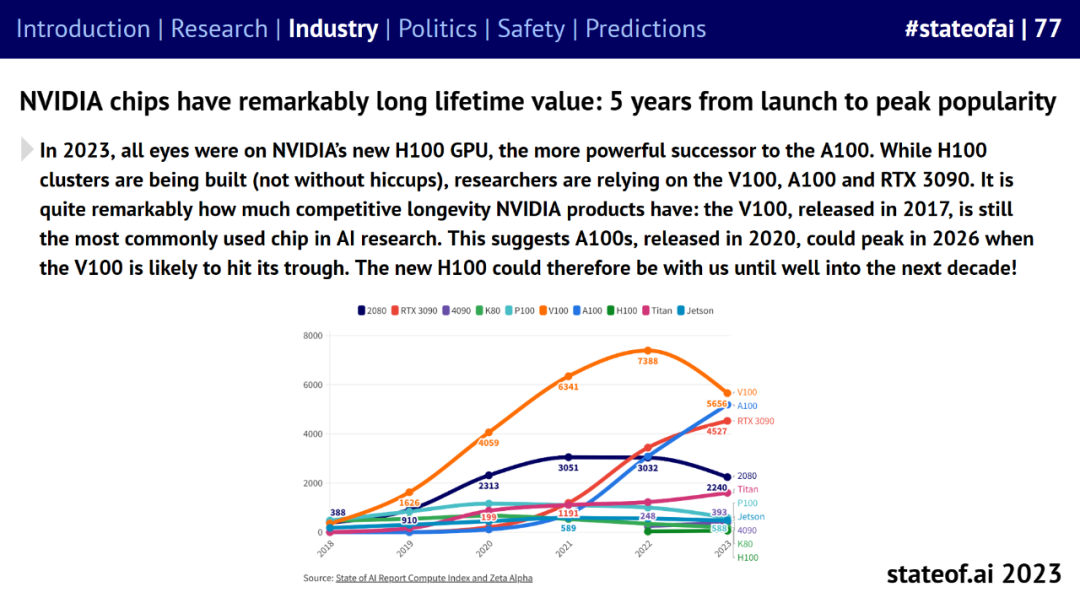
英伟达在持续推出新芯片的同时,旧 GPU 也表现出了非凡的生命周期。2017 年发布的 V100 是 2022 年 AI 研究论文中最受欢迎的 GPU。
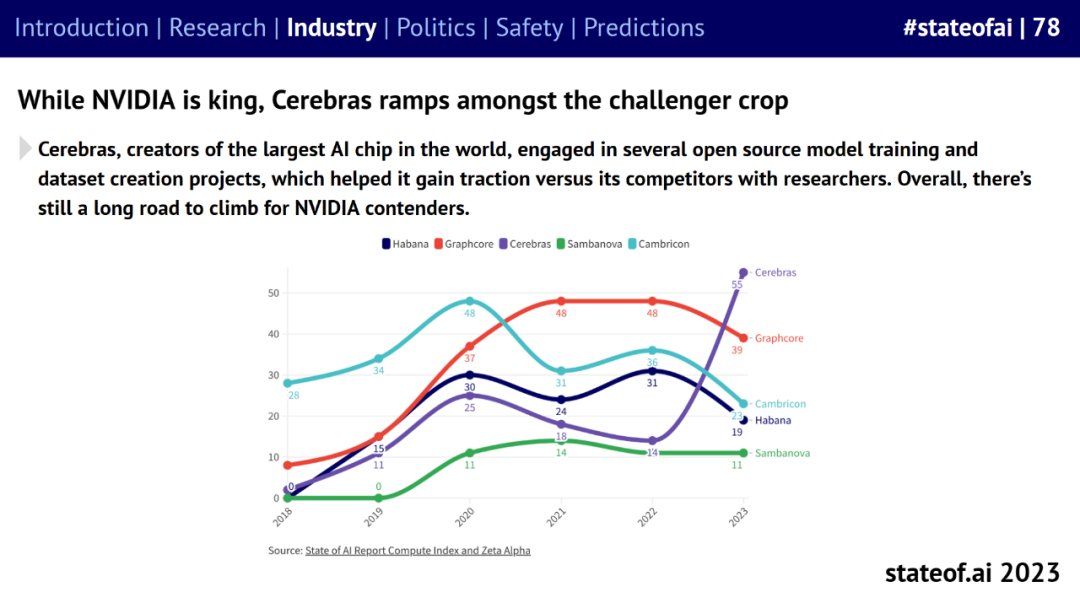
英伟达虽在 GPU 市场称王,但也迎来了很多挑战者,比如 Cerebras。
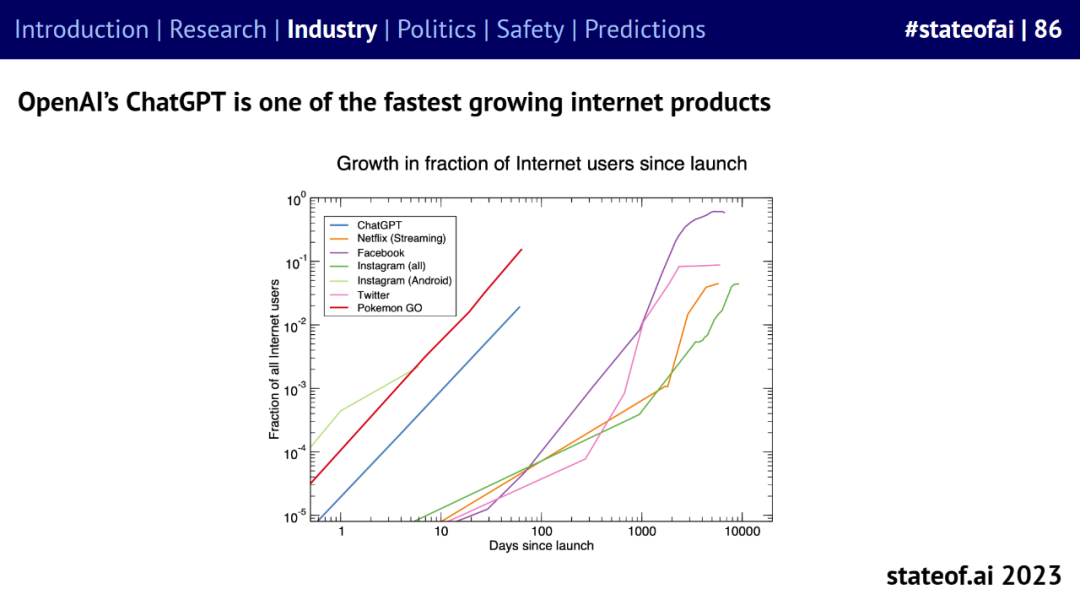
生成式 AI 迅速崛起,OpenAI 的 ChatGPT 成为增速最快的互联网产品之一。
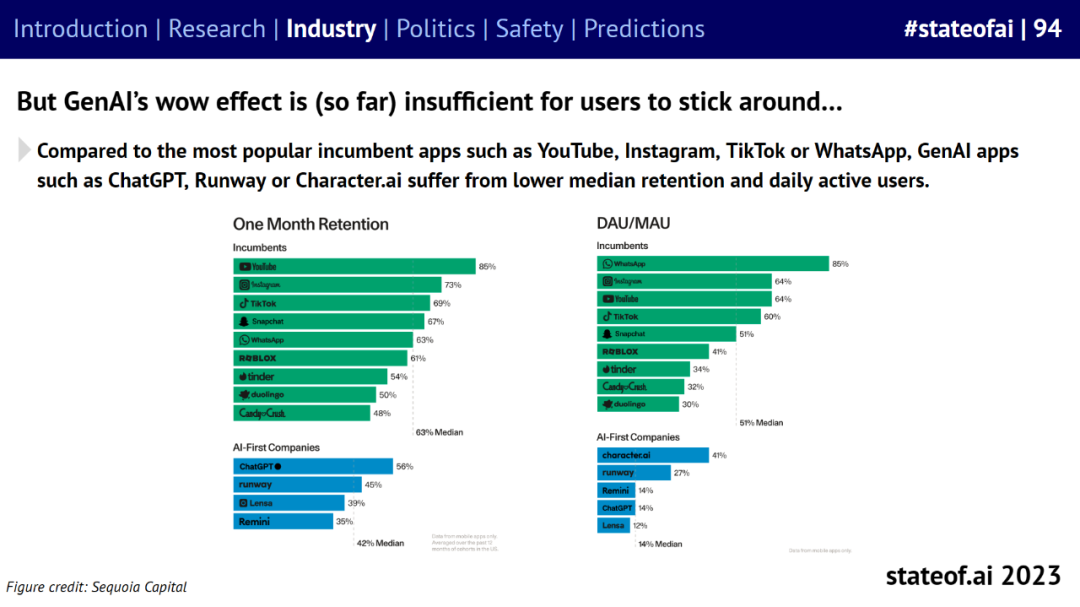
但是,与 YouTube、Instagram、TikTok 或 WhatsApp 等目前最受欢迎的应用程序相比,ChatGPT、Runway 或 Character.ai 等 GenAI 应用程序的中值留存率和每日活跃用户数较低。
在消费软件领域之外,有迹象表明 GenAI 可以加速实体 AI 领域的进步。比如自动驾驶领域,Wayve 推出了用于生成逼真驾驶场景的 AI 大模型 GAIA-1。

此外,谷歌和 DeepMind 合并为谷歌 DeepMind,谷歌《Attention is all you need》论文作者全部离职创业。


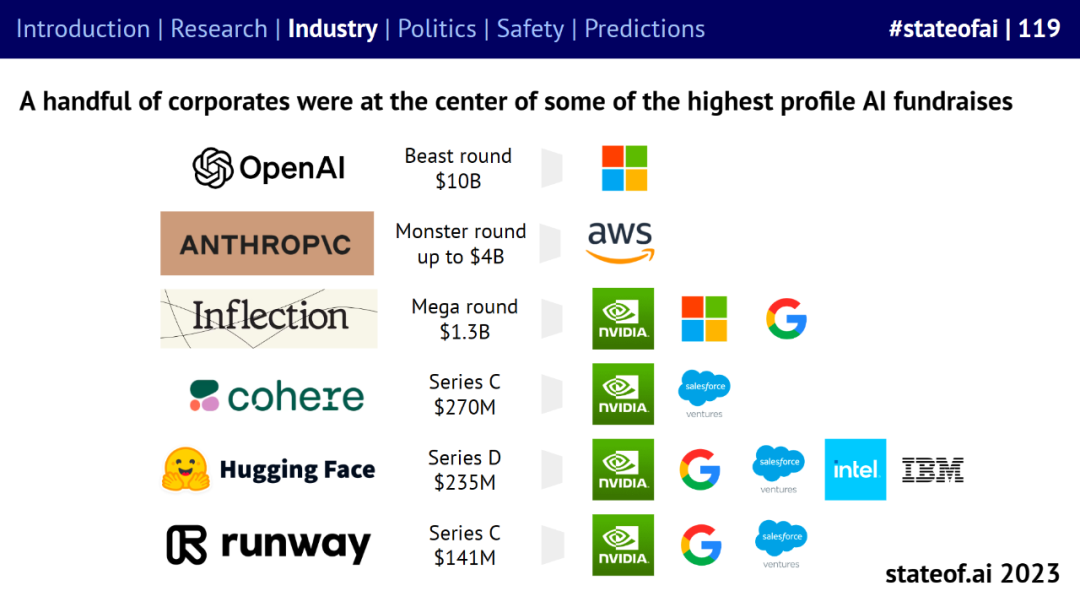
OpenAI、Anthropic 等 AI 企业正在成为大模型这波技术浪潮的中坚力量。GenAI 企业筹集的种子资金比所有初创企业多 33%,融资金额比所有初创企业多 130%。
现有政策
报告第三部分介绍了人工智能领域的政策制定情况。
不出所料,数十亿美元的投资和能力上的巨大飞跃已将人工智能置于政策制定者议程的首要位置。全球正围绕着少数几种监管方法展开 —— 从轻微监管到高度限制性的都有。

关于全球治理的潜在建议已经浮出水面。英国人工智能安全峰会可能会有助于开始将这种想法具体化。

安全问题
报告第四部分总结了 AI 领域讨论最多的安全问题。
之前的 State of AI 报告曾警告称,大型实验室忽视了安全问题。2023 年,关于 AI 风险的辩论集中爆发,尤其是「灭绝风险」或灾难性风险,关于这些话题的讨论经常占据头条。
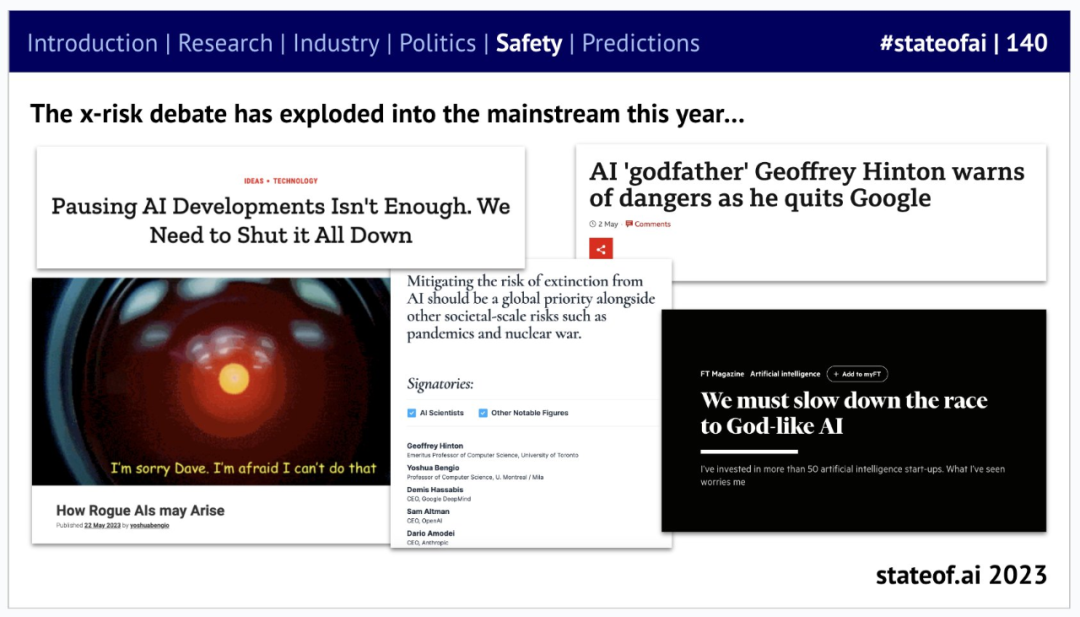
当然,并不是每个人都如此悲观,比如 Keras 作者、谷歌 AI 研究员 François Chollet 和图灵奖得主、Meta 首席 AI 科学家 Yann LeCun。Chollet 表示,「不存在任何可以带来人类灭绝风险的人工智能模型或技术…… 即使你根据 scaling law 将模型能力外推到未来也不会。」但风险投资家 Marc Andreessen 问道,「可测试的假设是什么?谁会证伪这个假设呢?」

不难看出,政策制定者对此感到震惊,并一直在努力积累关于潜在风险的知识。英国首先采取行动,成立了专门的前沿人工智能工作组,美国则启动了国会调查。

在此环境下,大型实验室也在积极采取措施,比如 DeepMind 和 Anthropic 都公布了相应的安全工具,以评估模型的安全风险。与此同时,存在更大滥用风险的开源模型也备受关注,因此 Meta 等发布开源大模型的公司也在积极采取措施。
十大预测
在报告的最后一部分,作者给出了他们对于未来一年 AI 发展趋势的一些预测:
一部好莱坞级别的电影将使用生成式人工智能制作视觉效果; * 一家生成式人工智能媒体公司因在 2024 年美国大选中滥用人工智能而受到调查; * 可以自我改进的 AI 智能体在复杂环境(如 AAA 游戏、工具使用、科学)中击败 SOTA; * 科技 IPO 市场解冻,至少有一家专注于人工智能的公司上市(如 Databricks); * 在 GenAI 扩展热潮中,一个集团花费超过 10 亿美元来训练一个大型模型; * 美国联邦贸易委员会(FTC)或英国竞争和市场管理局(CMA)以竞争为由调查微软与 OpenAI 的交易; * 除了高级别自愿承诺之外,作者认为全球人工智能治理将进展有限; * 金融机构推出 GPU 债务基金,以取代用于计算融资的风险投资股权资金; * 人工智能生成的歌曲进入 Billboard Hot 100 前 10 名或 Spotify Top Hits 2024; * 随着推理工作量和成本的大幅增长,一家大型人工智能公司(如 OpenAI)将收购一家专注于推理的人工智能芯片公司。
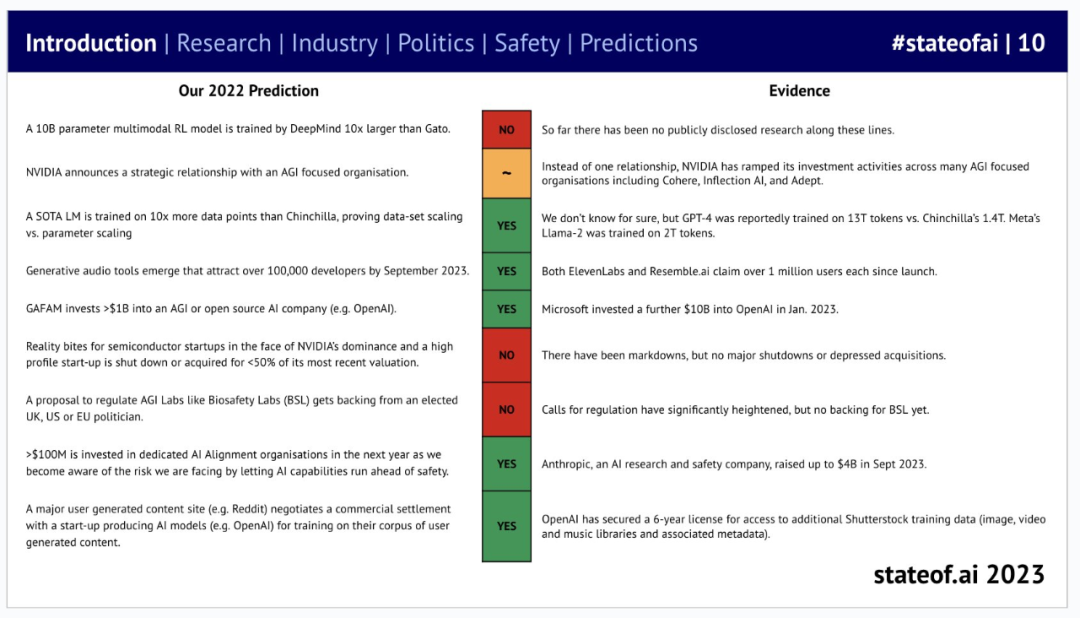
当然,这些预测并不一定完全正确。去年,他们也给出了一些预测(9 个),并在今年的报告中公布了针对这些预测的评估:其中 5 个被证明是准确的。
那么,今年有几个预测能应验让我们拭目以待。 参考链接: https://twitter.com/nathanbenaich/status/1712358033194688701 https://www.stateof.ai/

