MiniMax 开源了最新的基础语言模型 MiniMax-Text-01 和视觉多模态模型 MiniMax-VL-01。 新模型的最大亮点是,在业内首次大规模实现了新的线性注意力机制,这使得输入的上下文窗口大大变长:一次可处理 400 万 token,是其他模型的 20-32 倍。 他们相信,这些模型能够给接下来一年潜在 Agent 相关应用的爆发做出贡献。 为什么这项工作对于 Agent 如此重要? 随着 Agent 进入应用场景,无论是单个 Agent 工作时产生的记忆,还是多个 Agent 协作所产生的 context,都会对模型的长上下文窗口提出更多需求。

我们推出了MiniMax-01系列,包括MiniMax-Text-01和MiniMax-VL-01,它们与顶级模型相媲美,同时在处理更长上下文方面具有更强的能力。其核心在于闪电注意力机制及其高效的扩展性。为了最大化计算能力,我们将其与专家混合(Mixture of Experts, MoE)相结合,创建了一个拥有32个专家、总参数量达到4560亿的模型,其中每个token激活的参数为45.9亿。我们为MoE和闪电注意力开发了优化的并行策略以及高效的计算-通信重叠技术。这一方法使我们能够在具有数百亿参数的模型上进行高效训练和推理,同时处理跨越数百万token的上下文。MiniMax-Text-01的上下文窗口在训练时可达到100万个token,在推理时能够扩展到400万个token,且成本可控。我们的视觉-语言模型MiniMax-VL-01是通过继续使用5120亿个视觉-语言token进行训练构建的。在标准和自定义基准测试中的实验结果表明,我们的模型在性能上与最先进的模型如GPT-4o和Claude-3.5-Sonnet相匹敌,同时提供了20到32倍更长的上下文窗口。我们将MiniMax-01公开发布,网址为:https://github.com/MiniMax-AI。
- 开源地址:https://github.com/MiniMax-AI
- Hugging Face:https://huggingface.co/MiniMaxAI
- 技术报告:https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
- 网页端:https://www.hailuo.ai
- API:https://www.minimaxi.com/platform
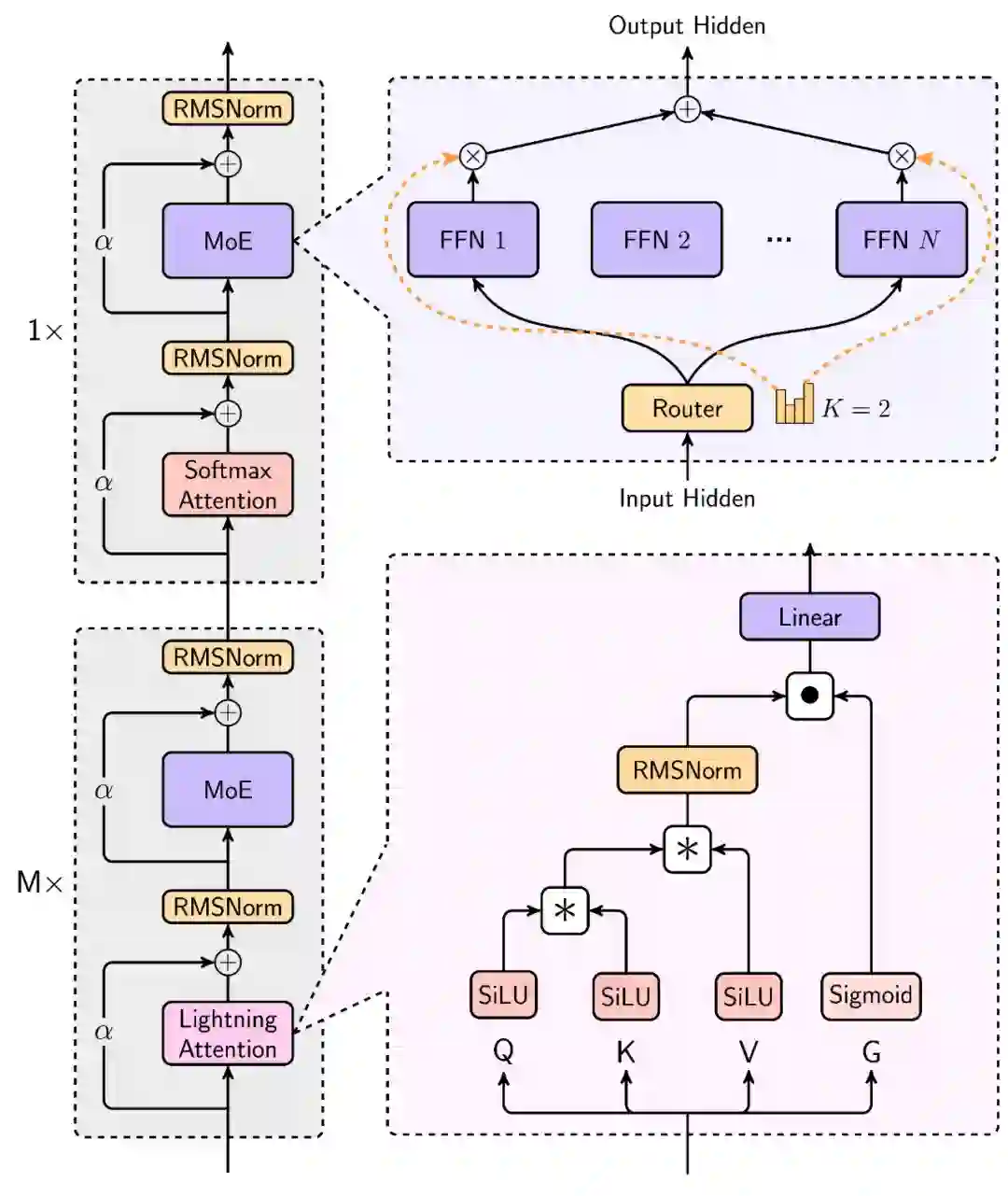
MiniMax-Text-01 究竟是如何炼成的?事实上,他们为此进行了一系列创新。从新型线性注意力到改进版混合专家架构,再到并行策略和通信技术的优化,MiniMax 解决了大模型在面对超长上下文时的多项效果与效率痛点。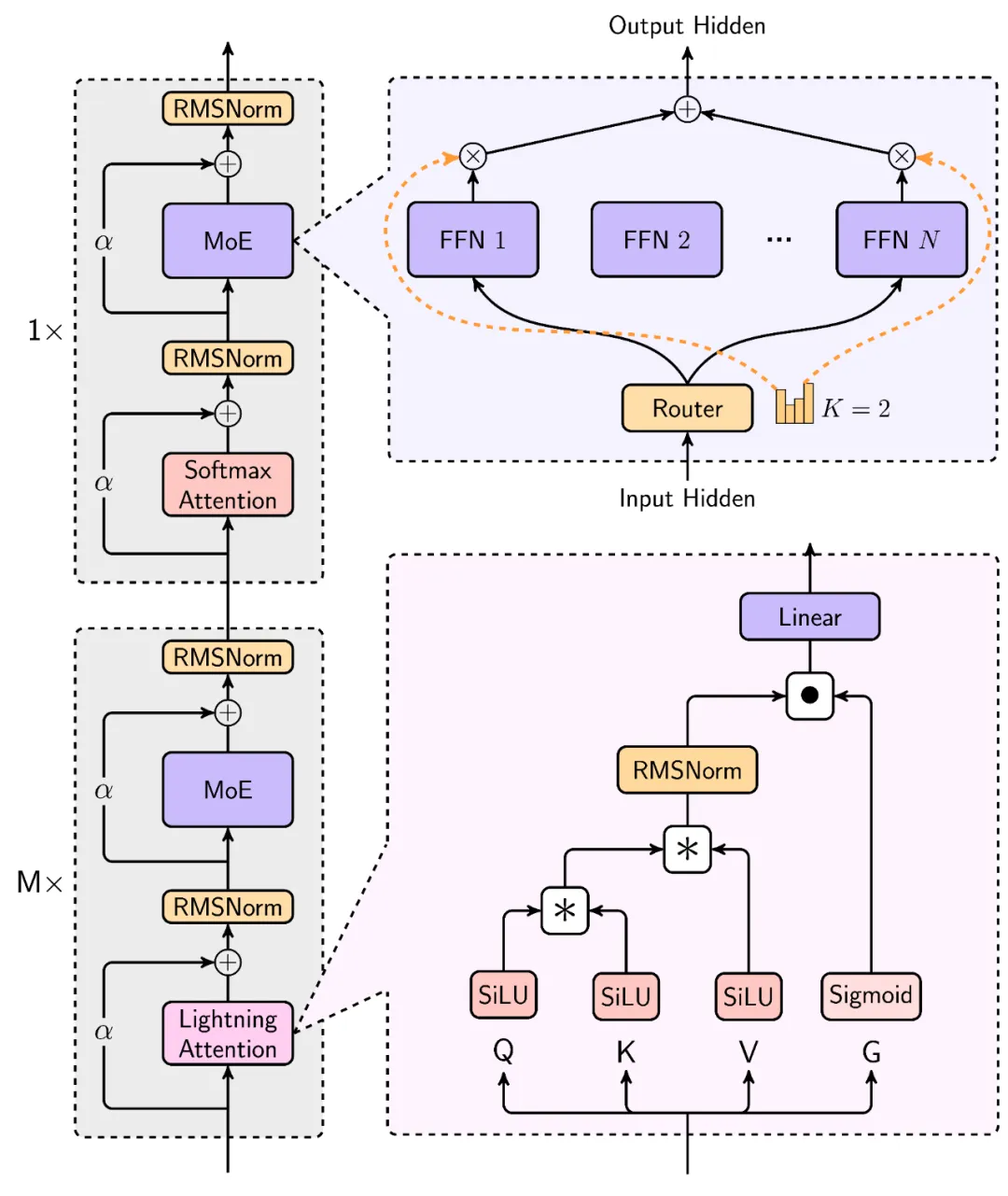
在 MiniMax-01系列模型中,我们做了大胆创新:首次大规模实现线性注意力机制**,传统Transformer架构不再是唯一的选择**。这个模型的参数量高达4560亿,其中单次激活459亿。模型综合性能比肩海外顶尖模型,同时能够高效处理**全球最长400万token**的上下文,是GPT-4o的32倍,Claude-3.5-Sonnet的20倍。超长上下文、开启Agent时代
我们相信2025年会是Agent高速发展的一年,不管是单Agent的系统需要持续的记忆,还是多Agent的系统中Agent之间大量的相互通信,都需要越来越长的上下文。在这个模型中,我们走出了第一步,并希望使用这个架构持续建立复杂Agent所需的基础能力。 极致性价比、不断创新
****受益于架构的创新、效率的优化、集群训推一体的设计以及我们内部大量并发算力复用,我们得以用业内最低的价格区间提供文本和多模态理解的API,标准定价是输入token 1元/百万token,输出token 8元/百万token。欢迎大家在MiniMax开放平台体验、使用。MiniMax开放平台:https://www.minimaxi.com/platformMiniMax开放平台海外版:
https://www.minimaxi.com/en/platformMiniMax-01系列模型在https://github.com/MiniMax-AI开源,后续也会持续更新。