

摘要
近年来,得益于神经网络技术特别是注意力深度学习模型的突破,自然语言处理取得了许多令人瞩目的成就。然而,自动化的法律文字处理仍然是自然语言处理的一个困难分支。法律句子通常很长并且包含复杂的法律术语。因此,适用于一般文件的模型在处理法律文件时仍然面临挑战。我们已经通过我们在这项工作中的实验验证了这个问题的存在。在本论文中,我们选择性地介绍了在自动法律文件处理中改进注意力神经网络的主要成果。语言模型往往会变得越来越大,但是,如果没有专家知识,这些模型仍然可能无法适应领域,尤其是对于法律等专业领域。
本论文的三个主要任务是实现改进法律文件处理中注意力模型。首先,我们调查并验证了在法律等特定领域运行时影响模型性能的因素。这项调查旨在为改进该领域的模型提供更清晰的见解。其次,由于预训练语言模型是最近自然语言处理中最众所周知的专注方法,我们提供了创建特定于法律领域的语言模型方法,从而在可靠的数据集上产生最先进的结果。这些模型建立在法律文件数据的特征之上,旨在克服我们之前调查中发现的挑战。第三,除了让模型完全从原始数据中学习的方法外,我们提出并证明了使用不同的知识源以不同的方式注入模型以调整其输出的有效性。这种方法不仅增加了可解释性,还允许人类控制预训练的语言模型,并利用该领域发展过程中可用的知识资源,如词汇、语法、逻辑和法律。
关键词:法律文本处理、注意力神经网络、深度法律、预训练语言模型、知识注入
第1章 引言
1.1 引言
法律文件的自动化处理是当今信息社会的迫切需求。除了社交媒体的便利性,我们在这些平台上的行为可能涉及或导致许多法律效力。Twitter禁止美国前总统唐纳德·特朗普在其平台[57]上发表言论,以及特斯拉不得不雇佣员工来控制其董事长埃隆·马斯克言论的法律风险,这些都是证明这一现象的典型例子。然而,由于社会和技术原因,自动法律处理系统的质量尚未满足社会需求。
就社会原因而言,计算机科学是近几年才取得显著成果,而法律是国家建国以来数百年来一直依附于人们的领域。规律与人类的发展并存,是长期存在的,对技术没有任何关联。此外,法律和计算机科学都是没有太多共同点的专业学科。因此,计算机科学在法律上的应用可能需要很长时间才能取得突破。
由于技术原因,句子通常很长并且具有复杂的语义结构。人类甚至很难在一读时理解法律句子的确切含义。在英国、美国、加拿大等国家,法院必须在普通法体系中发挥解释作用;德国、日本、越南等国民法系需要的指导性文件。此外,法律文件是用自然语言编写的,这种交流方式并非旨在确保正确性。自然语言中的歧义可能成为任何智能系统的障碍,甚至对人类也是如此。尤其是在具有多层含义的语言中(如汉语、日语、越南语),通过句子理解确切的含义是一个更困难的问题。此外,法律领域使用的词汇与人们日常交流的词汇并不完全一致。因此,它可以被认为是我们语言中的一种特殊子语言。
随着硬件计算能力的增长,深度学习,尤其是注意力模型已经在自然语言处理的许多不同任务中证明了它们的能力。使用这种方法的系统可以很好地执行诸如语音识别、问答和语言生成等精细任务。鉴于这些成就,我们可以期待使用深度学习模型来处理法律领域中更复杂的语言任务。在本论文中,我们选择性地报告了我们在提高深度学习的性能和可解释性方面的研究成果,特别是在处理法律文本中的注意力模型(我们简称为深度法律处理)。由于法律语言不同于日常语言,因此我们需要对此类数据采取适当的方法。除了性能的提高,论文还为读者提供了深度法律处理的信息特征。
迁移学习和预训练的注意力模型是领域适应的鲁棒方法。然而,在法律等专业领域,如果不了解领域和数据,这些模型很难产生好的结果。因此,详细研究将深度学习应用于法律文本处理的可能性和方法对于该领域自动化的发展是有用的信息。本论文将回答的三个主要研究问题包括:
1.哪些因素会影响仅使用提供数据训练的端到端深度学习模型执行法律文件处理任务的性能?
2.预训练语言模型已成为深度学习的强大方法之一。法律文本中的哪些特征可用于实施这些模式的成功实例?
3.如何利用现有的知识源注入深度学习模型以获得更好的性能?可以获得哪些知识?
为了回答这些问题,我们做出假设并在特定问题中进行测试。对于每个问题,我们提出方法、进行实验、观察、分析实验结果并得出结论。
1.2 动机
1.2.1 深层法律制度的因素分析
本研究的第一个动机是了解影响深层法律制度的因素,并在这些理解的基础上提出适当的改进。开展本论文中介绍的工作,我们专注于提高深度法律模型的性能和显性。深度学习模型通常被认为是黑箱,只要有足够的数据,它们就会达到预期的效果。即便如此,在日常生活的所有领域都很难满足足够数据的假设。因此,分析深度法律的特征有助于我们更有效地使用数据。本论文还传达了有关深度学习模型在法律领域可以执行哪些任务以及在什么条件下表现良好的信息。这项工作也可以被视为提高深度法律模型的可解释性的努力,这对于将这些模型带入现实生活中的应用至关重要。
了解可能影响域中系统的因素是良好设计的重要要求。法律领域的数据特征是数据碎片化、法律句子长、专业术语多。因此,我们选择详细研究数据量、数据表示方式以及处理数据的模型架构等因素。对于数据量因素,我们在数据有限的问题上进行实验,提出增加数据的解决方案,并在新环境中比较结果。为了理解数据表示的影响,我们提出了一种方法来评估一般和法律领域中的不同嵌入方法。关于模型架构,我们比较了不同架构在同一个问题上的表现。实验结果表明,与具有普通架构的预训练繁琐语言模型相比,注意力CNN 网络具有明显的优势。
1.2.2 用于深度法律处理的预训练语言模型
我们的第二个动机是验证预训练语言模型在法律领域的能力。近年来,预训练语言模型得到了普及,并在自然语言处理的各种问题上取得了许多突破。顺应这一趋势,我们为深度法律任务设计了预训练的语言模型。除了性能(评估模型的重要因素)之外,我们在设计模型时还关注哲学。引入的模型是从影响我们调查的深度法律模型的因素中得出的观察结果。预训练的语言模型通常包含训练数据中存在的偏差,因此通常在非常不同的领域表现不佳。幸运的是,对于法律领域,我们可以利用该领域的数据属性来训练或调整这些模型的权重。
从观察数据表示在法律领域的重要性出发,我们提出了一种名为 BERTLaw 的预训练语言模型,该模型使用大量法律数据从头开始训练。除了在我们的实验中取得了很好的结果外,这个模型还帮助我们确认了数据表示的重要性。拥有良好的数据表示是强大的深层法律体系的先决条件。除了 BERTLaw 之外,我们还引入了 Paralaw 和 Paraformer,这些模型基于预训练的语言模型,克服了数据量和模型架构限制的问题。
1.2.3 深度法律模型的知识注入
我们的第三个动机是执行和利用法律和语言知识资源来提高深度法律模型的性能。深度学习模型可以从数据中学习并在广泛的任务中展示其有效性。但是,仅依靠数据具有三个缺点。首先,模型的质量取决于数据的质量。当非专业用户过于依赖数据时,这可能很危险。其次,人类将不太可能参与决策过程。这可能导致智能系统滥用权力。第三,这些系统被认为是黑盒,调试它们非常困难。因此,我们研究并提出将知识注入深度学习模型的方法,以指导这些模型的学习和生成过程。
对于语言知识,我们介绍了 HYDRA,这是一种架构,允许单独训练 Transformer 模型的注意力头,然后将它们移植到原始身体上。这种方法可以提高培训和存储的成本效益。对于法律知识,我们尝试了解法律句子的逻辑部分。我们使用一种特殊的机制将这些知识注入到 Transformer 模型的不同层中。最后,利用法律领域的语言生成模型,我们提出了一种利用公平知识来规范该系统输出的方法。这些发现是使用其他类型的知识资源来改进未来的深度法律模型的基础。
1.3 贡献
论文主要有三个价值:性能改进、方法论、理论。首先,本论文中提出的系统都比现有成果具有更好的性能。其中一些在可靠的数据集上取得了最先进的结果。其次,系统的性能改进都是基于对实验结果的观察而设计的方法。我们不仅解释了每章中提出的方法,还概述了构建它们的过程。第三,本论文各部分的结论和讨论对于深度法律模型的设计具有理论基础价值。
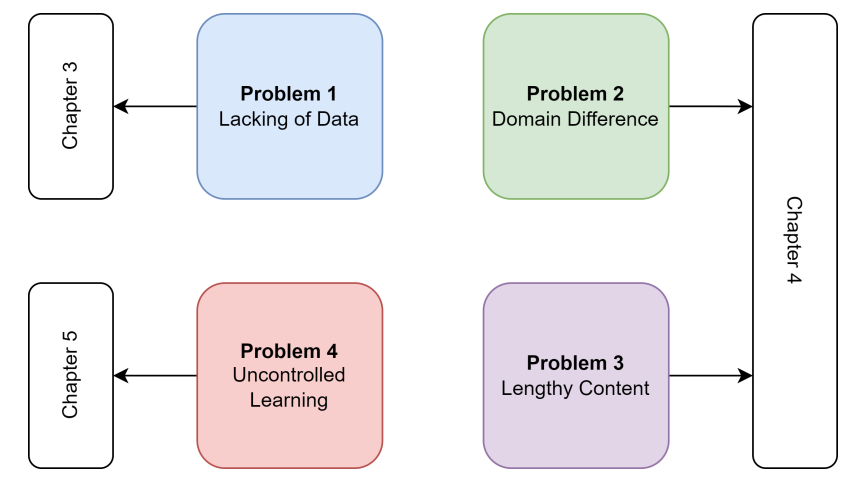
图1.1:论文中提到、分析和解决的主要问题。
论文的主要贡献包括发现和解决了法律领域深度学习系统的4个常见问题,即数据缺失、领域差异、内容冗长和学习不受控制,如图1.1所示。除了非架构解决方案外,本文提出的模型都利用了注意力机制。论文还表明,如果没有适当的方法,注意力模型的力量可能会被浪费。这在注意力CNN、预训练语言模型和 Paraformer 部分中得到了特别证明。
为此,我们提供了有关法律文本处理中注意力神经网络的定性和定量信息。我们提出了不同的方法来利用法律文本和补充知识的特征,不仅可以提高这些模型的性能,还可以提高它们的可解释性。此外,我们提出了定制神经网络中注意力架构的方法,以实现更好的设计。通过对注意力网络不同程度的干预以注入专家知识的详细解释,本论文也可以作为一个很好的技术参考文档,供可能关注的人参考。
这项研究可能有助于科学和实践意义。论文在其内容中提供了深度学习在法律文本处理和相关方面的全貌。此外,本文还将介绍每个深度学习模型中最重要的嵌入方法、训练任务和架构设计。从实践的角度来看,这项研究的结果可能有助于将深度学习中最先进的技术引入法律领域。本文档对于在法律领域寻求深度学习模型的可解释性但不仅将其用作黑盒的研究人员非常有用。可解释性是深层法律制度被批准在现实生活中运作的先决条件。
1.4 论文大纲
本论文的目的是分析和改进当前使用深度学习模型处理法律文件的最新技术。首先,我们分析了将端到端深度学习模型应用于法律处理问题的不同方面。通过这样做,我们获得了清晰的洞察力,可以为每个特定条件设计有效的模型。其次,我们提出了在法律领域预训练语言模型以提高其性能的新方法。第三,我们设计了使用专家知识来支持模型在法律领域进行更好的学习和预测的方法。
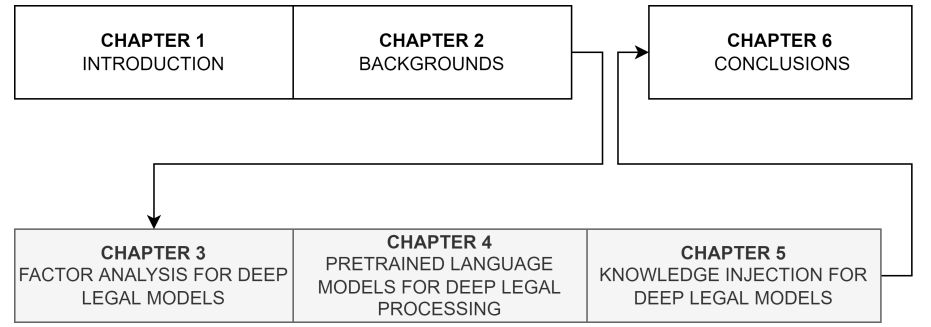
图 1.2:论文大纲
论文的大纲如图 1.2 所示。首先,我们要确认深度学习模型执行法律任务的能力,这通常需要专业知识。我们分析了数据表示、数据量和深度学习模型架构的影响。这一确认是探索深度法律处理知识的第一步。之后,我们进一步发现法律数据的哪些特征可用于预训练强法律语言模型,这是最近在自然语言处理中取得许多良好成果的多头注意力网络家族。在回答这个问题时,会涉及到法律嵌入、法律多语言能力和法律结构表示。最后,我们研究了将知识注入神经网络以获得该领域模型的性能和可解释性的可能性。研究语言知识、法律知识和自学知识来回答这个问题。
在回答研究问题之前,我们在第 1 章专门介绍了研究目标、挑战以及我们进行这项研究的动机,第 2 章介绍了深度学习、注意力机制和多头注意力模型的基本知识[62]。在撰写本文时,这些技术具有很大的影响力。这些知识不仅为读者阅读下一章提供了基础,而且有助于阐明研究的背景。这些技术将来可能会过时并被取代。但是,论文的哲学和方法论仍然具有参考价值。此外,我们还介绍了法律文件的特点、法律文件与日常文本的区别、挑战和深度学习处理法律文件的优势。
第 3 章回答了第一个研究问题。我们详细研究了影响深度学习模型的因素,例如数据表示、数据量和模型架构。在我们对深度学习架构的研究中,我们发现了非常简单的架构,例如 SCNN [44],它的参数数量很少,仍然可以胜过其他模型。有趣的是,我们还发现 CNN [35] 架构和注意力机制 [33] 的简单组合在某些特定情况下可以提供比庞大模型更好的结果。本章将回答端到端模型在什么条件下可以在法律文本处理任务中表现良好的问题。
下一个研究问题将在第 4 章中回答。近年来,语言模型已成为深度学习中的一种强大方法。这些模型经过大量数据的预训练,能够理解语言并在基准数据中的任务上表现出色。与传统的 NLP 方法相比,BERT [23]、GPT-3 [13] 和 BART [37] 等模型在 NLP 方面取得了突破。这些模型利用了迁移学习的思想,学习一项任务可以改善另一项任务的结果。许多研究表明,组合和交织任务可以提高模型的效率。在我们的研究中,我们提出了预训练语言模型的新方法。在法律领域,我们提出的模型(如 BERTLaw [48]、ParaLaw [46])利用组织者提供的标准数据集证明了它们在 COLIEE 2020 和 COLIEE 2021 比赛中的有效性。使用端到端模型(如果垃圾输入,则垃圾输出),因此拥有适当的训练方法对于构建高质量的深度学习模型非常重要。
第 5 章回答了最终的研究问题。除了传统的训练和预训练-微调范式之外,还有第三种方法,知识注入 [47]。这种方法是利用专家知识来支持学习模型和决策。我们可以直接将专家知识以信号的形式输入模型,而不是向模型提供数据以便它自己学习关系。该方法有助于解决稀疏、含噪的数据问题,并利用专家知识训练深度学习模型。这种专业知识可以是语言特征或语义特征的形式。通过我们的实验,我们证明将这种专家知识注入神经网络将提高模型的性能。此外,这种方法还有助于提高深度学习模型的可问责性和可调试性。
论文的最终目标是展示我们在改进法律文本处理中注意力神经网络的道路上的工作。第 3 章和第 4 章的内容是我们参与 COLIEE 的结果和观察。第 5 章介绍了初步研究,试图增强注意力神经网络的可解释性,注意力神经网络被认为是黑盒子。尽管这项工作做得很细致,但实验中可能存在盲点,对结果的解释可能存在偏差。因此,在每项工作中,我们不仅将性能量化为数字,而且对实验结果进行了更深入的分析。在每一章的最后,我们总结了该章的要点和相关的讨论。我们的最终讨论和结论将在第 6 章中介绍。本章使读者能够理解我们的贡献,将其视为改进法律文本处理中注意力模型的连贯工作。最后但同样重要的是,我们概述了可以扩大范围并将这项研究提升到实际应用的未来方向。



