

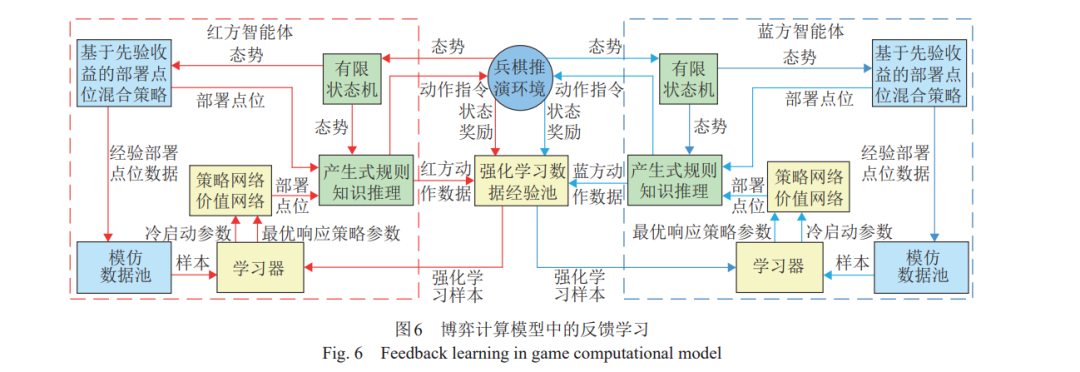
为了使智能体能够应对兵棋推演中的复杂作战场景和作战目的,提出作战方案驱动的可学 习兵棋推演智能体架构。剖析智能体对兵棋系统的“依附特性”和“松耦合特性”,得到智能体的 可学习要求;在智能体框架设计中,使用作战方案压减智能体学习范围。通过有限状态机对应作 战方案中的作战阶段知识,依据作战方案框架确定智能体决策空间,设计可学习的深层神经网络 实施关键决策空间探索,神经网络采用先验知识模仿学习模式和深度强化学习模式。该架构能迭 代探索人类难以充分梳理清楚的多棋子最优部署和协作问题。
成为VIP会员查看完整内容
相关内容

Arxiv
224+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日