

微处理器是现代信息系统的核心基础设施. 大数据、人工智能、5G 等技术的快速发展催生了数据量的爆发性增长, 随之对数据处理能力的需求也急剧增长. 专用计算技术被广泛认为是后摩尔时代的计算机体系结构演化的重要方向. 专用处理器技术的发展一直伴生着通用处理器的发展, 数字信号处理技术甚至早于传统意义上的通用处理器. 通用处理器技术的发展, 不仅在商业上取得了巨大的成功, 很多关键技术也被专用处理器吸收借鉴用于提升专用计算的性能、优化可编程性等. 本文主要分析了数字信号处理器(DSP)、图像处理器(GPU)、深度学习处理器(AI 芯片)和网络处理器(NPU)的关键技术特征, 并进一步对专用计算架构未来发展可能涉及的关键点作出了简要的评述。
引言
如果不考虑成本因素, 一颗理想的处理器应该可以像 CPU (central processing unit) 一样通用, 像 DSP (digital signal processor) 一样处理数字信号, 像 GPU (graphics processing unit) 一样处理图像数 据, 像 NPU (network processing unit, 网络处理器, 也简称 NP) 一样处理网络数据包, 像 “矿机” 一样 竞争加密货币共识算力, 像神经网络芯片一样运行深度神经网络训练和推理等. 但是, 实现如此万能的 处理器芯片是不现实的, 至少从经济成本角度不具备可行性, 专用化就成为了发展的必然 [1] . 专用处 理器并不是通用 CPU 完全改弦易辙, 而更像是基于通用处理器技术的一种分化. 所以我们看到现代 DSP、基带处理器、网络处理器的很多成功产品都包含一个甚至多个通用 RISC (reduced instruction set computer) 核来做系统管理、运行操作系统、与主机通信, 将协处理器也变成一个具备自我管理能 力的主动设备. 从时间上看, DSP 可能也是出现最早的计算芯片, 在集成电路发明 (1958 年) 之前, 德 州仪器 (TI) 公司已经在大批量生产硅晶体管器件. TI 公司在 1967 年发明手持计算器, 1971 年研制 了单芯片微型计算机. 在此之前的 “DSP” 只能称为利用分立器件信号处理 (processing), 还不是名副其实的 “processor”. DSP 没有被冠名某个 “PU” 的称呼也许正是由于出现过早, 当时 “PU” 的称呼还 没流行起来. CPU 最早出现在 1971 年, GPU 出现在 1993 年 (虽然当时的名称还不叫 GPU), 网络处 理器 (NPU) 出现在 1999 年. 从这些时间关系上看, 我们大体可以看出人们首先是对信号处理有需求, 然后才扩展到其他更普遍的数据处理需求上, 因此有了对通用 CPU 的需求. 再由于应用的驱动, CPU 难以满足性能要求, 进而发展出了 GPU, NPU 等更专用的计算芯片. 从这个意义上看, 通用 CPU 技 术可以视为处理芯片的基本技术, 在此基础上发展了高性能 CPU、现代高效能 DSP [2]、高吞吐 GPU、 高通量 NPU [3] 等各种 “XPU”. 个人认为分析这些 XPU 的结构特征有助于更深刻地理解 “通用” 和 “专用” 的本质差异.
针对专用处理器有很多关键问题, 包括: 芯片在架构上有什么差异, 各自具备什么样的软件生态, 能否取得商业上的成功的决定性因素是什么等, 而答案也莫衷一是. 本文的重点是试图从架构层面去 看待这些不同类别的专用处理器芯片的差异, 帮助我们预测未来架构的发展趋势, 对于专用处理器技 术未来的发展做了些许开放性的讨论, 抛砖引玉. 其次, 本文主要讨论经典专用处理器的演化, 而把通 用 CPU 的发展作为背景而暂不加以专门讨论. 同时, 本文主要以 DSP、GPU、AI 芯片和 NPU (网络 处理器) 为主要参考对象, 其中 DSP 以 TI 公司的 C6000 系列为主要参考, GPU 以英伟达 (Nvidia) 公司的 Tesla 架构为主要参考 [4] , AI 芯片以寒武纪的 DianNao [5] 深度学习处理器和 Google 公司的 TPU (tensor processing unit) [6] 为主要参考, NPU 以迈络思 (Mellanox) 公司 (已经被 Nvidia 公司收 购) 的 NP-5 和因特尔 (Intel) 的 IXP [3] 为主要参考, 均为各个公司比较有代表性的产品. 限于篇幅, 本文尚未将新出现 DPU (data processing unit) [7] 芯片架构纳入讨论, 相关内容将作为未来工作.
专用计算架构的设计难度不亚于通用 CPU, 核心目标就是 “有条件地” 高性能. 无论是一个 3 W 的 DSP, 还是一个 300 W 的 GPU, 也无论是面向哪一个专用领域定制化的设计, 都追求在给定的功 耗、芯片面积约束下实现高性能. 然而, 这个问题的复杂性在于专用计算并不仅仅是设计几个运算单 元, 配合几条数据通路那么简单, 它涉及到 IO 子系统、操作系统内核、网络协议栈、访问安全、虚拟 化、二次开发的方便程度等层面的问题, 其中任何一个层面的问题的专业性都极强, 要能融汇贯通并 能系统地组织起来是一个巨大的挑战. 挂一漏万, 本文的内容只代表笔者的观点.
本文余下内容安排如下: 第 2 节阐述了专用处理器的基本概念, 第 3∼6 节分别介绍了数字信号 处理器 (DSP)、图形处理器 (GPU)、AI 芯片和网络处理器 (NPU) 4 类重要的专用处理器的基本特征, 第 7 节表述了笔者对于专用处理器的几点思考, 据此在第 8 节提出了构建专用处理器系统结构的关 键点, 第 9 节总结全文.
专用处理器的基本概念
专用处理器(或专用加速器), 顾名思义, 就是用于处理“特定应用"的处理器, 相对于通用处理器而言, 这类处理器性能更高、功耗更低、通常价格也更便宜, 但是使用范围也相对有限. 计算芯片产业在过去50年的发展历程中, 比较成功的专用处理器门类只有数字信号处理器(DSP)、图形处理器(GPU)和网络处理器(NPU), 这是20世纪90 年代就已经基本定型的格局. 在过去5年中, 用于处理深度学习的神经网络处理器(AI芯片)也开始快速发展, 比较成功的案例包括Google公司的张量处理器TPU [6]、寒武纪公司的DianNao系列深度学习处理器 [5] 等. 专用处理器的最终目标不是替代通用CPU, 而是与现有的通用CPU技术协作, 即将部分CPU运行效率低下的应用卸载(offloading)到专用加速器上运行, 通过构建异构计算平台来高效地处理计算任务. 从产业生态的视角来看, 相比于通用处理器的硬件与软件分离的“水平"模式, 专用加速器更注重软硬协同的“垂直"发展模式.
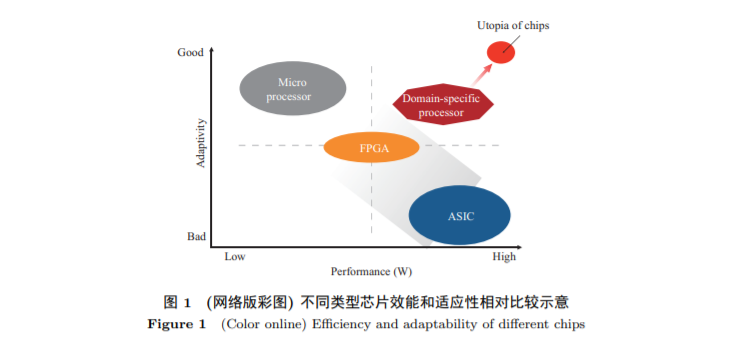
图1从芯片的效能和适应性两个维度来刻画芯片的特征. 这里效能指的是单位功耗下提供的计算能力, 适应性就是通常意义下的通用性. 业界通常将数据处理芯片大体分为三大类: 处理器芯片、ASIC (application specific integrated circuit)芯片和FPGA (field programmable gate array)芯片. 处理器芯片包括CPU, GPU, DSP等, 是用户可编程的芯片; ASIC是面向特定应用(application-specific)的专用集成电路[8], 通常也称之为全定制芯片, 不可编程; FPGA器件属于专用集成电路中的一种半定制电路, 是可“编程"的逻辑列阵, 利用查找表来实现组合逻辑, 但FPGA的“编程"与处理器芯片的软件编程不同, 主要是配置逻辑, 可以理解为硬件编程. 从相对性能来看, ASIC芯片最好, 处理器芯片最差, FPGA介于二者之间; 但是从应用的适应性来看, 处理器芯片最好, FPGA次之, ASIC芯片最差. 值得注意的是这种分类标准并不是按照电路制造工艺, 例如处理器芯片和ASIC芯片本质上都是全定制的集成电路, 处理器芯片本质也是一种ASIC, 但与通常意义上ASIC的最大差别还在于是否具有指令集, 有指令集的就更类似传统的处理器, 反之就归类为ASIC. 此外, 处理器芯片由于其使用广泛、出货量大, 与软件生态联系尤其紧密, 所以将其独立为一个大的类别.
专用处理器芯片的研发追求达到效能和适应性的一个新的帕累托最优(Pareto optimality): 效能接近ASIC, 但是适应性向处理器芯片靠近. 在效能上, 专用加速器通过定制化实现远高于通用处理器芯片的效能; 在适应性上, 从面向特定应用(application-specific)的ASIC范式进化为面向特定领域(domain-specific)的新范式, 不妨称之为“DSIC (domain-specific integrated cirucuit)". DSIC与处理器芯片相比虽然弱化了通用性, 但与ASIC相比也强化了适应性.
无论是DSP、GPU、AI芯片、NPU, 还是现在更新的各种“XPU", 都是处理数据的芯片, 最终都需要执行二进制代码的程序来完成计算. 因此专用处理器设计也大都需要涉及如下6方面内容:(1)约定二进制代码的格式, 即指令; (2)需要将指令变换为机器码, 即汇编; (3)为了提高编程方便程度, 需要将高层程序语言转换为汇编语言, 即编译; (4)为了提高编程的效率, 提供了各种编程环境, 即集成开发环境(integrated development environment, IDE); (5)充分复用高度优化的代码, 即应用程序库; (6)为了方便程序调试, 还需要提供各种仿真工具, 即仿真器(emulator). 所以, 从系统抽象层次来看, 与通用处理器几乎没有区别. 但是不同的DSIC侧重点不同, 有些DSIC只提供API (application programming interface)方式的调用, 例如早期的GPU, 将编译、汇编等过程全都凝结在运行时库中, 从用户角度看, 调用过程与使用OpenCL [9]中的“内建核函数(built-in kernels)"类似, 与调用普通的库函数过程相同; 虽弱化的可编程性, 但是强化了用户使用的便利性. 但也有些DSIC, 如DSP, 使用了大量底层编程, 虽编程难度高, 但方便精确地性能调优.
DSP: 灵活的数据格式
DSP也许是最早出现的专用集成电路. DSP的使用范围非常广, 从简单的MP3播放器到最新一代的5G通信都有使用场景. 常见的DSP大多带有丰富的外设接口, 例如PCIe、以太网、UART、I2C等, 尤其在很多嵌入式设备中, 丰富的外设接口对于提高系统的集成度、降低成本和功耗都有很大帮助, 所以很多DSP产品也演变成带有丰富外设接口的SoC (system on chip)芯片, 如图2(a)所示. 但是DSP最大的特点还是进行数字信号处理的核. 大多数DSP由于使用场景多为移动设备, 或者只是作为CPU系统的数据输入前端, 在系统中的地位并不高, 通常在功耗、散热等方面都不可能给予太高容限, 所以功耗敏感、计算位宽对DSP很重要, 定点、浮点, 半精度、单精度、双精度, 16位、24位、32位、40 位等各种数据格式规范“五花八门". 在寻址上, DSP对于数据对齐方式也最灵活, 设置了大量专门的指令对数据进行对齐操作.
TI公司是DSP芯片的龙头, 被媒体评为是半导体行业利润率最高的公司. 2019财年营业总收入144亿美金, 税后净利润高达50亿美金, 利润率高达35%. 作为比较, 同期Intel收入720亿美金, 利润率29%; 英伟达总营收110亿美金, 利润率25%. TI公司的DSP主要分为3大系列: C2000系列, 集成了AD转换、Flash存储等, 主要用于控制马达、变频器等工控产品; C5000系列, 16 位定点, 主要用于便携声音、视频、机顶盒等设备; C6000系列, 采用了VLIW (very long instruction word)架构, 每秒执行指令峰值可达百亿条, 主要用于数字通信、图像增强、传输、加密解密等对性能要求更高的场景. 下面就以比较复杂的C6678为例做简要介绍, 其顶层架构如图2所示. 粗略观察DSP核其实与通常的RISC核没有太多区别, 如图2(b)所示: 都包括了取指令、指令分发、译码、寄存器读写、Load/Store、计算执行等环节, 但微体系结构有非常显著的特色. 例如, 普通采用超长指令字(VLIW)架构、突出的浮点处理能力、指令与数据分离等, 分析如下.

GPU: 数据并行的典型代表
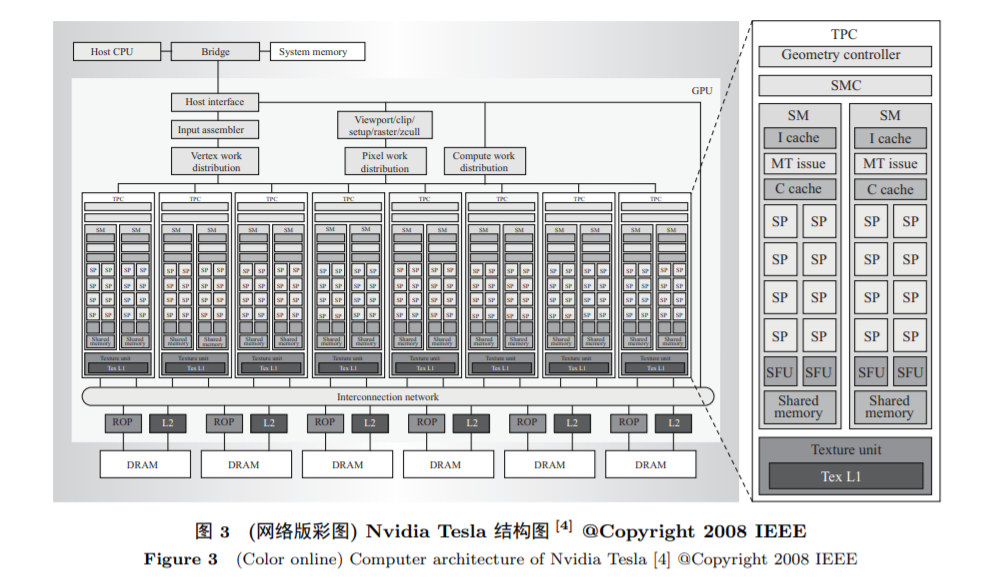
GPU是专为图形(graphic)处理设计的专用处理器. 随着多媒体可视化需求的爆发, 传统的CPU是无法应对每秒动辄数百兆的视频渲染等任务. 高清图像、视频数据天然具备数据并行的特征, 可以通过高度的并行性来同时计算像素块中所有像素的色度、亮度等数据. 图3显示的是英伟达公司研发的经典Tesla架构的GPU, 之所以经典, 是因为从这一代架构开始, GPU 开始朝着通用GPU (即GPGPU)发展, 为后续GPU在深度学习领域的广泛应用奠定了基础.
AI加速器: 大规模张量处理
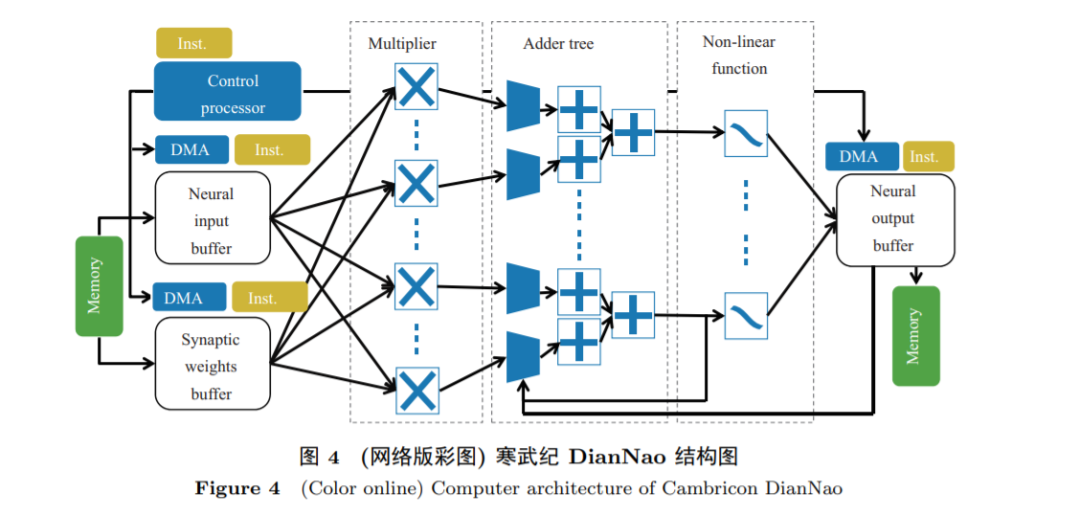
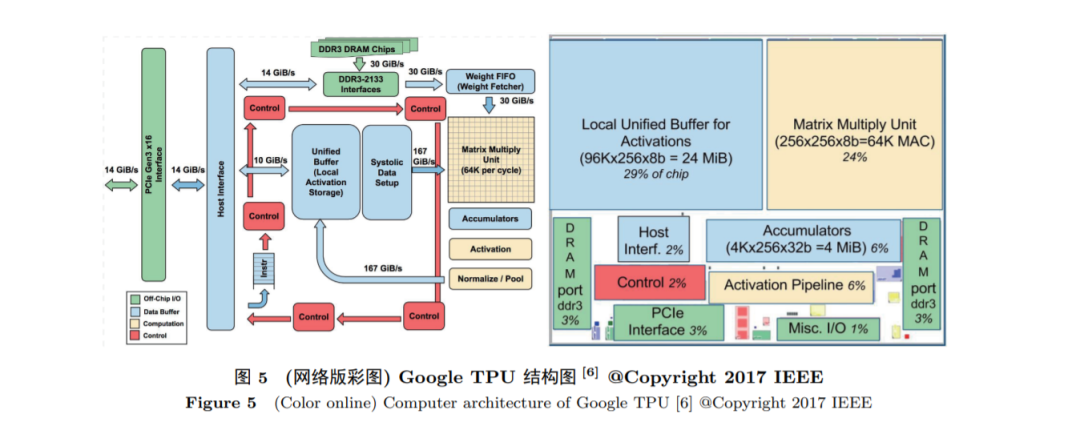
随着深度学习算法效果在图像处理中取得突破, 深度学习在越来越多的应用领域被应用. 在过去5年中, 用于处理深度学习的神经网络处理器(AI 芯片)快速发展, 其中比较成功的案例包括寒武纪的DianNao系列深度学习处理器[5] (图4)、Google的张量处理器TPU [6] (图5) 等. AI加速器大多针对机器学习中张量运算展开加速, 多基于SIMD方式实现, 单条指令通常可以完成一个矩阵的乘法运算, 因此也称为张量处理器. 除了张量处理之外, 还会伴有一些激活函数处理等非线性操作, 运算量相对较小, 实现起来也相对简单. 此类加速器重在张量处理, 控制相对简单, 通常不会集成通用处理核.
NPU: 为网络数据包处理而生
计算机网络是计算机系统发展过程中的一个伟大发明, 网络是大规模并行计算、分布式计算的必要条件. IBM于1974年发布SNA (system network architecture)系列网络协议, 主要解决IBM 的大型机与外围节点的通信问题. 这些节点并不是完整的计算机, 而是像用于ASCII图像显示终端的IBM-3174控制器、打印机等设备. 1974年之前程序还写在纸带上, 主要处理模式还是批处理; SNA引入以后, 开启了事务处理的先河, 把网络通信中容错任务交给了网络协议来处理, 并且基于SNA后来发展出了应用程序接口(API)等概念. 随着后续几年越来越多的设备开始采用网络来连接, 不同厂商提供了不同的网络, 为了解决不同网络间的互连互通(internetwork communication), 美国标准化组织于1981年提出了经典了开放系统互连(open systems interconnection, OSI) 7层模型[13], 这个参考模型一直沿用至今, 仍未过时. 网络处理器的出现是网络技术发展的必然. 随着OSI模型的普及和广泛接受, 在2000年前后, NPU还是学术界研究的热点领域. 第1颗网络处理器于1999年问世, 随后得到了许多半导体公司、网络设备厂商的关注, 据不完全统计, 前后有30余家厂商完成了500余款NPU的设计, 和现在的各种“XPU"的多样性相比有过之而无不及. IBM、 因特尔、思科、EZChip (于2015年被Mellanox收购)都推出了相应的系列产品, 典型如Intel的IXP系列和Mellanox的NP系列网络处理器.
各家NPU产品虽然各有差异, 覆盖不同的协议层次, 面向不同的协议内容, 但是它们的结构模块具有相似性, 例如都包含的模块包括通用处理器核、队列管理单元、路由管理、缓存管理、IO接口管理等. 值得一提的是, 最近兴起的DPU架构, 有很多特征借鉴了NPU技术, 特别是在对路由、交换、数据包处理的高效支持上, 相关讨论将作为未来工作开展.
关于专用处理器的几点思考
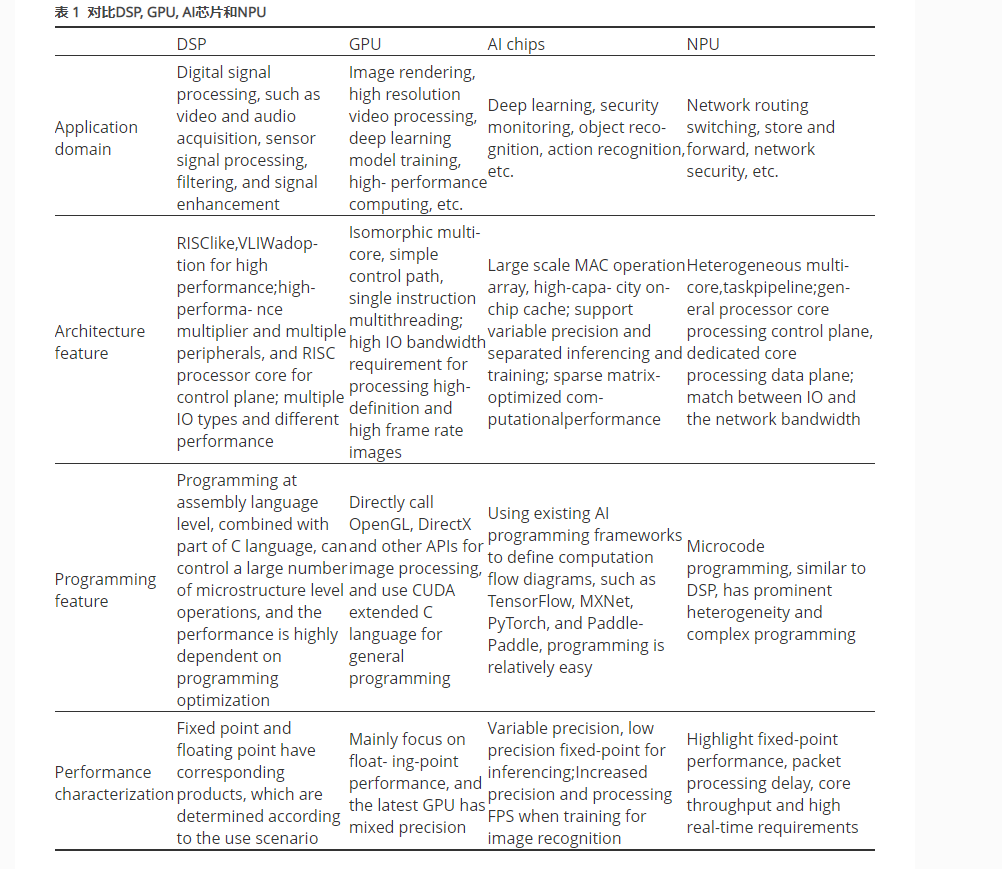
表1对前述的DSP, GPU, AI芯片和NPU从架构特征、编程特点和性能刻画3个维度进行了比较, 概述了这4类专用处理器的主要区别. 分析可以看出, 专用处理器的设计相比于通用CPU而言, 侧重点非常不同. 比如, 不太强调指令集, 也没过多的突出应用生态, 但是非常注重极致的性能优化, 注重与具体计算模式的匹配. 以下是笔者关于专用处理器的本质特征的几点思考, 抛砖引玉.
结论
采用专用处理器芯片是计算系统提升算力、提高效率的有效手段, 业界对于“XPU"概念的广泛关注反映了人们对新型计算芯片期望. 本文以经典的数字信号处理器DSP、图形处理器GPU、 AI芯片、网络处理器(NPU)作为案例, 以这4类专用处理器的结构特征为分析重点, 总结得出DSP最重要的结构特征是支持灵活的数据格式, 能效比优化极致; GPU 是充分利用数据并行的典型, 并且正在朝着通用化的方向发展; AI芯片围绕大规模张量处理, 支持可变精度来优化性能; NPU聚焦网络数据包处理, 构造高通量的流水线. 笔者发现一些在通用CPU中没有得到成功发展的技术, 如VLIW, 在专用处理器中发挥了重要作用; 而通用处理器体系下最重要维度, 如指令系统, 在专用处理器中反而被弱化了. 这些差异进一步引发了笔者从经典体系结构的角度对专用处理器的几点思考. 最后, 本文讨论构建专用处理器系统结构的4个关键点: 即针对数据平面的架构, 融合新存储、传输、封装等新技术, 面向领域专用语言和充分利用好“专用"这个特征来简化系统设计.

