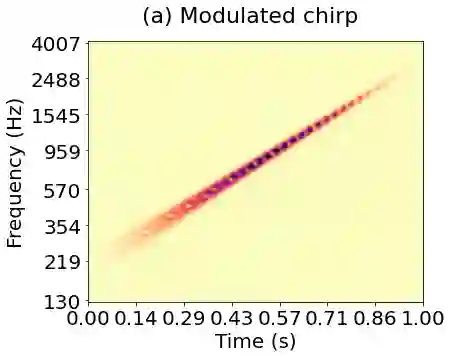
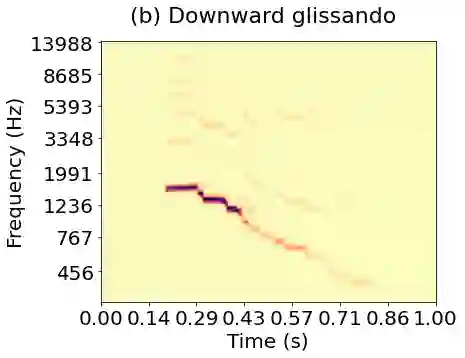
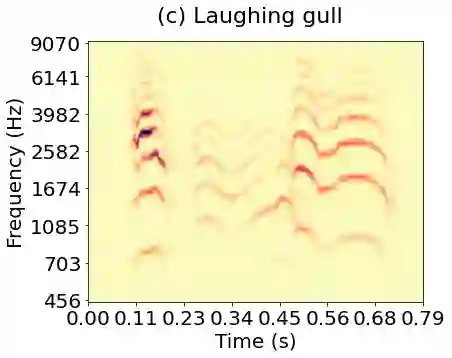
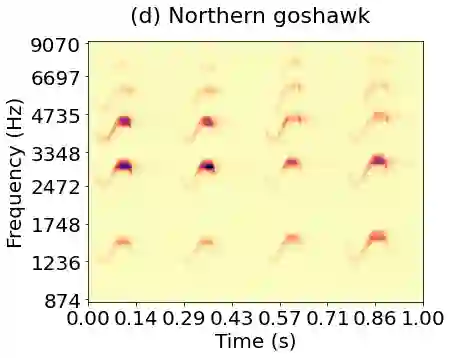
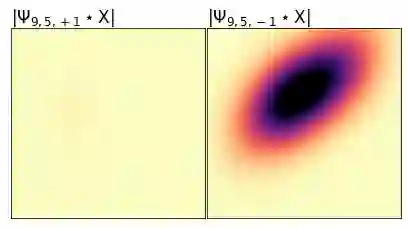
Joint time-frequency scattering (JTFS) is a convolutional operator in the time-frequency domain which extracts spectrotemporal modulations at various rates and scales. It offers an idealized model of spectrotemporal receptive fields (STRF) in the primary auditory cortex, and thus may serve as a biological plausible surrogate for human perceptual judgments at the scale of isolated audio events. Yet, prior implementations of JTFS and STRF have remained outside of the standard toolkit of perceptual similarity measures and evaluation methods for audio generation. We trace this issue down to three limitations: differentiability, speed, and flexibility. In this paper, we present an implementation of time-frequency scattering in Kymatio, an open-source Python package for scattering transforms. Unlike prior implementations, Kymatio accommodates NumPy and PyTorch as backends and is thus portable on both CPU and GPU. We demonstrate the usefulness of JTFS in Kymatio via three applications: unsupervised manifold learning of spectrotemporal modulations, supervised classification of musical instruments, and texture resynthesis of bioacoustic sounds.
翻译:联合时频散射(JTFS)是时间频域的一个革命性操作者,它以不同速度和尺度提取时温调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频频频频频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频调频频