

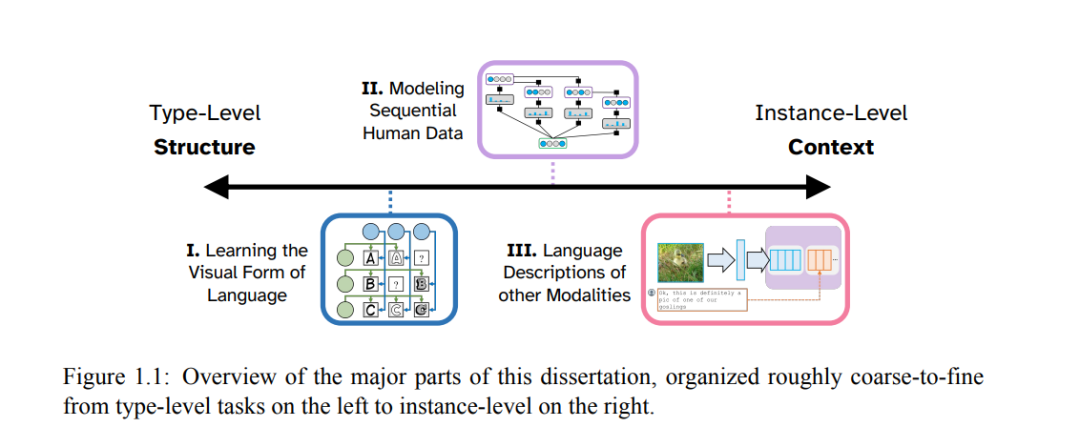
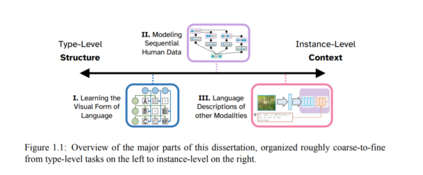
在从大规模语言数据语料库中学习表示时,一个普遍的策略是将该数据视为一系列独立同分布(IID)样本,这些样本相互独立地建模。虽然这种方法在某些方面是有益的,因为它允许通过随机梯度下降(SGD)进行高效训练,并且不依赖于可能并不总是存在的元数据,但它确实存在局限性。利用个别数据点之间更复杂的结构联系可以让信息在我们的语料库内流动,使得学习到的表示更具上下文敏感性,并允许更多的参数共享,从而更容易泛化到未见类别的示例。在这项工作中,我们将把这一思想应用于各种设置——主要是那些处于语言和其他模态之间边界的设置——对于这些设置,现有的先前工作大多没有明确利用数据内的可观察结构,我们还将展示如何通过更低级的建模选择为我们的模型添加有用的归纳偏见。为了保持可解释性和控制性,我们将同时使用概率变分学习框架和非变分方法(如检查列表模型和检索引导生成)来做到这一点。这篇论文分为三个部分,将这一广泛主题应用于各种具体应用。首先,我们将检查在数字字体中学习风格和结构的解耦表示的任务,然后将类似的建模思想应用于分析线性B文手写风格的任务。在下一部分,我们将探索学习时间排序数据的上下文化表示的方法,其中一个数据点的预测可能会影响附近的预测,例如钢琴指法估计和社交媒体上的话语主题建模。最后,我们将为输入信号本身是多模态的设置提出新的方法,例如为图像和音乐编写描述性标题的任务。



成为VIP会员查看完整内容




相关内容

Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日