

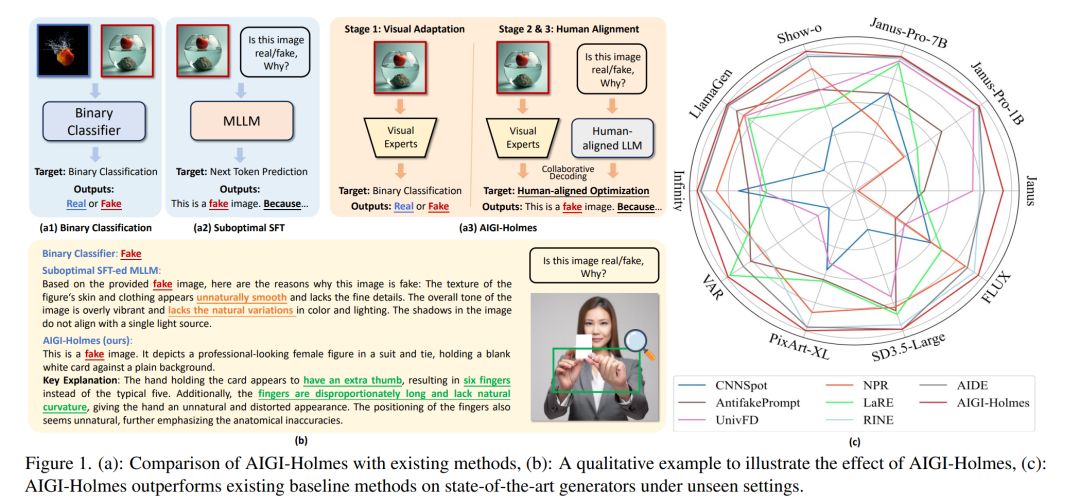
随着AI生成内容(AIGC)技术的迅猛发展,逼真的AI生成图像(AIGI)在虚假信息传播中的滥用日益严重,已对公共信息安全构成威胁。尽管现有的AIGI检测技术在总体上效果良好,但仍面临两个关键问题:(1)缺乏可供人类验证的解释性;(2)在应对新一代生成技术时泛化能力不足。 为应对上述挑战,我们构建了一个大规模、全面的检测数据集 Holmes-Set,其中包括两个子集:Holmes-SFTSet(一个包含图像是否为AI生成的解释性指令微调数据集)和 Holmes-DPOSet(一个对齐人类偏好的偏好学习数据集)。我们提出了一种高效的数据标注方法——多专家陪审团机制(Multi-Expert Jury),通过结构化多模态大语言模型(MLLM)解释增强数据生成质量,并结合跨模型评估、专家缺陷过滤与人类偏好修正,保障数据质量。 此外,我们设计了一个精细化的三阶段训练框架 Holmes Pipeline,包括视觉专家预训练、监督微调和直接偏好优化(DPO),以此适配多模态大语言模型用于AIGI检测,并生成具有人类可验证性与人类一致性的解释。最终,我们得到所提出的模型 AIGI-Holmes。 在推理阶段,我们引入了一种协同解码策略,将视觉专家的感知能力与MLLM的语义推理能力结合,进一步增强了模型的泛化能力。在三个基准数据集上的广泛实验验证了 AIGI-Holmes 的有效性。
成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日