大型语言模型(LLMs)的显著成功为实现人工通用智能(AGI)照亮了一个有前景的道路,因其在多个应用领域展现出了前所未有的表现,这一成就已引起学术界和工业界的广泛关注。随着LLMs在研究和商业领域的日益重要,其安全性和可靠性问题已成为一个日益严峻的关注点,不仅对研究人员和企业来说至关重要,对于各国也同样重要。目前,现有关于LLM安全的调查主要集中在LLM生命周期的特定阶段,如部署阶段或微调阶段,缺乏对LLM“全生命周期”安全的全面理解。为了解决这一问题,本文首次提出了“全栈”安全的概念,系统性地考虑了LLM训练、部署及最终商业化过程中的安全问题。与现有的LLM安全调查相比,我们的工作展示了几项独特的优势:(I)全面视角。我们定义了完整的LLM生命周期,涵盖数据准备、预训练、后训练(包括对齐和微调、模型编辑等)、部署及最终商业化。根据我们的了解,这代表了首个涵盖LLM整个生命周期的安全调查。(II)广泛的文献支持。我们的研究基于对800篇以上文献的详尽回顾,确保了对安全问题的全面覆盖,并在更整体的理解框架下进行系统性组织。(III)独特的见解。通过系统的文献分析,我们为每一章节开发了可靠的路线图和视角。我们的工作确定了有前景的研究方向,包括数据生成安全、对齐技术、模型编辑和基于LLM的智能体系统的安全。这些见解为研究人员提供了宝贵的指导,助力其在该领域的未来工作。我们在 https://github.com/bingreeky/full-stack-llm-safety 提供了LLM(智能体)安全领域的最新文献回顾,作为研究人员和工程师的有益支持。
关键词—大型语言模型、LLM智能体、安全、后训练、对齐、模型编辑、遗忘、评估
1 引言
大型语言模型(LLMs)的出现和成功[1, 2, 3, 4, 5]极大地改变了学术界和工业界的生产模式[6, 7, 8, 9, 10, 11, 12, 13],为未来的人工通用智能(AGI)开辟了一条潜在的道路[14, 15, 16]。更进一步,LLMs通过整合工具[17, 18, 19, 20]、记忆[21, 22, 23, 24]、API[25, 26],以及构建与其他LLMs的单智能体或多智能体系统,提供了强大的工具,使大型模型能够感知、理解并改变环境[27, 28, 29, 30]。这引起了对具身智能的广泛关注[31, 32]。
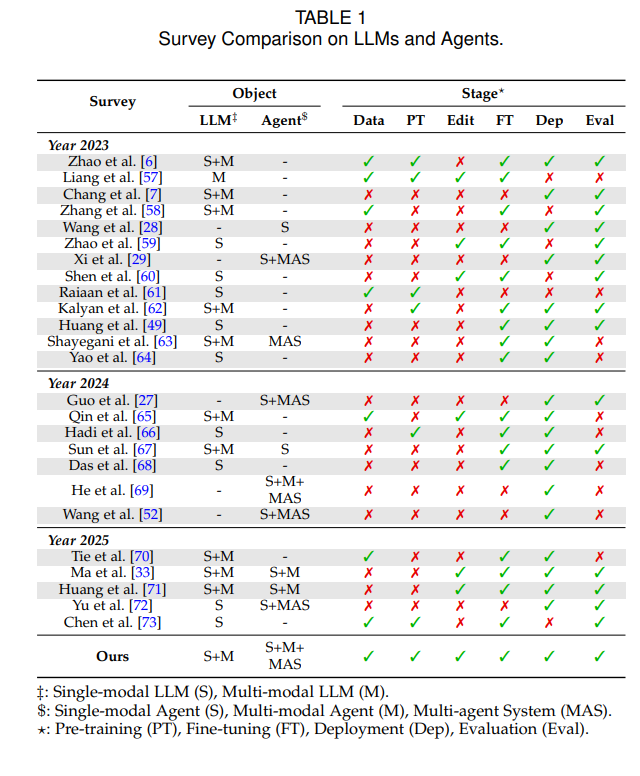
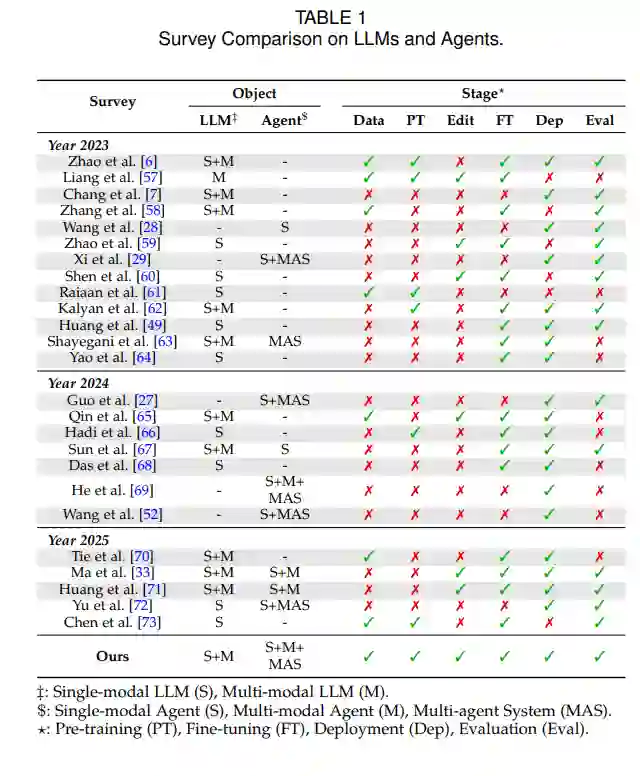
不幸的是,LLM的整个生命周期始终面临着安全性和可靠性问题[33, 34, 35]。在数据准备阶段,由于LLM需要大量且多样的数据,而大量数据来自互联网和其他开源场景,数据中的有害成分和用户隐私可能渗透到模型参数中,引发模型危机[36, 37, 38]。模型的预训练过程,由于其无监督性质,潜意识地吸收了这些有害数据和隐私信息,从而导致模型的“基因组”带有危险特征和隐私问题[39, 40, 41, 42]。 在模型部署之前,如果没有与安全措施妥善对齐,它很容易偏离人类价值观[43, 44]。与此同时,为了使模型更“专注”,微调过程会使用更安全且定制的数据,以确保模型在特定领域表现完美[45, 46, 47, 48]。模型部署过程还涉及越狱攻击等问题及相应的防御措施[49, 50, 51],尤其对于基于LLM的智能体[52],这些智能体可能由于与工具、记忆和环境的互动而受到污染[53, 54, 55, 56]。 之前的LLM调查主要集中在LLM本身的研究方面,往往忽视了对LLM安全的详细讨论[7, 34],以及对可信性问题的深入探索[74]。同时,现有的涉及LLM安全的调查大多侧重于各种可信性问题,或仅限于LLM生命周期的某个单一阶段[33, 75, 76],如部署阶段和微调阶段。这些调查通常缺乏对安全问题的专业研究,也缺乏对整个LLM生命周期的全面理解。表1总结了我们的调查与之前调查的差异。通过回顾上述调查并系统地研究相关文献,我们得出结论,我们的调查旨在解决现有调查未涵盖的几个问题:
大型模型的安全性应涵盖哪些方面?
贡献1:在对整个LLM生命周期进行系统文献回顾后,我们将LLM从“诞生”到“部署”的过程划分为不同阶段:数据准备、模型预训练、后训练、部署,最后是使用。更细致地,我们进一步将后训练阶段分为对齐和微调,它们分别用于满足人类偏好和性能需求。基于此,我们将模型编辑和遗忘纳入考虑,作为高效更新模型知识或参数的方法,从而有效确保模型在部署中的可用性。在部署阶段,我们将大型模型的安全性划分为纯LLM模型(不包含额外模块)和基于LLM的智能体(增强了工具、记忆和其他模块)。该框架涵盖了模型参数训练、收敛和固化的整个周期。
如何提供更清晰的分类法和文献回顾?
贡献2:经过对超过800篇文献的全面评估,我们开发了一个涵盖LLM整个生命周期的全栈分类框架,提供了系统性的LLM安全问题洞察。我们为LLM时间线的每个阶段与其他相关部分之间提供了更可靠的关联分析,帮助读者理解LLM的安全问题,同时明确每个LLM阶段的研究阶段。
未来LLM安全问题的潜在增长领域有哪些?
贡献3:通过系统地检查LLM生产过程中各个阶段的安全问题,我们确定了LLM(及LLM智能体)的有前景的未来方向和技术方法,强调了可靠的视角。这些见解超越了狭隘的领域视角,提供了对研究“轨道”潜力的全面理解。我们相信,这些见解有可能引发未来的“恍然大悟”时刻,并推动显著突破。

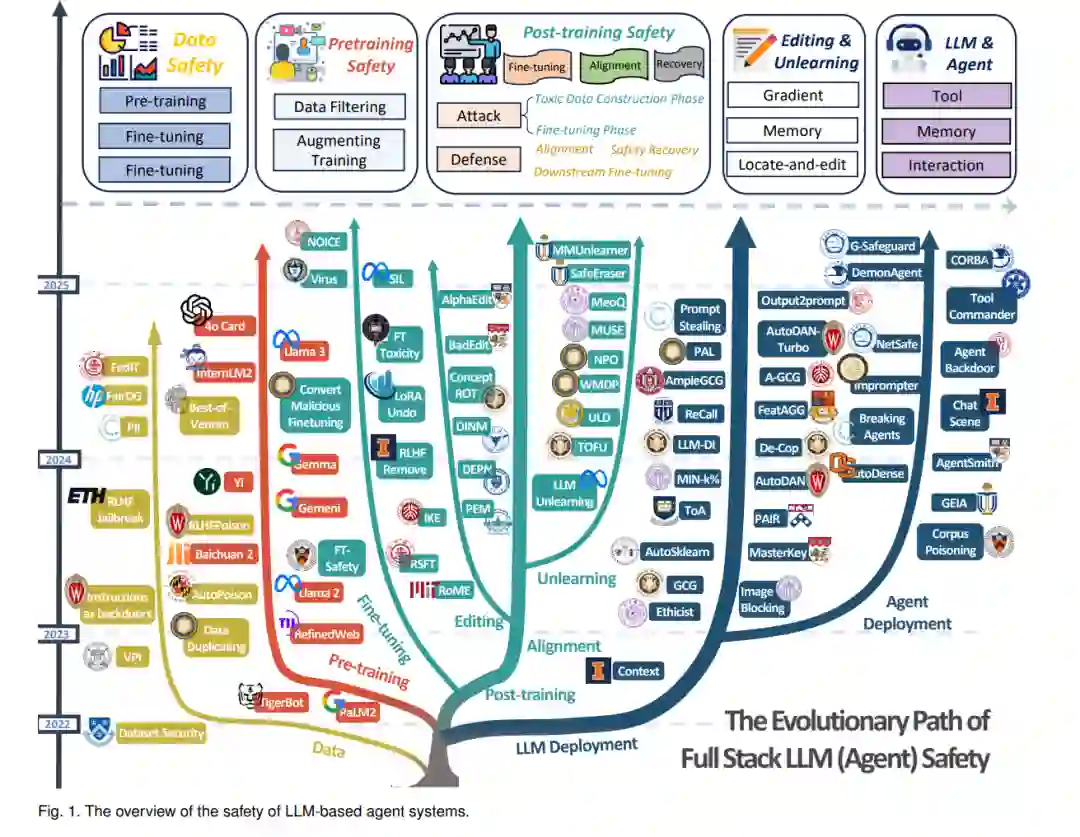
分类法:我们的文章从数据的结构准备开始。在第2节中,我们系统地介绍了模型训练各个阶段潜在的数据问题,以及当前流行的数据生成研究。在第3节中,我们重点关注预训练阶段的安全性和可靠性问题,其中包括两个核心模块:数据过滤和增强。在第4节中,我们专注于后训练阶段,与之前的工作不同,我们将微调和对齐纳入其中,涉及攻击、防御和评估。基于此,我们还关注模型安全漏洞后的安全恢复过程。在第5节中,我们观察到模型在实际场景中需要动态更新。为此,我们通过专门的模型编辑和知识遗忘模块,解决参数高效更新和知识冲突问题。尽管遗忘和编辑方法有相当大的重叠,但在本调查中,我们通过将它们分开处理,增强了可读性,方便读者根据框架探索各自的领域。 接下来,在第6节中,我们关注模型参数固化后的安全问题,这与传统的大型模型安全调查有许多共同点。我们遵循攻击、防御和评估的分类法,以确保可读性。更进一步,我们分析了与LLM连接的外部模块的机制,重点关注基于LLM的智能体的安全性。最后,在第7节中,我们提出了LLM应用的商业化和伦理指南以及用户使用的多重安全问题。为了帮助读者全面理解我们的研究框架,我们在第8节中概述了有前景的未来研究方向,而第9节则总结了我们的结论和更广泛的影响。 在每章的结尾,我们提供了所涵盖研究内容的路线图和视角,以便读者更清晰地理解技术演变路径和潜在的未来增长领域。在图1中,我们展示了各研究主题下的代表性工作,以及各分支的分类目录。我们的安全调查不仅开创了新的研究范式,还揭示了关键的前沿话题。通过映射LLM完整生命周期中的安全考虑,我们建立了一个标准化的研究架构,将指导学术界和工业界的安全性举措。