

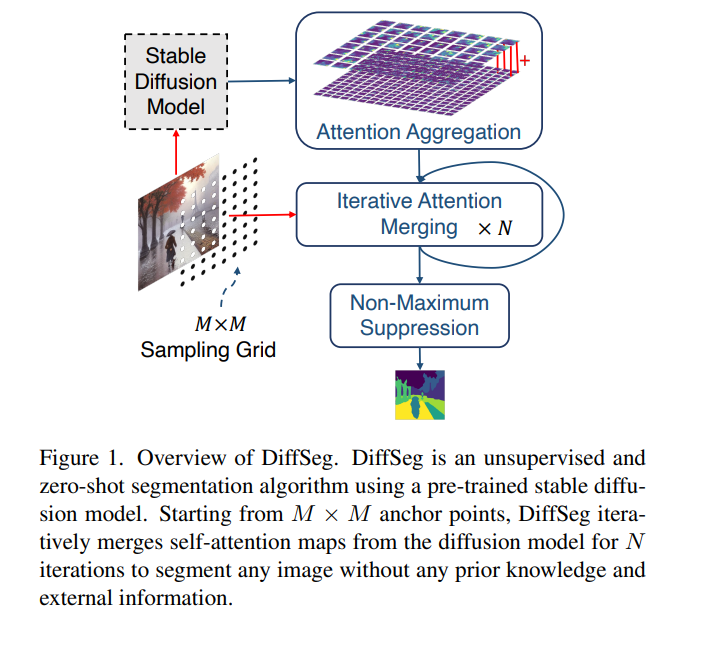
在计算机视觉中,生成高质量的图像分割掩码是一个基本问题。最近的研究探索了大规模的监督训练,以实现几乎任何图像风格的零样本分割,以及无监督训练,以实现无需密集注释的分割。然而,构建一个能够在零样本情况下、无需任何注释即可分割任何对象的模型仍然充满挑战。在本文中,我们提议利用稳定扩散模型中的自监督学习层来实现这一目标,因为预训练的稳定扩散模型已经在其注意力层中学习了对象的内在概念。具体来说,我们引入了一个简单而有效的基于测量KL散度的注意力图之间的迭代合并过程,以将它们合并成有效的分割掩码。所提出的方法不需要任何训练或语言依赖,就可以为任何图像提取高质量的分割。在COCO-Stuff-27上,我们的方法在像素准确度上绝对超过了之前的无监督零样本SOTA方法26%,在平均IoU上超过了17%。项目页面位于https://sites.google.com/view/diffseg/home。
成为VIP会员查看完整内容
相关内容

Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日