

深度学习在各个领域占据主导地位,从根本上改变了人类社会。效率是民主化深度学习和扩大其应用范围的关键因素。随着摩尔定律的放缓以及模型尺寸扩展速度的加快,这一点变得越来越重要。我们需要高效的算法和系统来帮助我们弥合这一差距。
在这篇论文中,我们将讨论提高深度学习效率的技术,通过消除冗余。我们研究了在缩放的两个极端——微型机器学习(TinyML)和大型语言模型(LLMs)——进行高效深度学习计算。TinyML旨在在具有紧密内存限制的低功耗IoT设备上运行深度学习模型。我们探索了系统-算法共设计方法来消除冗余的内存使用,并在商用微控制器上实现实际应用,首次实现了ImageNet 70%的精度里程碑。我们进一步将解决方案从推理扩展到训练,并在仅有256KB内存的情况下启用设备上学习。与TinyML类似,LLMs的巨大模型尺寸也超出了即使是最先进GPU的硬件能力。我们开发了针对不同服务工作负载的训练后量化方案,以减少权重和激活的冗余位,实现了W8A8量化(SmoothQuant)用于计算受限推理和W4A16量化(AWQ)用于内存受限。我们进一步开发了TinyChat,一个高效且原生支持Python的服务系统,以实现来自量化的加速。最后,我们将讨论一些特定领域的优化机会,包括使用时间位移模块(TSM)的高效视频识别和使用Anycost GANs的图像生成,我们通过专门的模型设计减少了特定应用的冗余。
深度学习在包括计算机视觉[150, 113, 71]、自然语言处理[277, 35, 68]、图像生成[98, 120, 137]、语音识别[16, 222]等多个领域取得了巨大成功。多年来,由于新算法的不断出现以及模型和数据大小的持续扩展,各种深度学习方法的性能快速增长。2012年,点燃深度学习时代的AlexNet[150]拥有6000万参数的模型大小(在那时被认为是“大”的),而2020年开发的GPT-3模型[35]拥有1750亿参数。我们观察到在不到8年的时间里,模型大小增加了3⇥106倍。更令人印象深刻的是,即使在这种巨大的规模下,扩展趋势也没有减缓[257, 208]。
深度学习的不断扩展解锁了各种新兴属性。然而,这种扩张伴随着对计算效率和能耗的日益担忧,影响了训练和推理过程。当涉及到推理或模型部署时,即使是像NVIDIA H200这样的高容量GPU,拥有141GB的内存,也无法容纳像GPT-3这样大的模型,更不用说更大的GPT-4了。人们正在努力将这些LLMs的服务扩展到更广泛的用户基础。此外,在边缘部署深度学习可以带来更好的隐私保护和更快的响应时间,但也受到更严格的硬件限制的约束。能耗也很容易耗尽智能手机甚至自动驾驶汽车的电池。另一方面,训练深度学习模型需要更多的计算。增长的成本限制了训练的可扩展性,并可能导致大量的碳足迹[261]。因此,如果我们想要将深度学习民主化,带来更大的好处,特别是在摩尔定律后的时代,效率就成了关键因素。
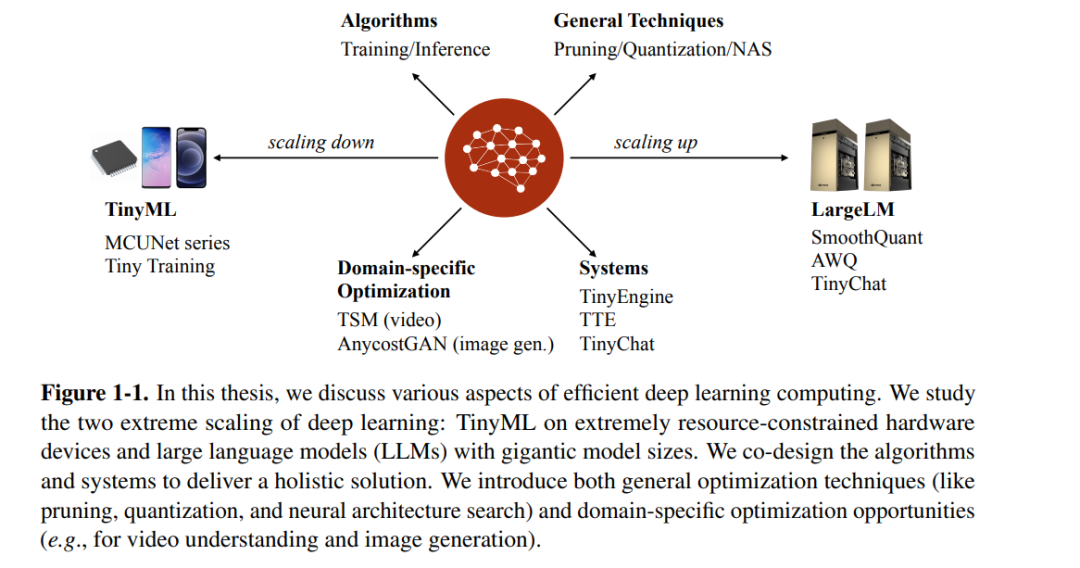
在这篇论文中,我们想要通过消除冗余来解决深度学习的效率瓶颈。我们研究了两个极端的缩放:微型机器学习(TinyML)和大型语言模型(LLMs)(图1-1)。TinyML旨在在具有紧密内存限制(例如,256KB)的低功耗IoT设备上运行深度学习模型,而LLMs拥有超过1000亿参数,已超出最强大GPU的容量。尽管两者之间的差距超过了6个数量级,我们发现它们实际上面临着相同的根本瓶颈,即深度学习模型超出了硬件容量。我们开发了高效的深度学习算法和系统来帮助弥合这一差距。
具体来说,对于TinyML,我们采用系统-算法共设计减少冗余的内存使用,并构建了MCUNet系列[168, 167],它使商用微控制器上的实际应用成为可能,并首次实现了ImageNet 70%的精度里程碑。我们的MCUNet模型在TinyEngine的反馈下通过TinyNAS进行了优化,本质上在相同的优化循环中融合了系统和算法的反馈。这种联合优化揭示了一些独特的优化机会,如基于补丁的高分辨率输入推理[167],如果是分开优化则不可能实现。我们进一步将解决方案从推理扩展到训练,在仅256KB内存下启用设备上学习[174]。 对于高效的LLMs,我们去除了权重和激活的冗余位以减少LLM推理的成本。LLMs的量化允许我们减少内存带宽并利用低位指令,这些指令具有更高的吞吐量。我们的工作实现了W8A8量化(SmoothQuant)[304],用于云端的批量服务,这是计算受限的;以及W4A16量化(AWQ)[172],用于边缘上的单查询服务,这通常是内存受限的。不同的量化方案针对独特的工作负载特征解决了不同的硬件瓶颈。我们进一步共同设计了TinyChat[172],一个高效且原生支持Python的服务系统,将理论节省转化为实际加速,实现了跨各种设备的>3倍速度提升。
除了上述讨论的视觉和语言骨干(CNN和变换器)的通用优化技术(例如,剪枝、量化、神经架构搜索)外,我们还应探索特定领域的优化机会,以进一步减少冗余并提高效率。一个很好的例子是视频理解:视频可以被视为一系列连续图像,由于时间连续性,它们之间存在高度的互信息和冗余。使用3D CNN进行时空建模导致了巨大的计算成本。我们提出的时间位移模块(TSM)[170]探索了时间上的冗余,并实现了以2D成本获得3D CNN性能。另一个例子是使用生成对抗网络(GANs)进行图像编辑,通常推理需要几秒钟,这阻碍了互动体验。我们从渲染管线中获得灵感,训练了Anycost GANs[173],通过在编辑过程中减少冗余的高分辨率细节和模型容量,提供快速预览。这两种优化都是针对应用的特定属性的,不能用通用模型优化技术覆盖。





