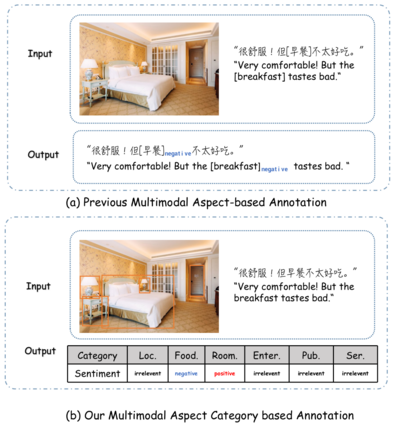
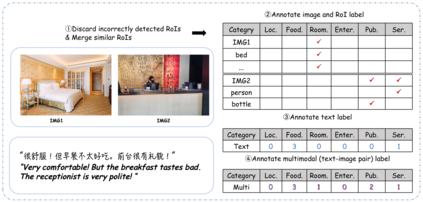
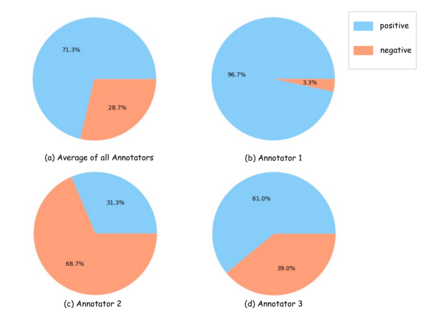
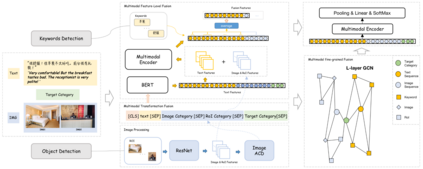
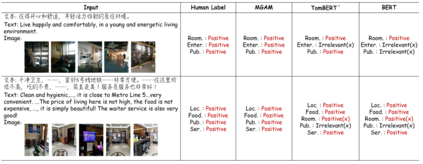
Multimodal fine-grained sentiment analysis has recently attracted increasing attention due to its broad applications. However, the existing multimodal fine-grained sentiment datasets most focus on annotating the fine-grained elements in text but ignore those in images, which leads to the fine-grained elements in visual content not receiving the full attention they deserve. In this paper, we propose a new dataset, the Multimodal Aspect-Category Sentiment Analysis (MACSA) dataset, which contains more than 21K text-image pairs. The dataset provides fine-grained annotations for both textual and visual content and firstly uses the aspect category as the pivot to align the fine-grained elements between the two modalities. Based on our dataset, we propose the Multimodal ACSA task and a multimodal graph-based aligned model (MGAM), which adopts a fine-grained cross-modal fusion method. Experimental results show that our method can facilitate the baseline comparison for future research on this corpus. We will make the dataset and code publicly available.
翻译:最近,多式微微微微感知分析因其广泛应用而引起越来越多的注意。然而,现有的多式微微微微感知数据集最侧重于在文本中说明细微微的成份,但忽略了图像中的成份,从而导致视觉内容中的微微小成份得不到应有的充分注意。我们在本文件中提议了一个新的数据集,即多式微微微感知分析(MACSA)数据集,该数据集包含超过21K文本模数对。该数据集为文字内容和视觉内容提供了细微的成份说明,并首先将侧面类别用作对两种模式之间细微成份的成份。根据我们的数据集,我们提议采用多式超模数的ACSA任务和基于多式图表的成份统一模型(MGAM),该模型采用了一种精细的跨式跨式成型聚合法。实验结果显示,我们的方法可以促进今后对本项研究的基线比较。我们将公开提供数据集和代码。