
大模型的兴起在改变各个领域?如何把大模型用到推荐系统,是近期该领域关注的一个话题。来自香港理工大学等学者最新的《大型语言模型(LLMs)时代的推荐系统》,全面介绍了LLMs增强推荐系统的最新进展和挑战。

随着电子商务和网络应用的繁荣,推荐系统(RecSys)已成为我们日常生活中的重要组成部分,为用户提供个性化建议,满足其偏好。虽然深度神经网络(DNNs)在通过建模用户-物品交互并融合文本信息方面在增强推荐系统方面取得了重大进展,但这些基于DNN的方法仍然存在一些局限性,如难以有效理解用户的兴趣和捕捉文本信息、在各种已见/未见推荐场景中无法泛化以及缺乏对其预测的推理能力等。 同时,诸如ChatGPT和GPT4之类的大型语言模型(LLMs)的出现,由于它们在语言理解和生成等基本任务上的显著能力以及令人印象深刻的泛化和推理能力,已经彻底改变了自然语言处理(NLP)和人工智能(AI)领域。因此,近期的研究尝试利用LLMs的能力来增强推荐系统。
鉴于推荐系统中这一研究方向的快速发展,迫切需要一个系统性的概述,总结现有的LLM增强推荐系统,以便为相关领域的研究人员和实践者提供深入的理解。因此,在本综述中,我们从预训练、微调和提示等多个方面全面调研了LLM增强推荐系统,具体包括首先介绍代表性方法,以利用LLMs(作为特征编码器)来学习用户和物品的表示。然后,我们从预训练、微调和提示三个范式的角度调研了LLMs的最新高级技术,以增强推荐系统。最后,我们全面讨论了这一新兴领域的有前途的未来方向。
https://www.zhuanzhi.ai/paper/57be25ae9ed013cd3d7ff9d65eee6c6a
概述
推荐系统(RecSys)在缓解信息过载,丰富用户在线体验方面发挥着重要作用(即用户需要过滤海量信息以找到感兴趣的信息)[1],[2]。它们针对不同应用领域,如娱乐[3]、电子商务[4]和职位匹配[2],为候选项提供个性化建议,以满足用户的偏好。例如,在电影推荐(如IMDB和Netflix)中,根据电影内容和用户过去的互动历史,向用户推荐最新的电影,帮助用户发现符合其兴趣的新电影。 推荐系统的基本思想是利用用户与物品之间的交互以及它们相关的附加信息,特别是文本信息(如物品标题或描述、用户资料以及物品的用户评价),来预测用户与物品之间的匹配分数(即用户可能喜欢物品的概率)[5]。更具体地说,用户和物品之间的协同行为已被用来设计各种推荐模型,进而可以用于学习用户和物品的表示[6],[7]。此外,关于用户和物品的文本附加信息包含丰富的知识,可以帮助计算匹配分数,为推进推荐系统提供了深入了解用户偏好的重要机会[8]。
由于在各个领域中具有显著的表示学习能力,深度神经网络(DNNs)已被广泛采用来推进推荐系统[9],[10]。DNNs在建模用户-物品交互方面展现出独特的能力,具备不同的架构。例如,作为处理序列数据的特别有效工具,循环神经网络(RNNs)已被用于捕捉用户互动序列中的高阶依赖关系[11],[12]。将用户的在线行为(如点击、购买、社交)视为图结构数据时,图神经网络(GNNs)已成为先进的表示学习技术,用于学习用户和物品的表示[1],[6],[13]。同时,DNNs在编码附加信息方面也表现出优势。例如,提出了基于BERT的方法来提取和利用用户的文本评论[14]。
尽管前述的成功,大多数现有的先进推荐系统仍然面临一些固有的局限性。首先,由于模型规模和数据大小的限制,之前针对推荐系统的基于DNN的模型(如CNN和LSTM)以及预训练语言模型(如BERT)无法充分捕捉有关用户和物品的文本知识,展现出较差的自然语言理解能力,从而在各种推荐场景中导致次优的预测性能。其次,大多数现有的RecSys方法都是针对特定任务进行设计的,对于未见过的推荐任务缺乏充分的泛化能力。例如,一个推荐算法在用户-物品评分矩阵上进行良好训练,用于预测电影评分,但是对于该算法在一些解释性要求下进行电影的前k推荐是具有挑战性的。这是因为这些推荐架构的设计高度依赖于特定任务的数据和领域知识,适用于特定的推荐场景,如前k推荐、评分预测和可解释的推荐。第三,大多数现有的基于DNN的推荐方法可以在需要简单决策的推荐任务上取得有希望的性能(如评分预测和前k推荐)。然而,在支持涉及多个推理步骤的复杂多步决策方面,它们面临困难。例如,多步推理对于旅行规划推荐至关重要,推荐系统首先应考虑基于目的地的热门旅游景点,然后安排与旅游景点相对应的合适行程,并最终根据特定用户偏好(如旅行费用和时间)推荐一份行程计划。
近期,作为先进的自然语言处理技术,拥有数十亿参数的大型语言模型(LLMs)已经在自然语言处理(NLP)[15]、计算机视觉[16]和分子发现[17]等各个研究领域产生了巨大影响。从技术上讲,大多数现有的LLMs都是基于Transformer架构的模型,它们在大量来自不同来源(如文章、书籍、网站和其他公开可用的书面材料)的文本数据上进行预训练。随着LLMs的参数规模随着更大的训练语料库而不断扩大,近期的研究表明LLMs可以具备卓越的能力[18],[19]。更具体地说,LLMs已经展示了其在语言理解和生成方面前所未有的强大能力。这些改进使得LLMs能够更好地理解人类意图,并生成更加接近人类自然语言的语言响应。此外,近期的研究表明,LLMs表现出令人印象深刻的泛化和推理能力,使得LLMs能够更好地泛化到各种未见任务和领域。具体来说,LLMs不需要在每个特定任务上进行广泛的微调,而是可以通过提供适当的指令或少量任务示例来应用其所学的知识和推理能力,从而适应新的任务。高级技术,如上下文学习,还可以在不对特定下游任务进行微调的情况下进一步增强LLMs的这种泛化性能[19]。此外,通过诸如思维链等提示策略的加持,LLMs可以在复杂的决策过程中生成具有逐步推理的输出。因此,鉴于它们强大的能力,LLMs展示了改革推荐系统的巨大潜力。
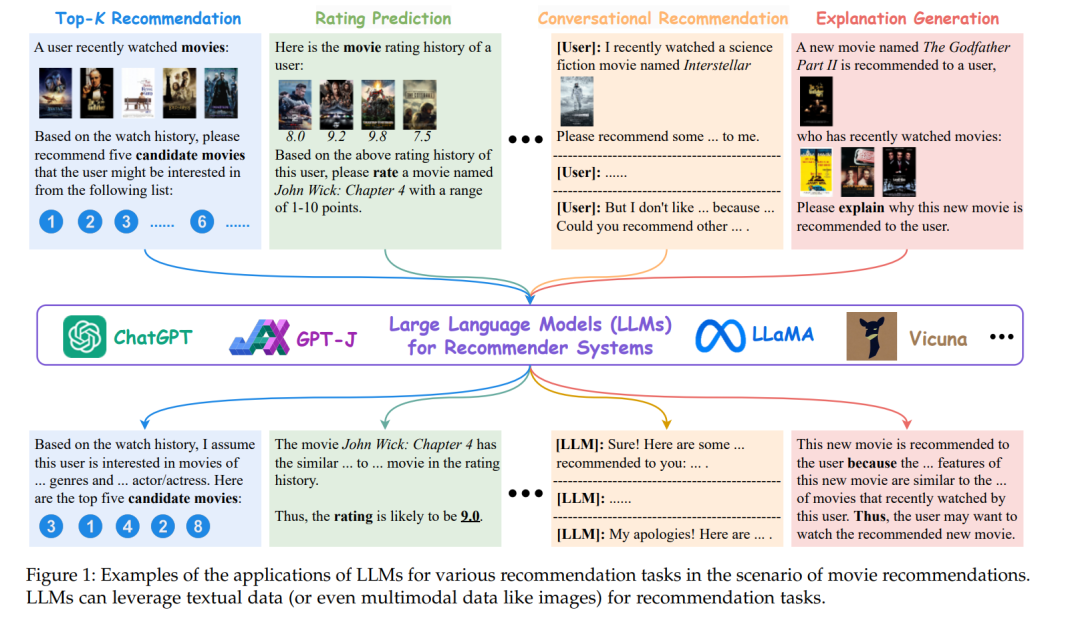
最近,已经开始尝试将LLMs作为下一代推荐系统的有前途的技术进行探索。例如,Chat-Rec [3] 提出了通过利用ChatGPT与用户进行对话并优化传统RecSys生成的电影推荐候选集来增强推荐准确性和可解释性的方法。张等人 [20] 利用T5作为基于LLMs的RecSys,使用户能够以自然语言形式传递其明确的偏好和意图作为RecSys输入,展示出比仅基于用户-物品交互更好的推荐性能。图1展示了将LLMs应用于各种电影推荐任务的一些示例,包括前k推荐、评分预测、对话式推荐和解释生成。鉴于其快速发展,有必要全面调研LLMs增强推荐系统的最新进展和挑战。因此,在本综述中,我们从预训练、微调和提示的范例出发,为推荐系统中的LLMs提供了全面的概述。
**本综述的剩余部分组织如下。**首先,在第2节中,我们回顾了有关RecSys和LLMs以及它们在其中的结合方面的相关工作。然后,在第3节中,我们阐述了两种利用LLMs来学习用户和物品表示的LLM增强型RecSys,分别是基于ID的RecSys和增强文本附加信息的RecSys。随后,在第4节和第5节分别总结了在预训练和微调范式以及提示范式中采用LLMs来推进RecSys的技术。最后,在第6节中,我们讨论了LLM增强推荐系统面临的一些挑战和潜在未来方向。与我们的调查同时进行,刘等人 [21] 回顾了适用于推荐系统的语言建模范式的训练策略和学习目标。吴等人 [22] 从辨别和生成的角度总结了LLMs在推荐系统中的应用。林等人 [23] 介绍了两个正交的观点:在推荐系统中如何以及如何适应LLMs。 深度表示学习用于基于LLMs的推荐系统
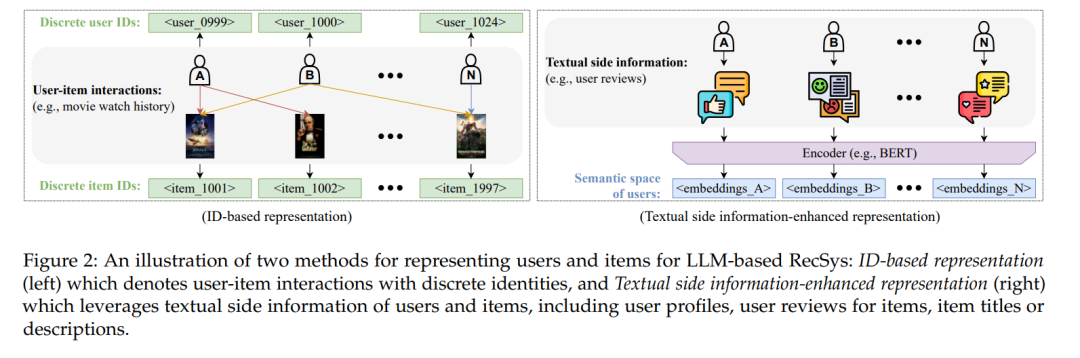
用户和物品是推荐系统的原子单位。为了表示推荐系统中的物品和用户,一种直接的方法是为每个物品或用户分配一个唯一的索引(即离散的ID)。为了捕捉用户对物品的偏好,基于ID的推荐系统被提出,以从用户-物品交互中学习用户和物品的表示。此外,由于关于用户和物品的文本附加信息提供了丰富的知识以理解用户的兴趣,因此发展了增强文本附加信息的推荐方法,以在端到端的训练方式中增强推荐系统中的用户和物品表示学习。在本节中,我们将介绍这两个利用语言模型在推荐系统中的类别。这两种类型的推荐系统如图2所示。
为推荐系统预训练和微调LLMs
一般来说,在开发和部署LLMs进行推荐任务时,有三种关键方法,即预训练、微调和提示。在本节中,我们首先介绍预训练和微调的范式,分别如图3和图4所示。具体来说,我们将重点关注LLMs用于推荐系统中的具体预训练任务以及用于下游推荐任务更好性能的微调策略。请注意,下面提到的工作已在表1和表2中进行了总结。


为推荐系统启用LLMs的提示策略
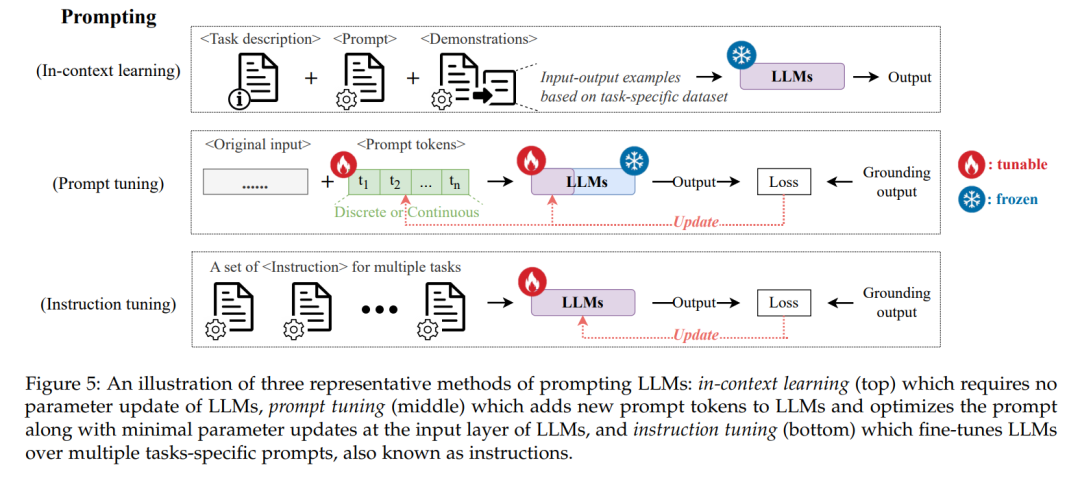
除了预训练和微调的范式之外,提示被视为将LLMs适应特定下游任务的最新范式,借助任务特定的提示。提示是指可以应用于LLMs输入的文本模板。例如,可以设计一个提示“关系和之间的关系是。”来部署LLMs用于关系抽取任务。提示使LLMs能够将不同的下游任务统一为语言生成任务,在预训练期间与其目标保持一致[86]。为了促进LLMs在推荐系统中的性能,越来越多地研究了类似于In-context Learning(ICL)和Chain-of-Thought(CoT)的提示技术,以手动设计适用于各种推荐任务的提示。此外,提示调整作为提示的一种补充技术,通过向LLMs添加提示令牌,然后基于任务特定的推荐数据集进行更新。最近,探索了将预训练和微调范式与提示相结合的指导调整技术[87],通过基于指令的提示对LLMs进行多个推荐任务的微调,从而增强了LLMs在未见推荐任务上的零-shot性能。图5比较了与LLMs的前述三种提示技术对应的代表性方法,从LLMs的输入形式和参数更新(即可调整或冻结)方面进行了比较。在本节中,我们将详细讨论提示、提示调整和指令调整技术,以提高LLMs在推荐任务上的性能。总之,表3根据前述三种技术对现有工作进行了分类,包括这些工作中考虑的具体推荐任务和LLMs的骨干。
结论
作为最先进的人工智能技术之一,LLMs在各种应用中取得了巨大成功,例如分子发现和金融领域,这要归功于它们在语言理解和生成方面的显著能力、强大的泛化和推理能力,以及对新任务和多样领域的快速适应能力。类似地,越来越多的努力已经投入到用LLMs改革推荐系统,以提供高质量和个性化的建议服务。鉴于推荐系统中这个研究课题的快速发展,迫切需要一个系统性的概述,全面总结现有的LLM增强推荐系统。为了填补这一空白,在本调查中,我们从预训练&微调和提示范式出发,为相关领域的研究人员和从业者提供深入的理解,提供了LLM增强推荐系统的全面概述。然而,目前关于LLMs在推荐系统中的研究仍处于早期阶段,需要更多系统和全面的LLMs在这个领域的研究。因此,我们还讨论了这个领域的一些潜在未来方向。


