摘要—近年来,生成模型在生成任务中的卓越表现激发了人们对其在决策过程中应用的浓厚兴趣。由于其处理复杂数据分布的能力和强大的模型能力,生成模型可以通过生成轨迹,有效地融入决策系统,引导智能体朝向高回报的状态-动作区域或中间子目标。本文全面回顾了生成模型在决策任务中的应用。我们对七种基础生成模型进行了分类:能量模型、生成对抗网络、变分自编码器、标准化流、扩散模型、生成流网络和自回归模型。关于它们的应用,我们将其功能分为三个主要角色:控制器、建模器和优化器,并讨论每个角色如何为决策提供贡献。此外,我们还探讨了这些模型在五个关键实际决策场景中的部署情况。最后,我们总结了当前方法的优缺点,并提出了三条推进下一代生成决策模型的关键方向:高性能算法、大规模通用决策模型以及自我进化与自适应模型。 关键词—生成模型、决策制定、生成决策制定
1 引言
生成模型已成为学术界和工业界的热门话题,主要由于它们能够生成大量高质量和多样性的合成数据。从早期的系统如 DALL-E [1](用于图像生成)和 GPT-3 [2](用于文本生成)到最近的进展,如 DALL-E3 [3]、ChatGPT 和 GPT-4 [4],生成模型在其输出的质量和规模上迅速发展。 内容生成旨在创造与训练样本相似的连贯材料,而决策制定则专注于生成能够实现最佳结果的行动序列。与内容生成不同,决策制定涉及复杂、动态的环境和长期的决策。因此,尽管生成模型在内容生成方面取得了成功,将它们应用于决策制定仍面临诸多挑战。这些挑战包括:1)如何通过与环境的交互来学习策略,而不仅仅是模仿专家行为;2)如何基于学习到的行为生成新策略,从策略学习过渡到策略生成;3)如何建立一个能够在各种环境中适应的稳健基础决策生成模型,且只需最少的调优工作;4)如何构建策略的多步推理和长期演化能力。这些挑战强调了生成模型不仅仅是生成数据的需要。
在实际应用中,决策制定通常被称为序列决策制定,其中决策者随着时间推移做出一系列观察,每个决策都会影响随后的选择。目标是识别一个策略,以优化期望的回报或最小化跨越序列行动的成本。经典算法,如动态规划(DP)和强化学习(RL),广泛应用于解决建模为马尔可夫决策过程(MDPs)的问题。这些方法通过基于观察到的回报和状态转移来更新策略,而不是生成新策略,来优化决策制定。尽管这些传统方法在许多应用中取得了成功,但它们通常依赖于试错或预定义的状态和转移,这限制了探索,并可能错过更好的解决方案。此外,它们需要大量的计算和优化,这在高维或大规模问题中可能不切实际。传统方法还需要在面对新环境时进行大规模的重新配置或再训练,从而降低了灵活性。
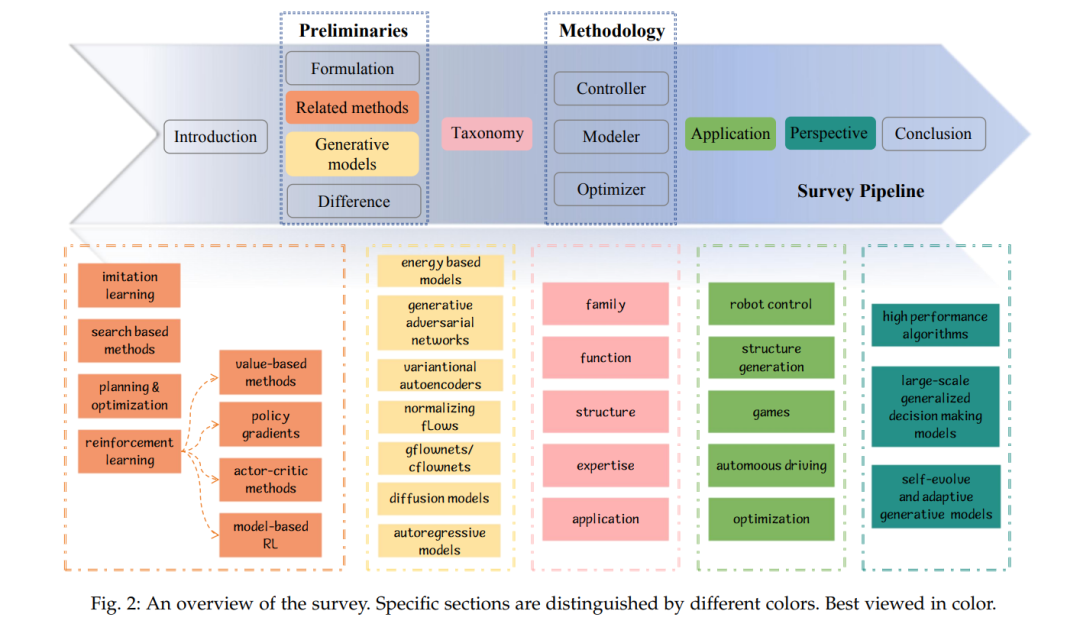
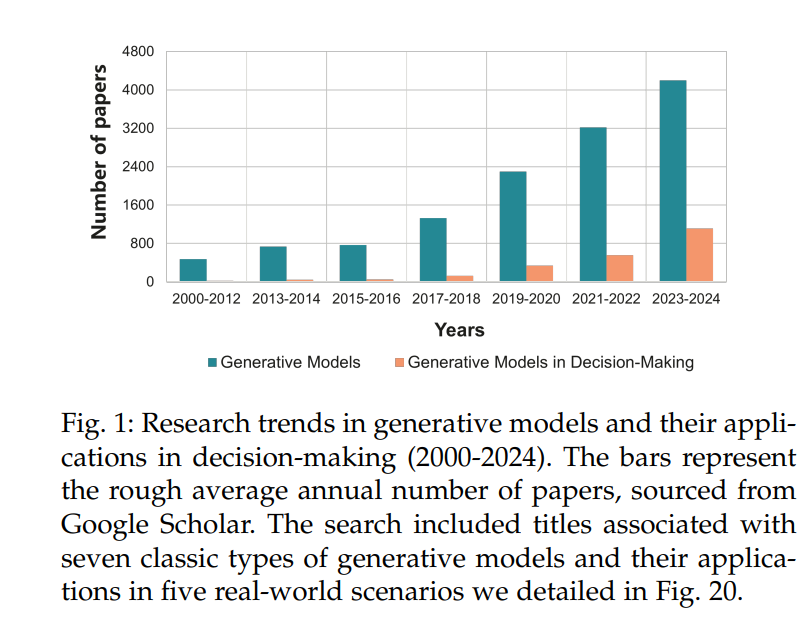
另一方面,生成模型被设计为对数据分布进行建模,而不仅仅是拟合标签。一旦训练完成,它们可以生成与原始数据相似的新样本,从而能够探索不同的场景和结果。这一能力使得在传统方法可能难以立即显现的情况下,发现新的策略成为可能。在复杂或标签不明确的数据场景中,生成模型提供了对可能决策路径的更深入理解,有时能引导出更符合高回报或期望目标的策略。然而,传统方法如优化或强化学习在决策空间较清晰、目标更直接的简单环境中仍然有效。选择这些方法之间的差异,取决于任务的复杂性和环境的特点。 认识到这些优势,近年来,开发新的生成模型并将其应用于决策制定的研究工作大幅增加。图 1 展示了生成模型及其在决策制定中的应用的研究趋势,进一步强调了这些方法在解决此类挑战中的重要性。然而,目前缺乏全面的综述,能够总结过去的工作并为新的研究方向铺平道路。这个空白促使我们撰写本文综述。该综述的三大贡献包括:1)提出了一个全面的分类法,用于分类当前的生成决策制定方法。我们识别了七种用于决策制定的生成模型,并将其功能分类为三个关键角色:控制器、建模器和优化器;2)我们回顾了生成模型在决策制定中的多样化实际应用,重点讨论了机器人控制、结构生成、游戏、自动驾驶和优化任务;3)最后,我们总结了现有工作的优缺点,并讨论了未来在决策制定任务中开发高性能生成模型的前景。 本文其余部分的组织结构如下(参见图 2 了解总体大纲):第二部分作为引言,介绍了序列决策制定的基本公式,并提供了所有研究方法的基础知识。具体而言,我们详细介绍了七种生成模型,并将它们与传统方法进行对比。第三部分提出了用于分类生成决策制定方法的分类法。第四部分根据介绍的分类法回顾并分析现有文献。第五部分展示了生成模型在决策制定中的实际应用。最后,第六部分讨论了生成模型在决策制定中的未来发展方向,第七部分总结了本文的整体内容。